這一趴裏面,我就來正式介紹一下CoffeeSQL的乾貨。
首先要給CoffeeSQL來個定位:最開始就是由於本人想要了解ORM框架內部的原理,所以就四處搜尋有關的博客與學習資料,就是在那個夏天,在博客園上看到了一位7tiny老哥的博客(https://www.cnblogs.com/7tiny/p/9575230.html),裏面基本上包含了我所想要了解的全套內容。幸得7tiny老哥的博客和代碼都寫的非常清晰,所以沒花多久時間就看完了源碼並洞悉其中奧妙,於是自己就有個想法:在7tiny的開源代碼的基礎上歸納自己的ORM框架。於是出於學習與自我使用的目的就開始了擴展功能的道路,到現在為止,自己已經在公司的一個項目中用上了,效果還不錯。在這裏也感謝7tiny老哥對我提出的一些問題及時的回復和指導,真心感謝。
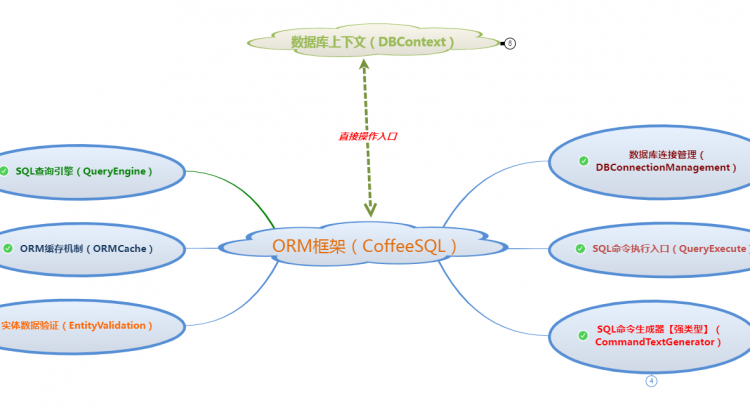
一、框架模塊介紹
根據CoffeeSQL的功能模塊組成來劃分,可以分為:數據庫連接管理、SQL命令執行入口、SQL命令生成器、SQL查詢引擎、ORM緩存機制、實體數據驗證 這六個部分,CoffeeSQL的操作入口與其他的ORM框架一樣,都是以數據庫上下文(DBContext)的方式進行操作。整體結構圖如下:
下面就大致地介紹一下每一個模塊的具體功能與實現的思路:
1、數據庫連接管理(DBConnectionManagement)
數據庫連接的管理實際上就是對數據庫連接字符串與其對應的數據庫連接對象的管理機制,它可以保證在進行一主多從的數據庫部署時ORM幫助我們自動地切換連接的數據庫,而且還支持 <最小使用>與 <輪詢>兩種數據庫連接切換策略。
2、SQL命令執行入口(QueryExecute)
QueryExecute是CoffeeSQL生成的所有sql語句執行的入口,執行sql語句並返回結果,貫穿整個CoffeeSQL最核心的功能就是映射sql查詢結果到實體,這裏採用的是構建表達式樹的技術,性能大大優於反射獲取實體的方式,具體的兩者速度對比的實驗在7tiny的博客中有詳細介紹,大家可以移步觀看(https://www.cnblogs.com/7tiny/p/9861166.html),在我的博客(https://www.cnblogs.com/MaMaNongNong/p/12173620.html)中我使用表達式樹的技術造了個簡練版的OOM框架。
這裏貼出核心代碼,方便查看:
1 /// <summary>
2 /// Auto Fill Adapter
3 /// => Fill DataRow to Entity
4 /// </summary>
5 public class EntityFillAdapter<Entity>
6 {
7 private static readonly Func<DataRow, Entity> funcCache = GetFactory();
8
9 public static Entity AutoFill(DataRow row)
10 {
11 return funcCache(row);
12 }
13
14 private static Func<DataRow, Entity> GetFactory()
15 {
16 #region get Info through Reflection
17 var entityType = typeof(Entity);
18 var rowType = typeof(DataRow);
19 var convertType = typeof(Convert);
20 var typeType = typeof(Type);
21 var columnCollectionType = typeof(DataColumnCollection);
22 var getTypeMethod = typeType.GetMethod("GetType", BindingFlags.Static | BindingFlags.Public, null, new[] { typeof(string) }, null);
23 var changeTypeMethod = convertType.GetMethod("ChangeType", BindingFlags.Static | BindingFlags.Public, null, new[] { typeof(object), typeof(Type) }, null);
24 var containsMethod = columnCollectionType.GetMethod("Contains");
25 var rowIndexerGetMethod = rowType.GetMethod("get_Item", BindingFlags.Instance | BindingFlags.Public, null, new[] { typeof(string) }, new[] { new ParameterModifier(1) });
26 var columnCollectionIndexerGetMethod = columnCollectionType.GetMethod("get_Item", BindingFlags.Instance | BindingFlags.Public, null, new[] { typeof(int) }, new[] { new ParameterModifier(1) });
27 var entityIndexerSetMethod = entityType.GetMethod("set_Item", BindingFlags.Instance | BindingFlags.NonPublic, null, new[] { typeof(string), typeof(object) }, null);
