環境資訊中心綜合外電;黃鈺婷 翻譯;林大利 審校;稿源:Mongabay
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
※產品缺大量曝光嗎?你需要的是一流包裝設計!
※推薦台中搬家公司優質服務,可到府估價
其搭載的1。5L地球夢發動機,最大功率131馬力,峰值扭矩155牛米,和CVT變速箱搭配動力響應性出色,加速實力“有點猛”。很好地兼顧了動力以及油耗。空間實用的國貨SUV吉利汽車-遠景SUV指導價:7。49-10。19萬9萬元的預算也可以選擇現在火熱的國產SUV車型,它們空間實用,坐姿高、視野也不錯。
本站聲明:網站內容來源於http://www.auto6s.com/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
※別再煩惱如何寫文案,掌握八大原則!
但本田擅長的空間攫取能力則得以比較充分的體現,儘管XR-V的車身三圍尺寸並不算大,但在乘坐空間的表現上,好感度要比同級別的昂科拉更勝一籌。動力:非常經典的對決別克昂科拉與本田XR-V的對比也可以說是很多人十分在意的“渦輪增壓與自然吸氣的對比”,別克昂科拉採用1。
別克昂科拉 VS 本田XR-V?
當下汽車設計的主流也跟汽車消費的主流趨勢一樣,越來越趨於年輕化,別克昂科拉和東風本田XR-V則都是設計偏向年輕時尚的小型SUV,也是很多首次購車人群在合資小型SUV這個細分市場的首要考慮對象車型,那麼這兩款車型各自優勢在哪?又該如何選擇?
由於兩車在指導價格方面差距還是比較大,別克昂科拉明顯偏貴,而且別克昂科拉的細分車型當中有一款四驅配置車型,反觀XR-V全系沒有四驅標配,我們去除別克朗科拉頂配四驅旗艦型,採用兩驅都市精英型(次頂配),與XR-V 1.8L CVT豪華版(頂配)對比,兩者指導價格和配置更加接近。
東風本田-XR-V
1.8L VTi CVT豪華版
指導價格:16.28萬
別克昂科拉
18T 自動兩驅都市精英型
指導價格:16.99萬
外觀:敦實沉穩VS時尚運動
昂科拉的整體外觀變化並不大,主要的變化在於前臉,車標加上飛翼式鍍鉻綬帶的裝飾安置於直瀑式中網上,鍍鉻綬帶還與前大燈模塊內的日間行車燈融為一體,這讓昂科拉的前臉顯得更加具有辨識度;
整車還是維持了昂科拉一貫的敦實形象,這麼一款尺寸不大的小型SUV看上去會讓人有一種沉穩紮實的感覺,腰線和車尾線條飽滿,配合上原廠提供的較為具有活力的配色,昂科拉的造型也透露出一種時尚的動感。
XR-V使用了當下本田家族式的上下雙條幅鍍鉻裝飾作為前臉主體設計元素,配合上銳利的大燈和大面積的黑色塑料裝飾,本田XR-V前臉顯得運動感與攻擊性都更為明顯。
相較於昂科拉的“敦厚”,XR-V的整車線條則顯得有些“扁”,這種效果就會使得車身側面的視覺效果顯得更加修長,車尾設計線條層次感豐富,橫向線條多次運用但不會顯得雜亂和複雜,反而更提升了XR-V年輕的效果。
內飾:各家所長得以充分體現
別克家族近年來的內飾營造手段是體現在全系車型上的,昂科拉亦是如此,乍一眼看上去,別克昂科拉的內飾設計很容易給人以好感,而且在用料的選材和裝配上,別克昂克拉的內飾顯得比較高檔。
而XR-V的內飾設計感或許稍微欠缺,而且由於成本所限,拼接裝飾板材質較硬,在對比體驗上說或許溝通感有所減分。但本田擅長的空間攫取能力則得以比較充分的體現,儘管XR-V的車身三圍尺寸並不算大,但在乘坐空間的表現上,好感度要比同級別的昂科拉更勝一籌。
動力:非常經典的對決
別克昂科拉與本田XR-V的對比也可以說是很多人十分在意的“渦輪增壓與自然吸氣的對比”,別克昂科拉採用1.4T渦輪增壓發動機配合6速手自一體的動力總成。最大馬力143匹,峰值扭矩205牛米。
昂科拉的峰值扭矩平台在發動機達到1800轉的時候得以爆發,對於這個級別的小排量渦輪增壓車型來說中規中矩,兩驅版本的車重1.4噸,動力輸出也不會因此而感到拖沓,換擋效率較高的手自一體變速箱也賦予了昂科拉一定的駕駛樂趣。
本田XR-V所搭載的是一台1.8L自然吸氣發動機,最大馬力136匹,峰值扭矩169牛米,與之配合的是一台CVT無極變速箱,整體駕駛感受保留了一台CVT該有的平順特性,駕駛樂趣的話,小編覺得談不上,但踏實平穩才是一款CVT車型該有的基調。
而且由於XR-V整備質量不大,頂配CVT豪華版車重1.3噸,加之本田CVT變速箱一貫良好的加速性能,XR-V在城市裡通勤的表現也是非常靈活,駕駛起來沒有太大難度。
哪個更值得買?
