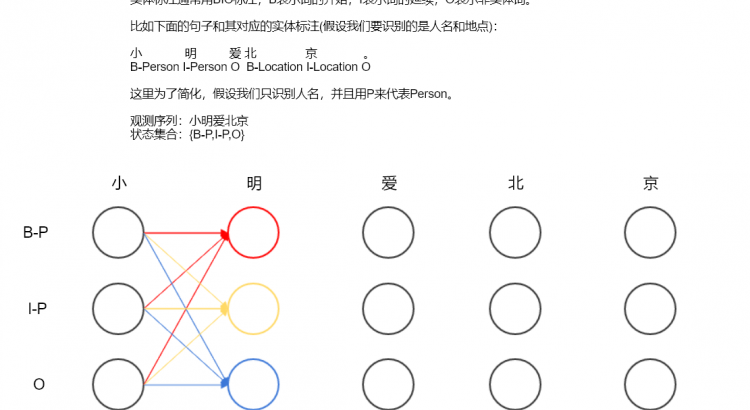
目錄
簡介
dom4j用於創建和解析XML文件,不是純粹的DOM或SAX,而是兩者的結合和改進,另外,dom4j支持Xpath來獲取節點。目前,由於其出色的性能和易用性,目前dom4j已經得到廣泛使用,例如Spring、Hibernate就是使用dom4j來解析xml配置。
注意,dom4j使用Xpath需要額外引入jaxen的包。
DOM、SAX、JAXP和DOM4J
其實,JDK已經帶有可以解析xml的api,如DOM、SAX、JAXP,但為什麼dom4j會更受歡迎呢?它們有什麼區別呢?在學習dom4j之前,需要先理解下DOM、SAX等概念,因為dom4j就是在此基礎上改進而來。
xerces解釋器
先介紹下xerces解釋器,下面介紹的SAX、DOM和JAXP都只是接口,而xerces解釋器就是它們的具體實現,在com.sun.org.apache.xerces.internal包。xerces被稱為性能最好的解釋器,除了xerces外,還有其他的第三方解釋器,如crimson。
SAX
JDK針對解析xml提供的接口,不是具體實現,在org.xml.sax包。SAX是基於事件處理,解析過程中根據當前的XML元素類型,調用用戶自己實現的回調方法,如:startDocument();,startElement()。下面以例子說明,通過SAX解析xml並打印節點名:
/*這裏解釋下四個的接口:
EntityResolver:需要實現resolveEntity方法。當解析xml需要引入外部數據源時觸發,通過這個方法可以重定向到本地數據源或進行其他操作。
DTDHandler:需要實現notationDecl和unparsedEntityDecl方法。當解析到"NOTATION", "ENTITY"或 "ENTITIES"時觸發。
ContentHandler:最常用的一個接口,需要實現startDocument、endDocument、startElement、endElement等方法。當解析到指定元素類型時觸發。
ErrorHandler:需要實現warning、error或fatalError方法。當解析出現異常時會觸發。
*/
@Test
public void test04() throws Exception {
//DefaultHandler實現了EntityResolver, DTDHandler, ContentHandler, ErrorHandler四個接口
DefaultHandler handler = new DefaultHandler() {
@Override
//當解析到Element時,觸發打印該節點名
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
System.out.println(qName);
}
};
//獲取解析器實例
XMLReader xr = XMLReaderFactory.createXMLReader();
//設置處理類
xr.setContentHandler(handler);
/*
* xr.setErrorHandler(handler);
* xr.setDTDHandler(handler);
* xr.setEntityResolver(handler);
*/
xr.parse(new InputSource("members.xml"));
}
因為SAX是基於事件處理的,不需要等到整個xml文件都解析完才執行我們的操作,所以效率較高。但SAX存在一個較大缺點,就是不能隨機訪問節點,因為SAX不會主動地去保存處理過的元素(優點就是內存佔用小、效率高),如果想要保存讀取的元素,開發人員先構建出一個xml樹形結構,再手動往裡面放入元素,非常麻煩(其實dom4j就是通過SAX來構建xml樹)。
DOM
JDK針對解析xml提供的接口,不是具體實現,在org.w3c.dom包。DOM採用了解析方式是一次性加載整個XML文檔,在內存中形成一個樹形的數據結構,開發人員可以隨機地操作元素。見以下例子:
@SuppressWarnings("restriction")
@Test
public void test05() throws Exception {
//獲得DOMParser對象
com.sun.org.apache.xerces.internal.parsers.DOMParser domParser = new com.sun.org.apache.xerces.internal.parsers.DOMParser();
//解析文件
domParser.parse(new InputSource("members.xml"));
//獲得Document對象
Document document=domParser.getDocument();
// 遍歷節點
printNodeList(document.getChildNodes());
}
通過DOM解析,我們可以獲取任意節點進行操作。但是,DOM有兩個缺點:
- 由於一次性加載整個XML文件到內存,當處理較大文件時,容易出現內存溢出。
- 節點的操作還是比較繁瑣。
以上兩點,dom4j都進行了相應優化。
JAXP
封裝了SAX、DOM兩種接口,它並沒有為JAVA解析XML提供任何新功能,只是對外提供更解耦、簡便操作的API。如下:
DOM解析器
@Test
public void test02() throws Exception {
// 獲得DocumentBuilder對象
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();
// 解析xml文件,獲得Document對象
Document document = builder.parse("members.xml");
// 遍歷節點
printNodeList(document.getChildNodes());
}
獲取SAX解析器
@Test
public void test03() throws Exception {
SAXParserFactory factory = SAXParserFactory.newInstance();
SAXParser saxParser = factory.newSAXParser();
saxParser.parse("members.xml", new DefaultHandler() {
@Override
public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException {
