所有知識體系文章,GitHub已收錄,歡迎老闆們前來Star!
GitHub地址: https://github.com/Ziphtracks/JavaLearningmanual
MySQL觸發器
一、什麼是觸發器
觸發器(trigger)是MySQL提供給程序員和數據分析員來保證數據完整性的一種方法,它是與表事件相關的特殊的存儲過程,它的執行不是由程序調用,也不是手工啟動,而是由事件來觸發,比如當對一個表進行操作(insert,delete, update)時就會激活它執行。簡單理解為:你執行一條sql語句,這條sql語句的執行會自動去觸發執行其他的sql語句。
二、觸發器的作用
- 可在寫入數據表前,強制檢驗或轉換數據。
- 觸發器發生錯誤時,異動的結果會被撤銷。
- 部分數據庫管理系統可以針對數據定義語言(DDL)使用觸發器,稱為DDL觸發器。
- 可依照特定的情況,替換異動的指令 (INSTEAD OF)。
三、觸發器創建的四要素
- 監視地點(table)
- 監視事件(insert、update、delete)
- 觸發時間(after、before)
- 觸發事件(insert、update、delete)
四、觸發器的使用語法
語法:
before/after: 觸發器是在增刪改之前執行,還是之後執行
delete/insert/update: 觸發器由哪些行為觸發(增、刪、改)
on 表名: 觸發器監視哪張表的(增、刪、改)操作
觸發SQL代碼塊: 執行觸發器包含的SQL語句
1CREATE TRIGGER 觸發器名
2BEFORE|AFTER DELETE|INSERT|UPDATE
3ON 表名 FOR EACH ROW
4BEGIN
5觸發SQL代碼塊;
6END;
注意: 觸發器也是存儲過程程序的一種,而觸發器內部的執行SQL語句是可以多行操作的,所以在MySQL的存儲過程程序中,要定義結束符。
如果MySQL存儲過程不了解的小夥伴,可以參考此文面向MySQL存儲過程編程,文章中詳細講解了MySQL存儲過程的優勢和語法等等,相信你會在其中得以收穫。
1# 設置MySQL執行結束標誌,默認為;
2delimiter //
五、觸發器的基本使用
5.1 基本使用步驟
首先,我先展示一下創建的兩張表,因為創建的表很簡單,這裏我沒有提供庫表操作的SQL命令。
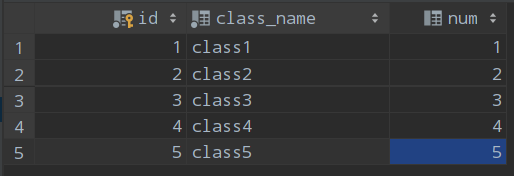
tb_class
image-20200611205404311
employee
image-20200611205435284
其次,創建了一個含有update操作的存儲過程
1delimiter //
2create procedure update_emp(in i int, in p int)
3begin
4 update employee set phone = p where id = i;
5end //
再創建一個觸發器
分析: 觸發器名稱為t1,觸發時間為after,監視動作為update,監視表為employee表。匯總一起解釋這個觸發器就是:創建一個觸發器名稱為t1的觸發器,觸發器監視employee表執行update(更新)操作后,就開始執行觸發器內部SQL語句update tb_class set num = num + 1 where id = 1;。
簡單來說就是一個監視一個表的增、刪、改操作並設置操作前後時間,在設置時間的範圍內對另外一個表進行其他操作。
如果你學到這裏還是一知半解,後面我會講解一個訂單與庫存的數據關係,到那時候你就會明白了!
