前言
我在看SOFAJRaft的源碼的時候看到了使用了對象池的技術,看了一下感覺要吃透的話還是要新開一篇文章來講,內容也比較充實,大家也可以學到之後運用到實際的項目中去。
這裏我使用RecyclableByteBufferList來作為講解的例子:
RecyclableByteBufferList
public final class RecyclableByteBufferList extends ArrayList<ByteBuffer> implements Recyclable {
private transient final Recyclers.Handle handle;
private static final Recyclers<RecyclableByteBufferList> recyclers = new Recyclers<RecyclableByteBufferList>(512) {
@Override
protected RecyclableByteBufferList newObject(final Handle handle) {
return new RecyclableByteBufferList(
handle);
}
};
//獲取一個RecyclableByteBufferList實例
public static RecyclableByteBufferList newInstance(final int minCapacity) {
final RecyclableByteBufferList ret = recyclers.get();
//容量不夠的話,進行擴容
ret.ensureCapacity(minCapacity);
return ret;
}
//回收RecyclableByteBufferList對象
@Override
public boolean recycle() {
clear();
this.capacity = 0;
return recyclers.recycle(this, handle);
}
}我在上面將RecyclableByteBufferList獲取對象的方法和回收對象的方法給列舉出來了,獲取實例的時候會通過recyclers的get方法去獲取,回收對象的時候會去調用list的clear方法清空list裏面的內容之後再去調用recyclers的recycle方法進行回收。
如果recyclers裏面沒有對象可以獲取,那麼會調用newObject方法創建一個對象,然後將handle對象傳入構造器中進行實例化。
對象池Recyclers
數據結構
- 每一個 Recyclers 對象包含一個
ThreadLocal<Stack<T>> threadLocal實例;
每一個線程包含一個 Stack 對象,該 Stack 對象包含一個 DefaultHandle[],而 DefaultHandle 中有一個屬性 T value,用於存儲真實對象。也就是說,每一個被回收的對象都會被包裝成一個 DefaultHandle 對象 - 每一個 Recyclers 對象包含一個
ThreadLocal<Map<Stack<?>, WeakOrderQueue>> delayedRecycled實例;
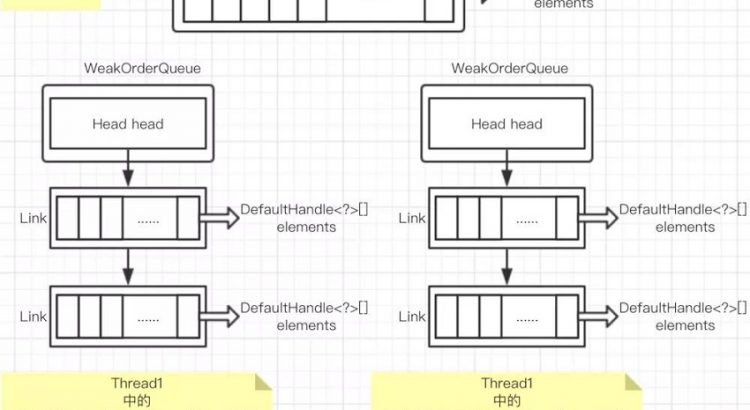
每一個線程對象包含一個 Map<Stack<?>, WeakOrderQueue>,存儲着為其他線程創建的 WeakOrderQueue 對象,WeakOrderQueue 對象中存儲一個以 Head 為首的 Link 數組,每個 Link 對象中存儲一個 DefaultHandle[] 數組,用於存放回收對象。
假設線程A創建的對象
- 線程A回收RecyclableByteBufferList時,直接將RecyclableByteBufferList的DefaultHandle 對象壓入 Stack 的 DefaultHandle[] 中;
- 線程B回收RecyclableByteBufferList時,會首先從其 Map<Stack<?>, WeakOrderQueue> 對象中獲取 key=線程A的Stack 對象的 WeakOrderQueue,然後直接將RecyclableByteBufferList的DefaultHandle 對象(內部包含RecyclableByteBufferList對象)壓入該 WeakOrderQueue 中的 Link 鏈表中的尾部 Link 的 DefaultHandle[]中,同時,這個 WeakOrderQueue 會與線程 A 的 Stack 中的 head 屬性進行關聯,用於後續對象的 pop 操作;
- 當線程 A 從對象池獲取對象時,如果線程 A 的 Stack 中有對象,則直接彈出;如果沒有對象,則先從其 head 屬性所指向的 WeakorderQueue 開始遍歷 queue 鏈表,將 RecyclableByteBufferList 對象從其他線程的 WeakOrderQueue 中轉移到線程 A 的 Stack 中(一次 pop 操作只轉移一個包含了元素的 Link),再彈出。
Recyclers靜態代碼塊
private static final int DEFAULT_INITIAL_MAX_CAPACITY_PER_THREAD = 4 * 1024; // Use 4k instances as default.