System.out.println(qName);
}
});
}
其實,JAXP並沒有很大程度提高DOM和SAX的易用性,更多地體現在獲取解析器時實現解耦。完全沒有解決SAX和DOM的缺點。
DOM4j
對比過dom4j和JAXP就會發現,JAXP本質上還是將SAX和DOM當成兩套API來看待,而dom4j就不是,它將SAX和DOM結合在一起使用,取長補短,並對原有的api進行了改造,在使用簡便性、性能、面向接口編程等方面都要優於JDK自帶的SAX和DOM。
以下通過使用例子和源碼分析將作出說明。
項目環境
工程環境
JDK:1.8
maven:3.6.1
IDE:sts4
dom4j:2.1.1
創建項目
項目類型Maven Project,打包方式jar。
引入依賴
注意:dom4j使用XPath,必須引入jaxen的jar包。
<!-- junit -->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<!-- dom4j的jar包 -->
<dependency>
<groupId>org.dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>2.1.1</version>
</dependency>
<!-- dom4j使用XPath需要的jar包 -->
<dependency>
<groupId>jaxen</groupId>
<artifactId>jaxen</artifactId>
<version>1.1.6</version>
</dependency>
<!-- 配置BeanUtils的包,這個我自定義工具類用的,如果只是簡單使用dom4j可以不引入 -->
<dependency>
<groupId>commons-beanutils</groupId>
<artifactId>commons-beanutils</artifactId>
<version>1.9.3</version>
</dependency>
使用例子–生成xml文件
本例子將分別使用dom4j和JDK的DOM接口生成xml文件(使用JDK的DOM接口時會使用JAXP的API)。
需求
構建xml樹,添加節點,並生成xml文件。格式如下:
<?xml version="1.0" encoding="UTF-8"?>
<members>
<students>
<student name="張三" location="河南" age="18"/>
<student name="李四" location="新疆" age="26"/>
<student name="王五" location="北京" age="20"/>
</students>
<teachers>
<teacher name="zzs" location="河南" age="18"/>
<teacher name="zzf" location="新疆" age="26"/>
<teacher name="lt" location="北京" age="20"/>
</teachers>
</members>
生成xml文件–使用w3c的DOM接口
主要步驟
-
通過JAXP的API獲得Document對象,這個對象可以看成xml的樹;
-
將對象轉化為節點,並添加在Document這棵樹上;
-
通過Transformer對象將樹輸出到文件中。
編寫測試類
路徑:test目錄下的cn.zzs.dom4j。
注意:因為使用的是w3c的DOM接口,所以節點對象導的是org.w3c.dom包,而不是org.dom4j包。
@Test
public void test02() throws Exception {
// 創建工廠對象
DocumentBuilderFactory documentBuilderFactory = DocumentBuilderFactory.newInstance();
// 創建DocumentBuilder對象
DocumentBuilder documentBuilder = documentBuilderFactory.newDocumentBuilder();
// 創建Document對象
Document document = documentBuilder.newDocument();
// 創建根節點
Element root = document.createElement("members");
document.appendChild(root);
// 添加一級節點
Element studentsElement = (Element)root.appendChild(document.createElement("students"));
Element teachersElement = (Element)root.appendChild(document.createElement("teachers"));
// 添加二級節點並設置屬性
Element studentElement1 = (Element)studentsElement.appendChild(document.createElement("student"));
studentElement1.setAttribute("name", "張三");
studentElement1.setAttribute("age", "18");
studentElement1.setAttribute("location", "河南");
Element studentElement2 = (Element)studentsElement.appendChild(document.createElement("student"));
studentElement2.setAttribute("name", "李四");
studentElement2.setAttribute("age", "26");
studentElement2.setAttribute("location", "新疆");
Element studentElement3 = (Element)studentsElement.appendChild(document.createElement("student"));
studentElement3.setAttribute("name", "王五");
studentElement3.setAttribute("age", "20");
studentElement3.setAttribute("location", "北京");