如果看重的是整車所給予人的質感和高級感方面,別克昂科拉是比較好的選擇,畢竟在車內裝飾用料和整車NVH的控制上,別克昂科拉可以說做到了領先於同級別其他車型的水準,昂科拉所給予人的是更高檔的使用感受。
而如果更看重的是車內更實用的空間表現和駕駛起來的平順性的話,本田XR-V或許更值得考慮,畢竟這兩塊是本田這個品牌所擅長的領域,而且在XR-V上也得以較好的體現,無論是乘坐空間還是載物空間,本田依舊展現了較強的空間利用實力,在動力平順性上,本田的CVT變速箱和自然吸氣發動機配合出來的線性感受也不會使人失望。
全文總結:儘管2017款的昂科拉在12月6日才剛剛上市,但是外觀配置並沒有過多的變化,而且在售價上與2016款幾乎齊平;加之在終端優惠上,別克全系車型當下的終端優惠普遍不小,而反觀日系的XR-V,降價的幅度則比較有限,所以如果從終端優惠上看,或許選擇折扣更大的別克昂科拉也是個不錯的想法。本站聲明:網站內容來源於http://www.auto6s.com/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※推薦評價好的iphone維修中心
※網頁設計最專業,超強功能平台可客製化
※別再煩惱如何寫文案,掌握八大原則!
運動版全身大幅採用超高張力鋼板,並在車身關鍵部位進行了強化,安全性進一步提升。在主動安全性方面,T600運動版更將安全防護展現得淋漓盡致,安全配一應俱全。ESC車身穩定系統、HAC上坡輔助系統、前後倒車雷達及360°可視倒車影像等安全配置,與6方位安全氣囊、盲點信息系統、紅外夜視系統、TpMS智能胎壓監測、可選裝的HUD抬頭显示系統等尖端科技配備聯合上演重重壁壘,出色安全,呼之欲出,滿滿自信應對挑戰,盡享出行便利。
12月6日,中國汽車場地越野錦標賽(COC)廈門站比賽圓滿結束,也是最後一場分站賽,在各組別激烈的決賽搶分大戰中,眾泰T600越野車隊在汽油廠商組中奪得頭籌,車手鹿丙龍奪取該組冠軍,並與隊友徐瑩一起為車隊捧回了廠商杯冠軍殊榮,從而擴大了在年度積分方面的領先優勢,眾泰已經在今年分站比賽中已獲得六連冠,高歌猛進,一步步接近年度總冠軍。
作為本年度分站賽的最後一站,各個車隊之間的競爭日趨白熱化,尤其是之前比賽積分接近的車隊及隊員,比賽前已經是“劍拔弩張”,力爭本站取得更好排名和積分。眾泰車隊隊長楊逵如是向記者說道:“相對來說,我們在汽油改裝組的優勢要大一些,汽油廠商組和奇瑞車隊比較接近,由於總決賽採用雙倍積分的賽制,能否最終獲得全年總冠軍,廈門站比賽顯得尤為重要”。
【場地航拍圖】
【車隊大營】
【眾泰T600戰車】
汽油廠商組
本次比賽最大的變化就是之前因嚴重違規被禁賽的長安CS75車隊,重新回到了比賽。針對COC廈門站比賽形勢的變化,眾泰T600越野車隊對參賽陣容也進行了微調,喬旭與刁志剛攜手出擊汽油改裝組,鹿丙龍回歸汽油廠商組,和徐瑩搭檔。
在6圈的第一輪預賽中,車手們都拿出渾身解數,以求跑出好成績,從而得到決賽中最好的發車位置。眾泰車隊的鹿丙龍和徐瑩不負眾望,以小組第三、第四的成績闖進決賽,一起進入決賽的還有長安CS75車隊的文凡和孟斌。
“我們自身和車輛都調整到了最好狀態,對下午進行的決賽充滿信心”,眾泰T600越野車隊的車手鹿丙龍在決賽前向記者如是說。決賽中,鹿丙龍的表現堪稱“完美”,以絕對優勢力壓長安CS75車隊的孟斌和文凡獲得本組冠軍,其隊友徐瑩獲得本組季軍,獲得本組亞軍的是來自長安CS75車隊的孟斌,同時,鹿丙龍和徐瑩為眾泰T600越野車隊爭得了汽油廠商組的車隊團體冠軍獎盃。
汽油改裝組
眾泰T600越野車隊的喬旭在第一輪預賽中並不順利,他在第三圈的時候賽車出現失誤,賽車在幾處急彎都發生失控打橫,這極大地影響了喬旭的成績,儘管第二輪成績出色,但仍與決賽失之交臂,其隊友刁志剛以小組第三的成績征戰第二天進行的決賽。
6日下午的決賽中,車手刁志剛一人獨自面對其他三位車手的多面夾擊,面對發車位置不力的劣勢,刁志剛仍然奮起直追,最後以微小差距獲得了本小組的季軍,獲得本組冠亞軍的是來自另外兩支車隊的趙向前和童振榮。
作為“主流價值SUV”的眾泰T600,同眾泰車隊一樣,已然成為乘用車銷售市場上的佼佼者,早已進入月銷量“萬台俱樂部”,2016年1-10月份更是實現了94371台的銷量,以月均近萬台的銷量位居自主品牌中型SUV銷量榜首。
而且2016年眾泰汽車推出了更為年輕時尚的眾泰T600運動版,作為在眾泰T600優勢平台上推出的車型,眾泰T600運動版同樣以其年輕時尚又不乏沉穩的外觀、越級的配置在整個市場中還是有着普遍好評,銷量也是芝麻開花節節高。