private static final int DEFAULT_MAX_CAPACITY_PER_THREAD;
private static final int INITIAL_CAPACITY;
static {
// 每個線程的最大對象池容量
int maxCapacityPerThread = SystemPropertyUtil.getInt("jraft.recyclers.maxCapacityPerThread", DEFAULT_INITIAL_MAX_CAPACITY_PER_THREAD);
if (maxCapacityPerThread < 0) {
maxCapacityPerThread = DEFAULT_INITIAL_MAX_CAPACITY_PER_THREAD;
}
DEFAULT_MAX_CAPACITY_PER_THREAD = maxCapacityPerThread;
if (LOG.isDebugEnabled()) {
if (DEFAULT_MAX_CAPACITY_PER_THREAD == 0) {
LOG.debug("-Djraft.recyclers.maxCapacityPerThread: disabled");
} else {
LOG.debug("-Djraft.recyclers.maxCapacityPerThread: {}", DEFAULT_MAX_CAPACITY_PER_THREAD);
}
}
// 設置初始化容量信息
INITIAL_CAPACITY = Math.min(DEFAULT_MAX_CAPACITY_PER_THREAD, 256);
}
public static final Handle NOOP_HANDLE = new Handle() {};Recyclers會在靜態代碼塊中做一些對象池容量初始化的工作,初始化了最大對象池容量和初始化容量信息。
從對象池中獲取對象
Recyclers#get
// 線程變量,保存每個線程的對象池信息,通過 ThreadLocal 的使用,避免了不同線程之間的競爭情況
private final ThreadLocal<Stack<T>> threadLocal = new ThreadLocal<Stack<T>>() {
@Override
protected Stack<T> initialValue() {
return new Stack<>(Recyclers.this, Thread.currentThread(), maxCapacityPerThread);
}
};
public final T get() {
if (maxCapacityPerThread == 0) {
return newObject(NOOP_HANDLE);
}
//從threadLocal中獲取一個棧對象
Stack<T> stack = threadLocal.get();
//拿出棧頂元素
DefaultHandle handle = stack.pop();
//如果棧裏面沒有元素,那麼就實例化一個
if (handle == null) {
handle = stack.newHandle();
handle.value = newObject(handle);
}
return (T) handle.value;
}Get方法會從threadLocal中去獲取數據,如果獲取不到,那麼會初始化一個Stack,並傳入當前Recyclers實例,當前線程,與最大容量。然後從stack中pop拿出棧頂元素,如果獲取的元素為空,那麼直接調用newHandle新建一個DefaultHandle實例,並調用Recyclers實現類的newObject獲取實現類的實例。也就是說DefaultHandle是用來封裝真正的對象的實例。
從stack中申請一個對象
Stack(Recyclers<T> parent, Thread thread, int maxCapacity) {
this.parent = parent;
this.thread = thread;
this.maxCapacity = maxCapacity;
elements = new DefaultHandle[Math.min(INITIAL_CAPACITY, maxCapacity)];
}
DefaultHandle pop() {
int size = this.size;
if (size == 0) {
if (!scavenge()) {
return null;
}
size = this.size;
}
//size表示整個stack中的大小
size--;
//獲取最後一個元素
DefaultHandle ret = elements[size];
if (ret.lastRecycledId != ret.recycleId) {
throw new IllegalStateException("recycled multiple times");
}
// 清空回收信息,以便判斷是否重複回收
ret.recycleId = 0;
ret.lastRecycledId = 0;
this.size = size;
return ret;
}獲取對象的邏輯也比較簡單,當 Stack 中的 DefaultHandle[] 的 size 為 0 時,需要從其他線程的 WeakOrderQueue 中轉移數據到 Stack 中的 DefaultHandle[],即 scavenge方法,該方法下面再聊。當 Stack 中的 DefaultHandle[] 中最終有了數據時,直接獲取最後一個元素
對象池回收對象
我們再來看看RecyclableByteBufferList是怎麼回收對象的。
RecyclableByteBufferList#recycle
public boolean recycle() {
clear();
this.capacity = 0;