Element teacherElement1 = (Element)teachersElement.appendChild(document.createElement("teacher"));
teacherElement1.setAttribute("name", "zzs");
teacherElement1.setAttribute("age", "18");
teacherElement1.setAttribute("location", "河南");
Element teacherElement2 = (Element)teachersElement.appendChild(document.createElement("teacher"));
teacherElement2.setAttribute("name", "zzf");
teacherElement2.setAttribute("age", "26");
teacherElement2.setAttribute("location", "新疆");
Element teacherElement3 = (Element)teachersElement.appendChild(document.createElement("teacher"));
teacherElement3.setAttribute("name", "lt");
teacherElement3.setAttribute("age", "20");
teacherElement3.setAttribute("location", "北京");
// 獲取文件對象
File file = new File("members.xml");
if(!file.exists()) {
file.createNewFile();
}
// 獲取Transformer對象
TransformerFactory transformerFactory = TransformerFactory.newInstance();
Transformer transformer = transformerFactory.newTransformer();
// 設置編碼、美化格式
transformer.setOutputProperty(OutputKeys.ENCODING, "UTF-8");
transformer.setOutputProperty(OutputKeys.INDENT, "yes");
// 創建DOMSource對象
DOMSource domSource = new DOMSource(document);
// 將document寫出
transformer.transform(domSource, new StreamResult(new PrintWriter(new FileOutputStream(file))));
}
測試結果
此時,在項目路徑下會生成members.xml,文件內容如下,可以看到,使用w3c的DOM接口輸出的內容沒有縮進格式。
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<members>
<students>
<student age="18" location="河南" name="張三"/>
<student age="26" location="新疆" name="李四"/>
<student age="20" location="北京" name="王五"/>
</students>
<teachers>
<teacher age="18" location="河南" name="zzs"/>
<teacher age="26" location="新疆" name="zzf"/>
<teacher age="20" location="北京" name="lt"/>
</teachers>
</members>
生成xml文件–使用dom4j的DOM接口
主要步驟
-
通過DocumentHelper獲得Document對象,這個對象可以看成xml的樹;
-
將對象轉化為節點,並添加在Document這棵樹上;
-
通過XMLWriter對象將樹輸出到文件中。
編寫測試類
路徑:test目錄下的cn.zzs.dom4j。通過對比,可以看出,dom4j的API相比JDK的還是要方便很多。
注意:因為使用的是dom4j的DOM接口,所以節點對象導的是org.dom4j包,而不是org.w3c.dom包(dom4j一個很大的特點就是改造了w3c的DOM接口,極大地簡化了我們對節點的操作)。
@Test
public void test02() throws Exception {
// 創建Document對象
Document document = DocumentHelper.createDocument();
// 添加根節點
Element root = document.addElement("members");
// 添加一級節點
Element studentsElement = root.addElement("students");
Element teachersElement = root.addElement("teachers");
// 添加二級節點並設置屬性,dom4j改造了w3c的DOM接口,極大地簡化了我們對節點的操作
studentsElement.addElement("student").addAttribute("name", "張三").addAttribute("age", "18").addAttribute("location", "河南");
studentsElement.addElement("student").addAttribute("name", "李四").addAttribute("age", "26").addAttribute("location", "新疆");
studentsElement.addElement("student").addAttribute("name", "王五").addAttribute("age", "20").addAttribute("location", "北京");
teachersElement.addElement("teacher").addAttribute("name", "zzs").addAttribute("age", "18").addAttribute("location", "河南");
teachersElement.addElement("teacher").addAttribute("name", "zzf").addAttribute("age", "26").addAttribute("location", "新疆");