28 var properties = entityType.GetProperties(BindingFlags.Instance | BindingFlags.Public);
29 #endregion
30
31 #region some Expression class that can be repeat used
32 //DataRow row
33 var rowDeclare = Expression.Parameter(rowType, "row");
34 //Student entity
35 var entityDeclare = Expression.Parameter(entityType, "entity");
36 //Type propertyType
37 var propertyTypeDeclare = Expression.Parameter(typeof(Type), "propertyType");
38 //new Student()
39 var newEntityExpression = Expression.New(entityType);
40 //row == null
41 var rowEqualnullExpression = Expression.Equal(rowDeclare, Expression.Constant(null));
42 //row.Table.Columns
43 var rowTableColumns = Expression.Property(Expression.Property(rowDeclare, "Table"), "Columns");
44 //int loopIndex
45 var loopIndexDeclare = Expression.Parameter(typeof(int), "loopIndex");
46 //row.Table.Columns[loopIndex].ColumnName
47 var columnNameExpression = Expression.Property(Expression.Call(rowTableColumns, columnCollectionIndexerGetMethod, loopIndexDeclare), "ColumnName");
48 //break;
49 LabelTarget labelBreak = Expression.Label();
50 //default(Student)
51 var defaultEntityValue = Expression.Default(entityType);
52 #endregion
53
54 var setRowNotNullBlockExpressions = new List<Expression>();
55
56 #region entity = new Student();loopIndex = 0;
57 setRowNotNullBlockExpressions.Add(Expression.Assign(entityDeclare, newEntityExpression));
58 setRowNotNullBlockExpressions.Add(Expression.Assign(loopIndexDeclare, Expression.Constant(0)));
59
60 #endregion
61
62 #region loop Fill DataRow's field to Entity Indexer
63 /*
64 * while (true)
65 * {
66 * if (loopIndex < row.Table.Columns.Count)
67 * {
68 * entity[row.Table.Columns[loopIndex].ColumnName] = row[row.Table.Columns[loopIndex].ColumnName];
69 * loopIndex++;
70 * }
71 * else break;
72 * }
73 */
74
75 setRowNotNullBlockExpressions.Add(
76
77 Expression.Loop(
78 Expression.IfThenElse(
79 Expression.LessThan(loopIndexDeclare, Expression.Property(rowTableColumns, "Count")),
80 Expression.Block(
81 Expression.Call(entityDeclare, entityIndexerSetMethod, columnNameExpression, Expression.Call(rowDeclare, rowIndexerGetMethod, columnNameExpression)),
82 Expression.PostIncrementAssign(loopIndexDeclare)
83 ),
84 Expression.Break(labelBreak)
85 ),
86 labelBreak
87 )
88 );
89 #endregion
90
91 #region assign for Entity property
92 foreach (var propertyInfo in properties)
93 {
94 var columnAttr = propertyInfo.GetCustomAttribute(typeof(ColumnAttribute), true) as ColumnAttribute;
95
96 // no column , no translation
97 if (null == columnAttr) continue;
98
99 if (propertyInfo.CanWrite)
100 {