眾泰T600運動版全系標配10寸中控彩色大屏,內容豐富。而Tye-net智控系統的優勢融入,實現手機操遠程控愛車,娛樂隨行,舒心便利。
此外,眾泰T600運動版還配備了一鍵啟動/無鑰匙進入、紅外夜視系統、腳步感應式電動尾門等尖端科技配備,讓駕乘人員充分享受科技智能帶來的便捷體驗。電動全景天窗、电子駐車系統、前排座椅分級加熱、雙區獨立自動恆溫空調、手機無線充電、方向盤/座椅/后視鏡三項聯動記憶功能、全液晶儀錶盤、定速巡航等帶來更加細緻入微的貼心關懷,讓出行一路無虞。
安全配置方面,眾泰T600運動版同級領先的安全性讓駕乘者無需前瞻後顧,無憂外出。運動版全身大幅採用超高張力鋼板,並在車身關鍵部位進行了強化,安全性進一步提升。在主動安全性方面,T600運動版更將安全防護展現得淋漓盡致,安全配一應俱全。ESC車身穩定系統、HAC上坡輔助系統、前後倒車雷達及360°可視倒車影像等安全配置,與6方位安全氣囊、盲點信息系統、紅外夜視系統、TpMS智能胎壓監測、可選裝的HUD抬頭显示系統等尖端科技配備聯合上演重重壁壘,出色安全,呼之欲出,滿滿自信應對挑戰,盡享出行便利。
而眾泰T600運動版不只是在外觀上吸引目光,在內飾的色彩搭配上,更是可圈可點,整個車內空間看起來既神秘又科技時尚。
眾泰T600運動版擁有的2807mm的傲人軸距,有效保證了車輛的駕乘空間。車內豐富的儲物空間為日常儲物提供了便利,而且後排座椅放倒後進一步拓展了後備箱空間,可以盡情享受眾泰T600運動版帶來的寬適空間。
動力方面,T600運動版提供1.5T及2.0T兩種發動機車型,1.5T渦輪增壓發動機與5速手動變速器搭配出黃金動力組合,最大功率達119KW,最大扭矩達215N·m。更加值得期待的是其2.0T車型,搭配使用旋鈕換擋式6速雙離合或5速手動變速器,最大功率140KW,最大扭矩250N·m,百公里加速只需9.26秒,充分提高了燃油的利用率,更加的節能環保,同時降低了用車成本。眾泰T600運動版,就是這樣讓你既有“面子”,又有“裡子”。
還有值得一說的是,眾泰T600在2015年J.D.power亞太公司發布的中國新車質量研究(IQS)報告,眾泰T600在中型SUV中pp100(每百車問題數)為100,優於中型SUV平均水平(pp100:106),全國綜合排名第13位,位列中型SUV中國品牌第二名。
2016年度COC總決賽將於12月中旬在廣西柳州打響,總決賽將實行雙倍積分制,各組別總決賽冠軍將收穫50分,這也讓之前積分落後並不太多的車手擁有了翻身逆轉的機會,那眾泰T600能否攜勢而來,獲得全年比賽的總冠軍,讓我們拭目以待!本站聲明:網站內容來源於http://www.auto6s.com/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※網頁設計最專業,超強功能平台可客製化
※別再煩惱如何寫文案,掌握八大原則!
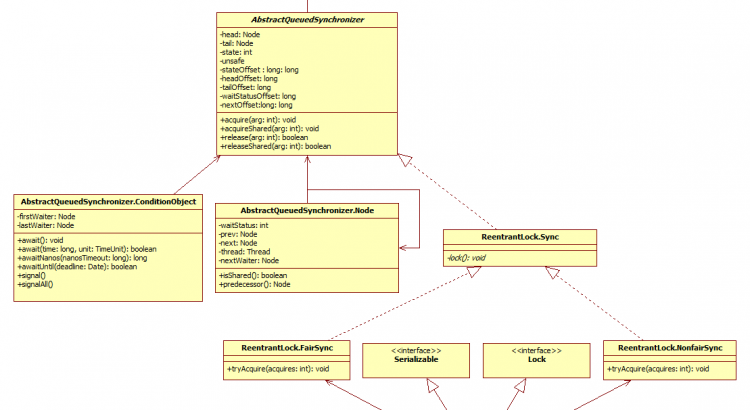
一 UML類圖
1.1、ReentrantLock
通過類圖ReentrantLock是同步鎖,同一時間只能有一個線程獲取到鎖,其他獲取該鎖的線程會被阻塞而被放入AQS阻塞隊列中。ReentrantLock類繼承Lock接口;內部抽象類Sync實現抽象隊列同步器AbstractQueuedSynchronizer;Sync類有兩個子類NonfairSync(非公平鎖)和FairSync(公平鎖),默認構造方法使用非公平鎖,可以使用帶布爾參數的構造方法指定使用公平鎖;ReentrantLock可以創建多個條件進行綁定。
1.2、AbstractQueuedSynchronizer
AbstractQueuedSynchronizer:抽象隊列同步器,維護一個volatile int state變量標識共享資源和一個FIFO線程阻塞隊列(AQS隊列)。
protected final void setState(int newState):設置state值
protected final int getState():獲取state值
protected final boolean compareAndSetState(int expect, int update):CAS設置state值
AQS有兩種共享資源類型:SHARED(共享)和EXCLUSIVE(獨佔),針對類型有不同的方法:
protected boolean tryAcquire(int arg):獨佔類型獲取鎖