return recyclers.recycle(this, handle);
}RecyclableByteBufferList回收對象的時候首先會調用clear方法清空屬性,然後調用recyclers的recycle方法進行對象回收。
Recyclers#recycle
public final boolean recycle(T o, Handle handle) {
if (handle == NOOP_HANDLE) {
return false;
}
DefaultHandle h = (DefaultHandle) handle;
//stack在實例化的時候會在構造器中傳入一個Recyclers作為parent
//所以這裡是校驗一下,如果不是當前線程的, 直接不回收了
if (h.stack.parent != this) {
return false;
}
if (o != h.value) {
throw new IllegalArgumentException("o does not belong to handle");
}
h.recycle();
return true;
}這裡會接着調用DefaultHandle的recycle方法進行回收
DefaultHandle
static final class DefaultHandle implements Handle {
//在WeakOrderQueue的add方法中會設置成ID
//在push方法中設置成為OWN_THREAD_ID
//在pop方法中設置為0
private int lastRecycledId;
//只有在push方法中才會設置OWN_THREAD_ID
//在pop方法中設置為0
private int recycleId;
//當前的DefaultHandle對象所屬的Stack
private Stack<?> stack;
private Object value;
DefaultHandle(Stack<?> stack) {
this.stack = stack;
}
public void recycle() {
Thread thread = Thread.currentThread();
//如果當前線程正好等於stack所對應的線程,那麼直接push進去
if (thread == stack.thread) {
stack.push(this);
return;
}
// we don't want to have a ref to the queue as the value in our weak map
// so we null it out; to ensure there are no races with restoring it later
// we impose a memory ordering here (no-op on x86)
// 如果不是當前線程,則需要延遲回收,獲取當前線程存儲的延遲回收WeakHashMap
Map<Stack<?>, WeakOrderQueue> delayedRecycled = Recyclers.delayedRecycled.get();
// 當前 handler 所在的 stack 是否已經在延遲回收的任務隊列中
// 並且 WeakOrderQueue是一個多線程間可以共享的Queue
WeakOrderQueue queue = delayedRecycled.get(stack);
if (queue == null) {
delayedRecycled.put(stack, queue = new WeakOrderQueue(stack, thread));
}
queue.add(this);
}
}DefaultHandle在實例化的時候會傳入一個stack實例,代表當前實例是屬於這個stack的。
所以在調用recycle方法的時候,會判斷一下,當前的線程是不是stack所屬的線程,如果是那麼直接push到stack裏面就好了,不是則調用延遲隊列delayedRecycled;
從delayedRecycled隊列中獲取Map<Stack<?>, WeakOrderQueue> delayedRecycled ,根據stack作為key來獲取WeakOrderQueue,然後將當前的DefaultHandle實例放入到WeakOrderQueue中。
同線程回收對象
Stack#push
void push(DefaultHandle item) {
// (item.recycleId | item.lastRecycleId) != 0 等價於 item.recycleId!=0 && item.lastRecycleId!=0
// 當item開始創建時item.recycleId==0 && item.lastRecycleId==0
// 當item被recycle時,item.recycleId==x,item.lastRecycleId==y 進行賦值
// 當item被pop之後, item.recycleId = item.lastRecycleId = 0
// 所以當item.recycleId 和 item.lastRecycleId 任何一個不為0,則表示回收過
if ((item.recycleId | item.lastRecycledId) != 0) {
throw new IllegalStateException("recycled already");
}
// 設置對象的回收id為線程id信息,標記自己的被回收的線程信息
item.recycleId = item.lastRecycledId = OWN_THREAD_ID;
int size = this.size;
if (size >= maxCapacity) {
// Hit the maximum capacity - drop the possibly youngest object.