1delimiter //
2# 創建觸發器,觸發器名稱為t1
3create trigger t1
4 # 觸發器執行在update操作之後
5 after update
6 # 監視employee表
7 on employee
8 for each row
9begin
10 # 觸發執行的SQL語句
11 update tb_class set num = num + 1 where id = 1;
12end //
最後調用函數,並查看、分析結果
1call update_emp(2, 110);
觸發器在此場景的作用分析
當employee表發生update操作時,觸發器就對tb_class表中的num值做修改。
執行結果發現,我們在使用函數將employee表中id為2員工的phone修改為110后,觸發器監視到employee表中發生了update更新操作,就執行了內部SQL語句,也就是將tb_class表中id為1的num值自增1。
image-20200611213411229 image-20200611213432459
5.2 查看和刪除已有的觸發器
查看已有觸發器: show triggers
刪除已有觸發器: drop trigger 觸發器名稱
5.3 for each row
這裏擴展,在oracle觸發器中,觸發器分為行觸發器和語句觸發器。也就是說,假設你監視一個修改操作,它修改了1000行代碼,在Oracle中觸發器會觸發1000次。
在oracle中,for each row如果不寫,無論update語句一次影響了多少行,都只執行一次觸發事件。
而MySQL中,不支持語句級觸發器,所以在MySQL中並不需要在意。
六、訂單與庫存關係場景
訂單與庫存的關係: 用戶下訂單,意味着創建該商品訂單,該商品訂單中的商品數量為1,庫存中的該商品數量-1。往往訂單表和庫存表中的數量是同時操作的,所以我們這裏可以用觸發器。
觸發器應用: 關於訂單表,下訂單肯定是涉及到insert插入數據數量的操作。我們可以創建一個監視訂單表insert操作后執行庫存表數量-1的觸發器來完成訂單與庫存表的同時修改。
創建表,並在表中添加幾條數據:
1create table goods(
2 gid int,
3 name varchar(20),
4 num smallint
5);
6create table ord(
7 oid int,
8 gid int,
9 much smallint
10);
11insert into goods values(1,'cat',40);
12insert into goods values(2,'dog',63);
13insert into goods values(3,'pig',87);
創建觸發器
1create trigger t1
2after
3insert
4on ord
5for each row
6begin
7 update goods set num = num - 1 where gid = 1;
8end$
該觸發器意為,用戶不管下什麼訂單,都會把商品編號為1的商品的庫存減去1。
七、觸發器中引用行變量
7.1 old和new對象語法
- 在觸發目標上執行insert操作後會有一個新行,如果在觸發事件中需要用到這個新行的變量,可以用new關鍵字表示
- 在觸發目標上執行delete操作後會有一箇舊行,如果在觸發事件中需要用到這箇舊行的變量,可以用old關鍵字表示
- 在觸發目標上執行update操作后原紀錄是舊行,新記錄是新行,可以使用new和old關鍵字來分別操作
| 觸發語句 |
old |
new |
| insert |
所有字段都為空 |
將要插入的數據 |
| update |
更新以前該行的值 |
更新后的值 |
| delete |
刪除以前該行的值 |
所有字段都為空 |
7.2 old和new對象應用
關於old和new對象的應用,我在這裏沒有展開演示。只是將第八章的綜合案例結合了old和new對象實現。綜合案例中詳細講解了MySQL觸發器的使用!