protected boolean tryRelease(int arg):獨佔類型釋放鎖
protected int tryAcquireShared(int arg):共享類型獲取鎖
protected boolean tryReleaseShared(int arg):共享類型釋放鎖
protected boolean isHeldExclusively():是否是獨佔類型
1.3、線程節點類型waitStatus
AQS隊列中節點的waitStatus枚舉值(java.util.concurrent.locks.AbstractQueuedSynchronizer.Node)含義:
static final int CANCELLED = 1; //線程被取消
static final int SIGNAL = -1; //成功的線程需要被喚醒
static final int CONDITION = -2; //線程在條件隊列中等待
static final int PROPAGATE = -3; //釋放鎖是需要通知其他節點
二 原理分析
2.1 獲取鎖
2.1.1 void lock()方法
調用線程T調用該方法嘗試獲取當前鎖。
①如果鎖未被其他線程獲取,則調用線程T成功獲取到當前鎖,然後設置當前鎖的擁有者為調用線程T,並設置AQS的狀態值state為1,然後直接返回。
②如果調用線程T之前已經獲取當前鎖,則只設置設置AQS的狀態值state加1,然後返回。
③如果當前鎖已被其他線程獲取,則調用線程T放入AQS隊列后阻塞掛起。
public void lock() { sync.lock();//委託內部公平鎖和非公平鎖獲取鎖 }
//非公平鎖
final void lock() { if (compareAndSetState(0, 1))//設置AQS狀態值為1 setExclusiveOwnerThread(Thread.currentThread());//成功設置鎖的線程擁有者 else acquire(1);//失敗加入到AQS隊列阻塞掛起 } //公平鎖 final void lock() { acquire(1); }
非公平鎖分析:
//調用父類AbstractOwnableSynchronizer方法CAS設置state值,成功返回true,失敗返回false protected final boolean compareAndSetState(int expect, int update) { return unsafe.compareAndSwapInt(this, stateOffset, expect, update); } //調用父類AbstractOwnableSynchronizer方法,設置當前線程為鎖的擁有者 protected final void setExclusiveOwnerThread(Thread thread) { exclusiveOwnerThread = thread; }
//調用AbstractQueuedSynchronizer父類方法,第一次獲取鎖失敗 public final void acquire(int arg) { if (!tryAcquire(arg) && acquireQueued(addWaiter(Node.EXCLUSIVE), arg))//排它鎖類型 selfInterrupt(); } //NonfairSync子類,重寫父類方法 protected final boolean tryAcquire(int acquires) { return nonfairTryAcquire(acquires); }
//Sync類非公平鎖嘗試獲取鎖 final boolean nonfairTryAcquire(int acquires) { final Thread current = Thread.currentThread(); int c = getState(); if (c == 0) {//二次獲取鎖 if (compareAndSetState(0, acquires)) { setExclusiveOwnerThread(current); return true; } } else if (current == getExclusiveOwnerThread()) {//當前線程已獲取鎖,AQS狀態值加1 int nextc = c + acquires; if (nextc < 0) // overflow throw new Error("Maximum lock count exceeded"); setState(nextc); return true; } return false; }