return;
}
// stack中的elements擴容兩倍,複製元素,將新數組賦值給stack.elements
if (size == elements.length) {
elements = Arrays.copyOf(elements, Math.min(size << 1, maxCapacity));
}
elements[size] = item;
this.size = size + 1;
}同線程回收對象 DefaultHandle#recycle 步驟:
- stack 先檢測當前的線程是否是創建 stack 的線程,如果不是,則走異線程回收邏輯;如果是,則首先判斷是否重複回收,然後判斷 stack 的 DefaultHandle[] 中的元素個數是否已經超過最大容量(4k),如果是,直接返回;
- 判斷當前的 DefaultHandle[] 是否還有空位,如果沒有,以 maxCapacity 為最大邊界擴容 2 倍,之後拷貝舊數組的元素到新數組,然後將當前的 DefaultHandle 對象放置到 DefaultHandle[] 中
- 最後重置 stack.size 屬性
異線程回收對象
WeakOrderQueue
static final class Stack<T> {
//使用volatile可以立即讀取到該queue
private volatile WeakOrderQueue head;
}
WeakOrderQueue(Stack<?> stack, Thread thread) {
head = tail = new Link();
//使用的是WeakReference ,作用是在poll的時候,如果owner不存在了
// 則需要將該線程所包含的WeakOrderQueue的元素釋放,然後從鏈表中刪除該Queue。
owner = new WeakReference<>(thread);
//假設線程B和線程C同時回收線程A的對象時,有可能會同時創建一個WeakOrderQueue,就坑同時設置head,所以這裏需要加鎖
synchronized (stackLock(stack)) {
next = stack.head;
stack.head = this;
}
}創建WeakOrderQueue對象的時候會初始化一個WeakReference的owner,作用是在poll的時候,如果owner不存在了, 則需要將該線程所包含的WeakOrderQueue的元素釋放,然後從鏈表中刪除該Queue。
然後給stack加鎖,假設線程B和線程C同時回收線程A的對象時,有可能會同時創建一個WeakOrderQueue,就坑同時設置head,所以這裏需要加鎖。
以head==null的時候為例
加鎖:
線程B先執行,則head = 線程B的queue;之後線程C執行,此時將當前的head也就是線程B的queue作為線程C的queue的next,組成鏈表,之後設置head為線程C的queue
不加鎖:
線程B先執行 next = stack.head此時線程B的queue.next=null->線程C執行next = stack.head;線程C的queue.next=null-> 線程B執行stack.head = this;設置head為線程B的queue -> 線程C執行stack.head = this;設置head為線程C的queue,此時線程B和線程C的queue沒有連起來。
WeakOrderQueue#add
void add(DefaultHandle handle) {
// 設置handler的最近一次回收的id信息,標記此時暫存的handler是被誰回收的
handle.lastRecycledId = id;
Link tail = this.tail;
int writeIndex;
// 判斷一個Link對象是否已經滿了:
// 如果沒滿,直接添加;
// 如果已經滿了,創建一個新的Link對象,之後重組Link鏈表,然後添加元素的末尾的Link(除了這個Link,前邊的Link全部已經滿了)
if ((writeIndex = tail.get()) == LINK_CAPACITY) {
this.tail = tail = tail.next = new Link();
writeIndex = tail.get();
}
tail.elements[writeIndex] = handle;
// 如果使用者在將DefaultHandle對象壓入隊列后,將Stack設置為null
// 但是此處的DefaultHandle是持有stack的強引用的,則Stack對象無法回收;
//而且由於此處DefaultHandle是持有stack的強引用,WeakHashMap中對應stack的WeakOrderQueue也無法被回收掉了,導致內存泄漏
handle.stack = null;
// we lazy set to ensure that setting stack to null appears before we unnull it in the owning thread;
// this also means we guarantee visibility of an element in the queue if we see the index updated
// tail本身繼承於AtomicInteger,所以此處直接對tail進行+1操作
tail.lazySet(writeIndex + 1);
}Stack異線程push對象流程:
- 首先獲取當前線程的 Map<Stack<?>, WeakOrderQueue> 對象,如果沒有就創建一個空 map;
- 然後從 map 對象中獲取 key 為當前的 Stack 對象的 WeakOrderQueue;
- 如果獲取的WeakOrderQueue對象為null,那麼創建一個WeakOrderQueue對象,並將對象放入到map中,最後調用WeakOrderQueue#add添加對象
WeakOrderQueue 的創建流程:
- 創建一個Link對象,將head和tail的引用都設置為此對象
- 創建一個WeakReference指向owner對象,設置當前的 WeakOrderQueue 所屬的線程為當前線程。
- 先將原本的 stack.head 賦值給剛剛創建的 WeakOrderQueue 的 next 節點,之後將剛剛創建的 WeakOrderQueue 設置為 stack.head(這一步非常重要:假設線程 A 創建對象,此處是線程 C 回收對象,則線程 C 先獲取其 Map<Stack<?>, WeakOrderQueue> 對象中 key=線程A的stack對象的 WeakOrderQueue,然後將該 Queue 賦值給線程 A 的 stack.head,後續的 pop 操作打基礎),形成 WeakOrderQueue 的鏈表結構。
WeakOrderQueue#add添加對象流程
- 首先設置 item.lastRecycledId = 當前 WeakOrderQueue 的 id
- 然後看當前的 WeakOrderQueue 中的 Link 節點鏈表中的尾部 Link 節點的 DefaultHandle[] 中的元素個數是否已經達到 LINK_CAPACITY(16)
- 如果不是,則直接將當前的 DefaultHandle 元素插入尾部 Link 節點的 DefaultHandle[] 中,之後置空當前的 DefaultHandle 元素的 stack 屬性,最後記錄當前的 DefaultHandle[] 中的元素數量;
- 如果是,則新建一個 Link,並且放在當前的 Link 鏈表中的尾部節點處,與之前的 tail 節點連起來(鏈表),之後進行第三步的操作。
從異線程獲取對象
我再把pop方法搬下來一次:
DefaultHandle pop() {
int size = this.size;
// size=0 則說明本線程的Stack沒有可用的對象,先從其它線程中獲取。
if (size == 0) {
// 當 Stack<T> 此時的容量為 0 時,去 WeakOrder 中轉移部分對象到 Stack 中
if (!scavenge()) {
return null;
}
//由於在transfer(Stack<?> dst)的過程中,可能會將其他線程的WeakOrderQueue中的DefaultHandle對象傳遞到當前的Stack,
//所以size發生了變化,需要重新賦值
size = this.size;
}
//size表示整個stack中的大小
size--;
//獲取最後一個元素
DefaultHandle ret = elements[size];
if (ret.lastRecycledId != ret.recycleId) {
throw new IllegalStateException("recycled multiple times");
}
// 清空回收信息,以便判斷是否重複回收
ret.recycleId = 0;
ret.lastRecycledId = 0;
this.size = size;
return ret;
}- 首先獲取當前的 Stack 中的 DefaultHandle 對象中的元素個數。
- 如果為 0,則從其他線程的與當前的 Stack 對象關聯的 WeakOrderQueue 中獲取元素,並轉移到 Stack 的 DefaultHandle[] 中(每一次 pop 只轉移一個有元素的 Link),如果轉移不成功,說明沒有元素可用,直接返回 null;
- 如果轉移成功,則重置 size屬性 = 轉移后的 Stack 的 DefaultHandle[] 的 size,之後直接獲取 Stack 對象中 DefaultHandle[] 的最後一位元素,之後做防護性檢測,最後重置當前的 stack 對象的 size 屬性以及獲取到的 DefaultHandle 對象的 recycledId 和 lastRecycledId 回收標記,返回 DefaultHandle 對象。
scavenge轉移
Stack#scavenge
boolean scavenge() {
// continue an existing scavenge, if any
// 掃描判斷是否存在可轉移的 Handler
if (scavengeSome()) {
return true;
}
// reset our scavenge cursor
prev = null;
cursor = head;
return false;
}調用scavengeSome掃描判斷是否存在可轉移的 Handler,如果沒有,那麼就返回false,表示沒有可用對象
Stack#scavengeSome
boolean scavengeSome() {
WeakOrderQueue cursor = this.cursor;
if (cursor == null) {
cursor = head;
// 如果head==null,表示當前的Stack對象沒有WeakOrderQueue,直接返回
if (cursor == null) {
return false;
}
}
boolean success = false;
WeakOrderQueue prev = this.prev;
do {
// 從當前的WeakOrderQueue節點進行 handler 的轉移
if (cursor.transfer(this)) {
success = true;
break;
}
// 遍歷下一個WeakOrderQueue
WeakOrderQueue next = cursor.next;
// 如果 WeakOrderQueue 的實際持有線程因GC回收了
if (cursor.owner.get() == null) {
// If the thread associated with the queue is gone, unlink it, after
// performing a volatile read to confirm there is no data left to collect.