teachersElement.addElement("teacher").addAttribute("name", "lt").addAttribute("age", "20").addAttribute("location", "北京");
// 獲取文件對象
File file = new File("members.xml");
if(!file.exists()) {
file.createNewFile();
}
// 創建輸出格式,不設置的話不會有縮進效果
OutputFormat format = OutputFormat.createPrettyPrint();
format.setEncoding("UTF-8");
// 獲得XMLWriter
XMLWriter writer = new XMLWriter(new FileWriter(file), format);
// 打印Document
writer.write(document);
// 釋放資源
writer.close();
}
測試結果
此時,在項目路徑下會生成members.xml,文件內容如下,可以看出dom4j輸出文件會進行縮進處理,而JDK的不會:
<?xml version="1.0" encoding="UTF-8"?>
<members>
<students>
<student name="張三" age="18" location="河南"/>
<student name="李四" age="26" location="新疆"/>
<student name="王五" age="20" location="北京"/>
</students>
<teachers>
<teacher name="zzs" age="18" location="河南"/>
<teacher name="zzf" age="26" location="新疆"/>
<teacher name="lt" age="20" location="北京"/>
</teachers>
</members>
使用例子–解析xml文件
需求
- 解析xml:解析上面生成的xml文件,將學生和老師節點按以下格式遍歷打印出來(當然也可以再封裝成對象返回給調用者,這裏就不擴展了)。
student:name=張三,location=河南,age=18
student:name=李四,location=新疆,age=26
student:name=王五,location=北京,age=20
teacher:name=zzs,location=河南,age=18
teacher:name=zzf,location=新疆,age=26
teacher:name=lt,location=北京,age=20
dom4j結合XPath查找指定節點
主要步驟
-
通過SAXReader對象讀取和解析xml文件,獲得Document對象,即xml樹;
-
調用Node的方法遍歷打印xml樹的節點;
-
使用XPath查詢指定節點。
測試遍歷節點
考慮篇幅,這裏僅給出一種節點遍歷方式,項目源碼中還給出了其他的幾種。
/**
* 測試解析xml
*/
@Test
public void test03() throws Exception {
// 創建指定文件的File對象
File file = new File("members.xml");
// 創建SAXReader
SAXReader saxReader = new SAXReader();
// 將xml文件讀入成document
Document document = saxReader.read(file);
// 獲得根元素
Element root = document.getRootElement();
// 遞歸遍歷節點
list1(root);
}
/**
* 遞歸遍歷節點
*/
private void list1(Element parent) {
if(parent == null) {
return;
}
// 遍歷當前節點屬性並輸出
printAttr(parent);
// 遞歸打印子節點
Iterator<Element> iterator2 = parent.elementIterator();
while(iterator2.hasNext()) {
Element son = (Element)iterator2.next();
list1(son);
}
}
測試結果如下:
-------第一種遍歷方式:Iterator+遞歸--------
student:name=張三,location=河南,age=18
student:name=李四,location=新疆,age=26
student:name=王五,location=北京,age=20
teacher:name=zzs,location=河南,age=18
teacher:name=zzf,location=新疆,age=26
teacher:name=lt,location=北京,age=20
測試XPath獲取指定節點
@Test
public void test04() throws Exception {
// 創建指定文件的File對象
File file = new File("members.xml");
// 創建SAXReader
SAXReader saxReader = new SAXReader();
// 將xml文件讀入成document
Document document = saxReader.read(file);
// 使用xpath隨機獲取節點
List<Node> list = document.selectNodes("//members//students/student");
// List<Node> list = xmlParser.getDocument().selectSingleNode("students");
// 遍歷節點
Iterator<Node> iterator = list.iterator();
while(iterator.hasNext()) {
Element element = (Element)iterator.next();
printAttr(element);
}
}
測試結果如下:
student:age=18,location=河南,name=張三
student:age=26,location=新疆,name=李四
student:age=20,location=北京,name=王五