//AbstractQueuedSynchronizer類創建節點,添加到AQS隊列後面 private Node addWaiter(Node mode) { Node node = new Node(Thread.currentThread(), mode);//創建AQS隊列的節點,節點類型排它鎖 Node pred = tail;//尾結點 if (pred != null) { node.prev = pred;//新節點的前一個節點是尾結點 if (compareAndSetTail(pred, node)) {//CAS機制添加節點 pred.next = node;//尾結點執行新的節點 return node; } } enq(node); return node; }
//插入節點到隊列中
private Node enq(final Node node) { for (;;) {//循環的方式,直至創建成功 Node t = tail;//尾結點 if (t == null) { //尾結點為空,初始化 if (compareAndSetHead(new Node()))//第一步:CAS創建頭結點(哨兵節點)一個空節點 tail = head; } else { node.prev = t; if (compareAndSetTail(t, node)) {//第二步:CAS設置尾結點 t.next = node; return t; } } } }
// final boolean acquireQueued(final Node node, int arg) { boolean failed = true; try { boolean interrupted = false; for (;;) { final Node p = node.predecessor();//前向節點 if (p == head && tryAcquire(arg)) {//如果p節點是頭結點,node作為隊列第二個節點 setHead(node);//將頭節點設置為node節點,node節點出隊列 p.next = null; //原頭結點設置為空,便於GC回收 failed = false; return interrupted; } if (shouldParkAfterFailedAcquire(p, node) && parkAndCheckInterrupt()) interrupted = true; } } finally { if (failed) cancelAcquire(node);//失敗解鎖 } }
private void setHead(Node node) { head = node; node.thread = null; node.prev = null; }
//阻塞掛起當前線程
static void selfInterrupt() { Thread.currentThread().interrupt(); }
//
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) { int ws = pred.waitStatus; if (ws == Node.SIGNAL) /* * This node has already set status asking a release * to signal it, so it can safely park. */ return true; if (ws > 0) { /* * Predecessor was cancelled. Skip over predecessors and * indicate retry. */ do { node.prev = pred = pred.prev; } while (pred.waitStatus > 0);//大於0代表線程被取消 pred.next = node; } else { /* * waitStatus must be 0 or PROPAGATE. Indicate