101 var columnName = Expression.Constant(columnAttr.GetName(propertyInfo.Name), typeof(string));
102
103 //entity.Id
104 var propertyExpression = Expression.Property(entityDeclare, propertyInfo);
105 //row["Id"]
106 var value = Expression.Call(rowDeclare, rowIndexerGetMethod, columnName);
107 //default(string)
108 var defaultValue = Expression.Default(propertyInfo.PropertyType);
109 //row.Table.Columns.Contains("Id")
110 var checkIfContainsColumn = Expression.Call(rowTableColumns, containsMethod, columnName);
111 //!row["Id"].Equals(DBNull.Value)
112 var checkDBNull = Expression.NotEqual(value, Expression.Constant(System.DBNull.Value));
113
114 var propertyTypeName = Expression.Constant(propertyInfo.PropertyType.ToString(), typeof(string));
115
116 /*
117 * if (row.Table.Columns.Contains("Id") && !row["Id"].Equals(DBNull.Value))
118 * {
119 * propertyType = Type.GetType("System.String");
120 * entity.Id = (string)Convert.ChangeType(row["Id"], propertyType);
121 * }
122 * else
123 * entity.Id = default(string);
124 */
125 setRowNotNullBlockExpressions.Add(
126
127 Expression.IfThenElse(
128 Expression.AndAlso(checkIfContainsColumn, checkDBNull),
129 Expression.Block(
130 Expression.Assign(propertyTypeDeclare, Expression.Call(getTypeMethod, propertyTypeName)),
131 Expression.Assign(propertyExpression, Expression.Convert(Expression.Call(changeTypeMethod, value, propertyTypeDeclare), propertyInfo.PropertyType))
132 ),
133 Expression.Assign(propertyExpression, defaultValue)
134 )
135 );
136 }
137 }
138
139 #endregion
140
141 var checkIfRowIsNull = Expression.IfThenElse(
142 rowEqualnullExpression,
143 Expression.Assign(entityDeclare, defaultEntityValue),
144 Expression.Block(setRowNotNullBlockExpressions)
145 );
146
147 var body = Expression.Block(
148
149 new[] { entityDeclare, loopIndexDeclare, propertyTypeDeclare },
150 checkIfRowIsNull,
151 entityDeclare //return Student;
152 );
153
154 return Expression.Lambda<Func<DataRow, Entity>>(body, rowDeclare).Compile();
155 }
156 }
157
158 #region
159 //public class Student : EntityDesign.EntityBase
160 //{
161 // [Column]
162 // public string Id { get; set; }
163
164 // [Column("StudentName")]
165 // public string Name { get; set; }
166 //}
167 ////this is the template of "GetFactory()" created.
168 //public static Student StudentFillAdapter(DataRow row)
169 //{
170 // Student entity;
171 // int loopIndex;
172 // Type propertyType;
173
174 // if (row == null)
175 // entity = default(Student);
176 // else
177 // {
178 // entity = new Student();
179 // loopIndex = 0;
180
181 // while (true)
182 // {