XPath語法
利用XPath獲取指定節點,平時用的比較多,這裏列舉下基本語法。
| 表達式 |
結果 |
| /members |
選取根節點下的所有members子節點 |
| //members |
選取根節點下的所有members節點 |
| //students/student[1] |
選取students下第一個student子節點 |
| //students/student[last()] |
選取students下的最後一個student子節點 |
| //students/student[position()<3] |
選取students下前兩個student子節點 |
| //student[@age] |
選取所有具有age屬性的student節點 |
| //student[@age=’18’] |
選取所有age屬性為18的student節點 |
| //students/* |
選取students下的所有節點 |
| //* |
選取文檔中所有節點 |
| //student[@*] |
選取所有具有屬性的節點 |
| //members/students\ |
//members/teachers |
源碼分析
本文會先介紹dom4j如何將xml元素抽象成具體的對象,再去分析dom4j解析xml文件的過程(注意,閱讀以下內容前需要了解和使用過JDK自帶的DOM和SAX)。
dom4j節點的類結構
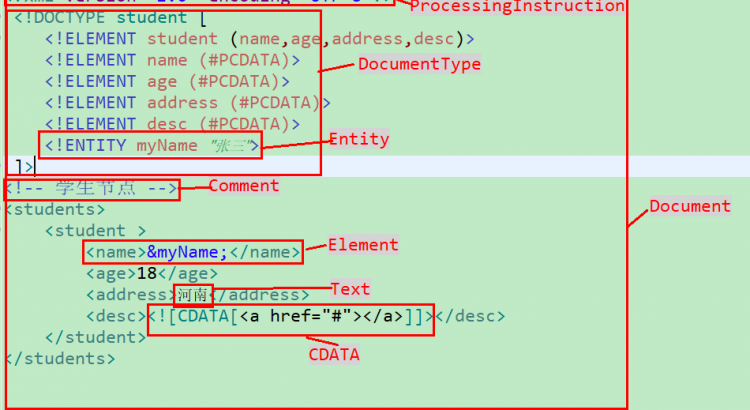
先來看下一個完整xml的元素組成,可以看出,一個xml文件包含了Document、Element、Comment、Attribute、DocumentType、Text等等。
DOM的思想就是將xml元素解析為具體對象,並構建樹形數據結構。基於此,w3c提供了xml元素的接口規範,dom4j基本借用了這套規範(如下圖),只是改造了接口的方法,使得我們操作時更加簡便。
SAXReader.read(File file)
通過使用例子可知,我們解析xml文件的入口是SAXReader對象的read方法,入參可以是文件路徑、url、字節流、字符流等,這裏以傳入文件路徑為例。
注意:考慮篇幅和可讀性,以下代碼經過刪減,僅保留所需部分。
public Document read(File file) throws DocumentException {
//不管是URI,path,character stream還是byte stream,都會包裝成InputSource對象
InputSource source = new InputSource(new FileInputStream(file));
if (this.encoding != null) {
source.setEncoding(this.encoding);
}
//下面這段代碼是為了設置systemId,當傳入URI且沒有指定字符流和字節流時,可以通過systemId去連接URL並解析
//如果一開始傳入了字符流或字節流,這個systemId就是可選的
String path = file.getAbsolutePath();
if (path != null) {
StringBuffer sb = new StringBuffer("file://");
if (!path.startsWith(File.separator)) {
sb.append("/");
}
path = path.replace('\\', '/');
sb.append(path);
source.setSystemId(sb.toString());
}
//這裏調用重載方法解析InputSource對象
return read(source);
}
SAXReader.read(InputSource in)
看到這個方法的代碼時,使用過JDK的SAX的朋友應該很熟悉,沒錯,dom4j也是採用事件處理的機制來解析xml。其實,只是這裏設置的SAXContentHandler已經實現好了相關的方法,這些方法共同完成一件事情:構建xml樹。明白這一點,應該就能理解dom4j是如何解決SAX和DOM的缺點了。
注意:考慮篇幅和可讀性,以下代碼經過刪減,僅保留所需部分。
public Document read(InputSource in) throws DocumentException {
// 這裡會調用JAXP接口獲取XMLReader實現類對象
XMLReader reader = getXMLReader();
reader = installXMLFilter(reader);
// 下面這些操作,是不是和使用JDK的SAX差不多,dom4j也是使用了事件處理機制。
// EntityResolver:通過實現resolveEntity方法,當解析xml需要引入外部數據源時觸發,可以重定向到本地數據源或進行其他操作。
EntityResolver thatEntityResolver = this.entityResolver;
if (thatEntityResolver == null) {
thatEntityResolver = createDefaultEntityResolver(in
.getSystemId());
this.entityResolver = thatEntityResolver;
}
reader.setEntityResolver(thatEntityResolver);
// 下面的SAXContentHandler繼承了DefaultHandler,即實現了EntityResolver, DTDHandler, ContentHandler, ErrorHandler等接口
// 其中最重要的是ContentHandler接口,通過實現startDocument、endDocument、startElement、endElement等方法,當dom4j解析xml文件到指定元素類型時,可以觸發我們自定義的方法。
// 當然,dom4j已經實現了ContentHandler的方法。具體實現的方法內容為:在解析xml時構建xml樹
SAXContentHandler contentHandler = createContentHandler(reader);
contentHandler.setEntityResolver(thatEntityResolver);
contentHandler.setInputSource(in);
boolean internal = isIncludeInternalDTDDeclarations();