// We never unlink the first queue, as we don't want to synchronize on updating the head.
// 如果當前的WeakOrderQueue的線程已經不可達了
//如果該WeakOrderQueue中有數據,則將其中的數據全部轉移到當前Stack中
if (cursor.hasFinalData()) {
for (;;) {
if (cursor.transfer(this)) {
success = true;
} else {
break;
}
}
}
//將當前的WeakOrderQueue的前一個節點prev指向當前的WeakOrderQueue的下一個節點,
// 即將當前的WeakOrderQueue從Queue鏈表中移除。方便後續GC
if (prev != null) {
prev.next = next;
}
} else {
prev = cursor;
}
cursor = next;
} while (cursor != null && !success);
this.prev = prev;
this.cursor = cursor;
return success;
}- 首先設置當前操作的 WeakOrderQueue cursor,如果為 null,則賦值為 stack.head 節點,如果 stack.head 為 null,則表明外部線程沒有回收過當前線程創建的 對象,外部線程在回收對象的時候會創建一個WeakOrderQueue,並將stack.head 指向新創建的WeakOrderQueue對象,則直接返回 false;如果不為 null,則繼續向下執行;
- 首先對當前的 cursor 進行元素的轉移,如果轉移成功,則跳出循環,設置 prev 和 cursor 屬性;
- 如果轉移不成功,獲取下一個線程 Y 中的與當前線程的 Stack 對象關聯的 WeakOrderQueue,如果該 queue 所屬的線程 Y 還可達,則直接設置 cursor 為該 queue,進行下一輪循環;如果該 queue 所屬的線程 Y 不可達了,則判斷其內是否還有元素,如果有,全部轉移到當前線程的 Stack 中,之後將線程 Y 的 queue 從查詢 queue 鏈表中移除。
transfer轉移
boolean transfer(Stack<?> dst) {
//尋找第一個Link
Link head = this.head;
// head == null,沒有存儲數據的節點,直接返回
if (head == null) {
return false;
}
// 讀指針的位置已經到達了每個 Node 的存儲容量,如果還有下一個節點,進行節點轉移
if (head.readIndex == LINK_CAPACITY) {
//判斷當前的Link節點的下一個節點是否為null,如果為null,說明已經達到了Link鏈表尾部,直接返回,
if (head.next == null) {
return false;
}
// 否則,將當前的Link節點的下一個Link節點賦值給head和this.head.link,進而對下一個Link節點進行操作
this.head = head = head.next;
}
// 獲取Link節點的readIndex,即當前的Link節點的第一個有效元素的位置
final int srcStart = head.readIndex;
// 獲取Link節點的writeIndex,即當前的Link節點的最後一個有效元素的位置
int srcEnd = head.get();
// 本次可轉移的對象數量(寫指針減去讀指針)
final int srcSize = srcEnd - srcStart;
if (srcSize == 0) {
return false;
}
// 獲取轉移元素的目的地Stack中當前的元素個數
final int dstSize = dst.size;
// 計算期盼的容量
final int expectedCapacity = dstSize + srcSize;
// 期望的容量大小與實際 Stack 所能承載的容量大小進行比對,取最小值
if (expectedCapacity > dst.elements.length) {
final int actualCapacity = dst.increaseCapacity(expectedCapacity);
srcEnd = Math.min(srcStart + actualCapacity - dstSize, srcEnd);
}
if (srcStart != srcEnd) {
// 獲取Link節點的DefaultHandle[]
final DefaultHandle[] srcElems = head.elements;