八、綜合案例
8.1 創建表、插入表數據
tb_class為幼兒園班級表,其中cid為唯一主鍵,cname為大、中、小班班級標準,stuNo為班級標準內的學生個數。插入大、中、小班標準,初始化兩名學生在大班。
tb_stu為幼兒園學生表,其中sid為唯一主鍵,sname為學生性名,cno為所在班級標準的外鍵。插入兩條數據並初始化這兩名學生在大班,因為我們在班級表中初始化了兩名學生在大班嘛,所以要做此操作。
1create table tb_class
2(
3 cid int auto_increment
4 primary key,
5 cname varchar(32) not null,
6 stuNo int not null
7);
8
9INSERT INTO temp.tb_class (cname, stuNo) VALUES ('大班', 2)
10INSERT INTO temp.tb_class (cname, stuNo) VALUES ('中班', 0)
11INSERT INTO temp.tb_class (cname, stuNo) VALUES ('小班', 0)
12
13create table tb_stu
14(
15 sid int auto_increment
16 primary key,
17 sname varchar(32) not null,
18 cno int not null
19);
20
21INSERT INTO temp.tb_stu (sname, cno) VALUES ('Ziph', 1)
22INSERT INTO temp.tb_stu (sname, cno) VALUES ('Join', 1)
8.2 添加學生案例
在此表結構中,如果一位新同學來到學校學習,意味着某一個班級中會多出一名學生。假設Marry同學去小班學習,其表結構的變化為:tb_stu表中添加一條Marry的記錄(注:cno = 3),tb_class表中小班記錄的stuNo = 0修改為stuNo = 1
先創建一個添加學生的存儲過程
1# 添加學生函數
2delimiter //
3# 創建存儲過程,傳入學生性名和班級參數
4create procedure add_stu(in in_sname varchar(32), in in_cno int)
5begin
6 # 插入記錄
7 insert into tb_stu (sname, cno) values (in_sname, in_cno);
8end //
創建觸發器
注意: 在更新學生數量SQL語句中,有一段cid = new.cno的SQL語句。這裏我解釋一下,new代表產生的新對象,將cid主鍵與添加Marry記錄后產生的新紀錄對象的cno外鍵關聯。(因為insert后產生的是新紀錄對象嘛,所以用new)
1# 觸發器
2# 創建名稱為t_add_stu的觸發器
3create trigger t_add_stu
4 # 設置在insert操作之後觸發
5 after
6 insert
7 # 監視tb_stu的insert操作
8 on tb_stu
9 for each row
10begin
11 # 更新學生數量(cid為tb_class表中主鍵,cno為tb_stu表中外鍵)
12 update tb_class set stuNo = stuNo + 1 where cid = new.cno;
13end //
聲明回結束符
1delimiter ;
插入Marry學生記錄到數據庫表中
1call add_stu('Marry', 3);
執行結果就是當插入Marry學生記錄的同時也修改了班級表中的小班學生數量。
8.3 刪除學生案例
刪除學生與添加學生十分相似,刪除學生相當於是添加學生的逆過程。如果以為學生退學了或者讀完了幼兒園離開學校了,就意味着班級中少了一位學生。假設Join同學讀完了大班結束了幼兒園階段的學習將要幼兒園去上小學,其表結構變化為:tb_stu刪除Join這條記錄(注:sid = 2),tb_class將修改Join所在大班班級級別的stuNo,即stuNo = stuNo – 1
先創建一個刪除學生的存儲過程
1# 刪除學生
2delimiter //
3create procedure delete_stu(in in_sid int)
4begin
5 delete from tb_stu where sid = in_sid;
6end //
創建觸發器
注意: 在更新學生數量的時候,書寫了此段SQL語句cid = OLD.cno。該語句使用old對象,意為Join學生的記錄沒有了,但是使用觸發器同步修改tb_class表中的大班學生數量還需要用到關聯Join學生所在記錄的外鍵cno,使用old來句點出來的cno就是刪除之前Join那一條學生記錄的cno。(如果我們用new,該記錄還存在嗎?該記錄的cno還存在嗎?答案是都不存在了!)