boolean external = isIncludeExternalDTDDeclarations();
contentHandler.setIncludeInternalDTDDeclarations(internal);
contentHandler.setIncludeExternalDTDDeclarations(external);
contentHandler.setMergeAdjacentText(isMergeAdjacentText());
contentHandler.setStripWhitespaceText(isStripWhitespaceText());
contentHandler.setIgnoreComments(isIgnoreComments());
reader.setContentHandler(contentHandler);
configureReader(reader, contentHandler);
// 使用事件處理機制解析xml,處理過程會構建xml樹
reader.parse(in);
// 返回構建好的xml樹
return contentHandler.getDocument();
}
SAXContentHandler
通過上面的分析,可知SAXContentHandler是dom4j構建xml樹的關鍵。這裏看下它的幾個重要方法和屬性。
startDocument()
// xml樹
private Document document;
// 節點棧,棧頂存放當前解析節點(節點解析結束)、或當前解析節點的父節點(節點解析開始)
private ElementStack elementStack;
// 節點處理器,可以看成節點開始解析或結束解析的標誌
private ElementHandler elementHandler;
// 當前解析節點(節點解析結束)、或當前解析節點的父節點(節點解析開始)
private Element currentElement;
public void startDocument() throws SAXException {
document = null;
currentElement = null;
// 清空節點棧
elementStack.clear();
// 初始化節點處理器
if ((elementHandler != null)
&& (elementHandler instanceof DispatchHandler)) {
elementStack.setDispatchHandler((DispatchHandler) elementHandler);
}
namespaceStack.clear();
declaredNamespaceIndex = 0;
if (mergeAdjacentText && (textBuffer == null)) {
textBuffer = new StringBuffer();
}
textInTextBuffer = false;
}
startElement(String,String,String,Attributes)
public void startElement(String namespaceURI, String localName,
String qualifiedName, Attributes attributes) throws SAXException {
if (mergeAdjacentText && textInTextBuffer) {
completeCurrentTextNode();
}
QName qName = namespaceStack.getQName(namespaceURI, localName,
qualifiedName);
// 獲取當前解析節點的父節點
Branch branch = currentElement;
if (branch == null) {
branch = getDocument();
}
// 創建當前解析節點
Element element = branch.addElement(qName);
addDeclaredNamespaces(element);
// 添加節點屬性
addAttributes(element, attributes);
//將當前節點壓入節點棧
elementStack.pushElement(element);
currentElement = element;
entity = null; // fixes bug527062
//標記節點解析開始
if (elementHandler != null) {
elementHandler.onStart(elementStack);
}
}
endElement(String, String, String)
public void endElement(String namespaceURI, String localName, String qName)
throws SAXException {
if (mergeAdjacentText && textInTextBuffer) {
completeCurrentTextNode();
}
// 標記節點解析結束
if ((elementHandler != null) && (currentElement != null)) {
elementHandler.onEnd(elementStack);
}
// 當前解析節點從節點棧中彈出
elementStack.popElement();
// 指定為棧頂節點
currentElement = elementStack.peekElement();
}
endDocument()
public void endDocument() throws SAXException {
namespaceStack.clear();
// 清空節點棧
elementStack.clear();
currentElement = null;
textBuffer = null;
}
以上,dom4j的源碼分析基本已經分析完,其他具體細節後續再做補充。
參考以下資料:
本文為原創文章,轉載請附上原文出處鏈接:https://github.com/ZhangZiSheng001/dom4j-demo
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※平板收購,iphone手機收購,二手筆電回收,二手iphone收購-全台皆可收購
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益