// 獲取目的地Stack的DefaultHandle[]
final DefaultHandle[] dstElems = dst.elements;
// dst數組的大小,會隨着元素的遷入而增加,如果最後發現沒有增加,那麼表示沒有遷移成功任何一個元素
int newDstSize = dstSize;
//// 進行對象轉移
for (int i = srcStart; i < srcEnd; i++) {
DefaultHandle element = srcElems[i];
// 表明自己還沒有被任何一個 Stack 所回收
if (element.recycleId == 0) {
element.recycleId = element.lastRecycledId;
// 避免對象重複回收
} else if (element.recycleId != element.lastRecycledId) {
throw new IllegalStateException("recycled already");
}
// 將可轉移成功的DefaultHandle元素的stack屬性設置為目的地Stack
element.stack = dst;
// 將DefaultHandle元素轉移到目的地Stack的DefaultHandle[newDstSize ++]中
dstElems[newDstSize++] = element;
// 設置為null,清楚暫存的handler信息,同時幫助 GC
srcElems[i] = null;
}
// 將新的newDstSize賦值給目的地Stack的size
dst.size = newDstSize;
if (srcEnd == LINK_CAPACITY && head.next != null) {
// 將Head指向下一個Link,也就是將當前的Link給回收掉了
// 假設之前為Head -> Link1 -> Link2,回收之後為Head -> Link2
this.head = head.next;
}
// 設置讀指針位置
head.readIndex = srcEnd;
return true;
} else {
// The destination stack is full already.
return false;
}
}
}- 尋找 cursor 節點中的第一個 Link如果為 null,則表示沒有數據,直接返回;
- 如果第一個 Link 節點的 readIndex 索引已經到達該 Link 對象的 DefaultHandle[] 的尾部,則判斷當前的 Link 節點的下一個節點是否為 null,如果為 null,說明已經達到了 Link 鏈表尾部,直接返回,否則,將當前的 Link 節點的下一個 Link 節點賦值給 head ,進而對下一個 Link 節點進行操作;
- 獲取 Link 節點的 readIndex,即當前的 Link 節點的第一個有效元素的位置
- 獲取 Link 節點的 writeIndex,即當前的 Link 節點的最後一個有效元素的位置
- 計算 Link 節點中可以被轉移的元素個數,如果為 0,表示沒有可轉移的元素,直接返回
- 獲取轉移元素的目標 Stack 中當前的元素個數(dstSize)並計算期盼的容量 expectedCapacity,如果 expectedCapacity 大於目標Stack 的長度(dst.elements.length),則先對目的地 Stack 進行擴容,計算 Link 中最終的可轉移的最後一個元素的下標;
- 如果發現目的地 Stack 已經滿了( srcStart != srcEnd為false),則直接返回 false
- 獲取 Link 節點的 DefaultHandle[] (srcElems)和目標 Stack 的 DefaultHandle[](dstElems)
- 根據可轉移的起始位置和結束位置對 Link 節點的 DefaultHandle[] 進行循環操作
- 將可轉移成功的 DefaultHandle 元素的stack屬性設置為目標 Stack(element.stack = dst),將 DefaultHandle 元素轉移到目的地 Stack 的 DefaultHandle[newDstSize++] 中,最後置空 Link 節點的 DefaultHandle[i]
- 如果當前被遍歷的 Link 節點的 DefaultHandle[] 已經被掏空了(srcEnd == LINK_CAPACITY),並且該 Link 節點還有下一個 Link 節點
- 重置當前 Link 的 readIndex
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整