1# 觸發器
2# 創建觸發器名稱為t_delete_stu的觸發器
3create trigger t_delete_stu
4 # 設置在delete操作之後觸發
5 after
6 delete
7 # 監視tb_stu表的delete操作
8 on tb_stu
9 for each row
10begin
11 # 更新學生數量(cid為tb_class表中主鍵,cno為tb_stu表中外鍵)
12 update tb_class set stuNo = stuNo - 1 where cid = OLD.cno;
13end //
聲明回結束符
1delimiter ;
刪除Jion學生記錄
1call delete_stu(2);
執行結果為Join記錄在數據庫的表中消失了,而大班的學生數量也減掉了1。
8.4 刪除班級案例
因為我已經詳細講解了添加學生與刪除學生,所以刪除班級我就不再作過多的贅述了。那就直接說核心內容吧。刪除一個班級級別比如:刪除小班之前要把小班內的所有學生也被刪除了,因為兩個表是主外鍵關聯的。如果只刪除了小班,而沒有刪除小班內的所有學生,那麼原小班內的所有學生現在屬於哪個班級呢,就不知道了吧!所以要在刪除小班之前刪除小班內的所有學生。
1# 創建刪除班級的存儲過程
2delimiter //
3create procedure delete_class(in in_cid int)
4begin
5 delete from tb_class where cid = in_cid;
6end //
7
8# 創建觸發器名稱為t_delete_class的觸發器
9create trigger t_delete_class
10 # 作用在delete操作之前
11 before
12 delete
13 # 監視tb_class表中的delete操作
14 on tb_class
15 for each row
16begin
17 # 同時刪除所有該原班級cid的所有學生
18 delete from tb_stu where cno = OLD.cid;
19end //
20
21# 將結束符聲明為;
22delimiter ;
23
24# 刪除小班班級別
25call delete_class(3);
執行結果為既刪除了小班,又刪除小班內的所有學生。
8.5 觸發器衝突問題
觸發器衝突問題其實就是關聯問題。為什麼這麼說呢?就說以下剛才這三個案例中出現的觸發器衝突問題。
如果我們在寫觸發器的時候,將添加學生、刪除學生和刪除班級的觸發器都寫在一個查詢模板中。你會發現當你在刪除班級的時候,會報錯。显示如下信息:
image-20200612004546204
這是為什麼呢?
仔細想想,我們將在案例中有兩個是同一個表中的刪除觸發器。刪除班級的觸發器中定義的是刪除班級時觸發刪除學生,而刪除學生的觸發器中定義的是班級人數減一。你發現了沒,觸發器被連着觸發了。如下變化:
image-20200612005312835
我們通過刪除班級案例了解了,刪除班級之前需要把班級內所有學生刪除掉。正因為如此,我們在刪除班級之前已經把所有學生都刪除了,導致在刪除學生的時候觸發了班級人數減一的觸發器,該觸發器在執行過程中修改了已經被刪除班級的學生人數。這問題就出在這裏了,班級已經刪除了,怎麼修改一個本就沒有的班級內的人數呢?對吧!
解決觸發器衝突
為解決這個場景的觸發器衝突問題,我們只能取捨一個觸發器。於是,就通過命令刪除了刪除學生案例中使用的那個觸發器,刪除后刪除班級就可以成功執行觸發了!
1drop trigger t_delete_stu;
注意: 由於存在觸發器衝突問題,我們在實際開發中需要認真考量定義觸發器!
九、觸發器性能和使用分析(必讀)
各大論壇等等,相信在大家的文章中都不推薦使用觸發器,而是推薦使用存儲過程程序,這是為什麼呢?
首先,存儲過程程序分為存儲過程、儲存過程函數和觸發器。也就是說這三種都是存儲過程的使用都是存儲過程的表現形式。
如果場景在數據量和併發量都很大的情況下,使用觸發器、存儲過程再加上幾個事務等等,很容易出現死鎖。而且在使用觸發器的時候,也會出現衝突,出現問題時,我們需要追溯的代碼就需要從一個觸發器到另一個觸發器……從而影響開發效率。從性能上看,觸發器也是存儲過程程序的一種,它也並沒有展現出多少性能上的優勢。由於觸發器寫起來比較隱蔽,容易被開發人員忽略,而且隱式調用觸發器不易於排除依賴,對後期維護不是很友好!
所以在開發中,觸發器是很少用到的。那為什麼我還花時間大篇幅的講解MySQL觸發器呢?原因很簡單,是因為需要擴展自己的知識儲備。開發中的使用問題和是否被大家摒棄,不是你拒絕學習知識的理由。之所以存在就有它存在的道理,我們在學習的道路中不斷擴充自己的知識儲備即可。
假如有一天你的同事聊起觸發器,你也能和他們聊聊你對觸發器的見解是哈?如果你根據從未了解過此知識呢?那性質就不一樣了,相信大家都懂吧!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益