183 // if (loopIndex < row.Table.Columns.Count)
184 // {
185 // entity[row.Table.Columns[loopIndex].ColumnName] = row[row.Table.Columns[loopIndex].ColumnName];
186 // loopIndex++;
187 // }
188 // else break;
189 // }
190
191 // if (row.Table.Columns.Contains("Id") && !row["Id"].Equals(DBNull.Value))
192 // {
193 // propertyType = Type.GetType("System.String");
194 // entity.Id = (string)Convert.ChangeType(row["Id"], propertyType);
195 // }
196 // else
197 // entity.Id = default(string);
198
199 // if (row.Table.Columns.Contains("StudentName") && !row["StudentName"].Equals(DBNull.Value))
200 // {
201 // propertyType = Type.GetType("System.String");
202 // entity.Name = (string)Convert.ChangeType(row["StudentName"], propertyType);
203 // }
204 // else
205 // entity.Name = default(string);
206 // }
207
208 // return entity;
209 //}
210 #endregion
EntityFillAdapter(表達式樹技術)
3、SQL查詢引擎(QueryEngine)
SQL查詢引擎的功能主要就是以函數的形式來構建查詢SQL的結構。將sql語句使用高級語言的函數來進行構建能大大減輕程序員必須一絲不苟編寫sql語句的壓力。特別是在使用強類型查詢引擎時以Lambda表達式的方式編寫程序,相當舒適的體驗;對於稍微複雜的sql,建議使用弱類型查詢引擎來構建sql查詢語句,同時也提供方便的分頁功能,用法與Dapper類似;再複雜一點的數據庫查詢邏輯可能你就要考慮使用存儲過程查詢引擎了,總之,有了這三個查詢引擎,所有的查詢需求都能滿足了。最後一個是update的執行引擎,它被用來構建update的語句。
4、實體數據驗證(EntityValidation)
實體數據驗證是完全獨立的一部分,主要用來檢驗實體類中字段值的合法性,相當於在高級語言層面對即將持久化到數據庫表中的數據進行預先的字段合法性校驗,避免在持久化過程中發生不必要的字段格式不合法的錯誤。
5、ORM緩存機制(ORMCache)
這裏的ORM緩存主要分為兩級緩存,一級緩存為以sql語句為緩存鍵的緩存,緩存的內容就是當前執行的sql語句的執行結果;而二級緩存則是以表名為緩存鍵的表緩存,就是會把一整個表的數據全部存入緩存中,所以表緩存最適合那些數據量不大且查詢頻繁的表。
6、SQL命令生成器【強類型】(CommandTextGenerator)
在使用諸如強類型查詢引擎、Update執行引擎等進行了強類型的SQL語句構造后,相應的sql構造信息都要通過SQL命令生成器來生成最終可由數據庫執行的sql語句。SQL命令生成器扮演的就是類似於翻譯官的角色,將高級語言中的語句轉化為數據庫中的sql語句。在實際的應用場景中還可以根據不同的數據庫類型將SQL命令生成器擴展成諸如Mysql-SQL命令生成器或者Oracle-SQL命令生成器以符合不同類型數據庫的不同sql語法。
7、數據庫上下文(DBContext)
作為整個CoffeeSQL的操作入口,DBContext類涵蓋了各種配置參数字段與增刪改查的API調用函數。其中在事務處理中,由於寫操作都是通過對主庫的操作,所以在事務處理中是以主庫作為事務處理的對象。
二、使用方式
下載CoffeeSql源碼進行編譯,你會得到 CoffeeSql.Core.dll、CoffeeSql.Oracle.dll、CoffeeSql.Mysql.dll 三個dll文件,其中CoffeeSql.Core.dll為必選,然後根據你的數據庫類型選擇是CoffeeSql.Oracle.dll或者CoffeeSql.Mysql.dll,目前還只支持這兩種數據庫,後續會支持更多數據庫。
三、展望
路漫漫其修遠兮,吾將上下而求索,對比市面上火熱的ORM框架,CoffeeSQL還是缺少了一些實用的功能,對這個ORM框架的展望中我會考慮以下一些功能:
1、CodeFirst、DbFirst功能的支持,可以快捷方便地進行實體類與數據庫建表sql的生成;
2、批量插入操作的實現,可以提高批量插入數據的性能;
3、對多表聯合查詢的lambda語法支持;
介紹的再多都不如讀一遍源碼來的實在,有想深入了解orm原理的小夥伴可以閱讀一下源碼,真的SO EASY!
源碼地址:https://gitee.com/xiaosen123/CoffeeSqlORM
本文為作者原創,轉載請註明出處:https://www.cnblogs.com/MaMaNongNong/p/12896787.html
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計最專業,超強功能平台可客製化
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※回頭車貨運收費標準
※推薦評價好的iphone維修中心
※教你寫出一流的銷售文案?
※台中搬家公司教你幾個打包小技巧,輕鬆整理裝箱!
※台中搬家公司費用怎麼算?