that we * need a signal, but don't park yet. Caller will need to * retry to make sure it cannot acquire before parking. */ compareAndSetWaitStatus(pred, ws, Node.SIGNAL); } return false; } //線程阻塞,打斷線程 private final boolean parkAndCheckInterrupt() { LockSupport.park(this); return Thread.interrupted(); }
公平鎖分析:
protected final boolean tryAcquire(int acquires) { final Thread current = Thread.currentThread(); int c = getState(); if (c == 0) { if (!hasQueuedPredecessors() && compareAndSetState(0, acquires)) {//與非公平鎖相比,區別就在標紅的位置 setExclusiveOwnerThread(current); return true; } }else if (current == getExclusiveOwnerThread()) { int nextc = c + acquires; if (nextc < 0) throw new Error("Maximum lock count exceeded"); setState(nextc); return true; } return false; }
public final boolean hasQueuedPredecessors() { // The correctness of this depends on head being initialized // before tail and on head.next being accurate if the current // thread is first in queue. Node t = tail; // Read fields in reverse initialization order Node h = head; Node s;
//①h != t:表示AQS隊列頭結點和尾結點不相同,隊列不為空;
//②(s = h.next) == null || s.thread != Thread.currentThread():頭結點(哨兵節點)為空或者next節點不等於當前線程 return h != t && ((s = h.next) == null || s.thread != Thread.currentThread()); }
2.1.2 void lockInterruptibly()方法
與2.2.1方法相似,不同之處在於:該方法對中斷進行響應,其他線程調用當前線程中斷方法,拋出InterruptedException。
2.1.3 boolean tryLock()方法
嘗試獲取鎖。注意:該方法不會引起當前線程阻塞。
2.1.4 boolean tryLock(long timeout, TimeUnit unit)方法
與2.1.3方法相似,不同之處在於:設置了超時時間。
2.2 釋放鎖
嘗試釋放鎖。
如果當前線程T已獲取鎖,則調用該方法更新AQS狀態值減1。如果當前狀態值為0,則釋放鎖;如果當前狀態值部位0,則只是減1操作。
如果當前線程T未獲取鎖,則調用該方法是會拋出IllegalMonitorStateException異常。
2.2.1 void unlock()方法
public void unlock() { sync.release(1); } //調用AbstractQueuedSynchronizer方法 public final boolean release(int arg) { if (tryRelease(arg)) { Node h = head; if (h != null && h.waitStatus != 0) unparkSuccessor(h);//喚醒線程 return true; } return false; } //回調Sync類釋放鎖 protected final boolean tryRelease(int releases) { int c = getState() - releases; if (Thread.currentThread() != getExclusiveOwnerThread()) throw new IllegalMonitorStateException(); boolean free = false; if (c == 0) { free = true; setExclusiveOwnerThread(null);//設置鎖的擁有線程為空 } setState(c); return free; } // private void unparkSuccessor(Node node) { /* * If status is negative (i.e., possibly needing signal) try * to clear in anticipation of signalling. It is OK if this * fails or if status is changed by waiting thread. */ int ws = node.waitStatus;//線程阻塞等待狀態 if (ws < 0) compareAndSetWaitStatus(node, ws, 0);//CAS設置狀態 /* * Thread to unpark is held in successor, which is normally * just the next node. But if cancelled or apparently null, * traverse backwards from tail to find the actual * non-cancelled successor. */ Node s = node.next; if (s == null || s.waitStatus > 0) { s = null; for (Node t = tail; t != null && t != node; t = t.prev)//遍歷AQS隊列 if (t.waitStatus <= 0) s = t; } if (s != null) LockSupport.unpark(s.thread);//喚醒線程 }
h != t
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※教你寫出一流的銷售文案?
※別再煩惱如何寫文案,掌握八大原則!

【摘要】我們從人臉識別技術的技術細節講起,帶你初步了解人臉識別技術的發展過程。通過平台實例的操作,帶你看看如何利用公有雲的計算資源,快速訓練一個可用的人臉識別模型。
大家應該都看過布拉德.伯德執導、湯姆.克魯斯主演的《碟中諜4吧》?茫茫人海的火車站,只要一眨眼的功夫已經被計算機識別出來,隨即被特工盯梢;迎面相逢的美女是致命殺手,手機發出嘀嘀的報警聲,上面已經显示美女的姓名和信息。這就是本文想要介紹的人臉識別算法,以及如果使用公有雲AI平台訓練模型。
作為目前人工智能領域中成熟較早、落地較廣的技術之一,人臉識別的目的是要判斷圖片和視頻中人臉的身份。從平常手機的刷臉解鎖、刷臉支付,再到安防領域內的人臉識別布控,等等,人臉識別技術都有着廣泛的應用。人臉是每個人與生俱來的特徵,該特徵具有唯一性並且不易被複制,從而為身份鑒別提供了必要的前提。
人臉識別的研究始於20世紀60年代,隨着計算機技術和光學成像技術的發展不斷提高,以及近幾年神經網絡技術的再次興起,尤其是卷積神經網絡在圖像識別和檢測中取得的巨大成功,使得人臉識別系統的效果得到了極大的提升。本文,我們從人臉識別技術的技術細節講起,帶你初步了解人臉識別技術的發展過程,文章的後半篇,我們將會使用ModelArts平台的自定義鏡像,帶你看看如何利用公有雲的計算資源,快速訓練一個可用的人臉識別模型。
不管是基於傳統圖像處理和機器學習技術,還是利用深度學習技術,其中的流程都是一樣的。如圖1所示,人臉識別系統都包括人臉檢測、對齊、編碼以及匹配四個基本環節組成。所以該部分首先通過對基於傳統圖像處理和機器學習算法的人臉識別系統進行概述,就可以看出整個深度學習算法在人臉識別領域內發展的脈絡。
人臉檢測流程
前面已經說過,人臉識別的目的就是要判斷圖像中的人臉身份是什麼,所以就首先需要先把圖像中的人臉檢測出來,其實這一步歸根結底就是一個目標檢測的問題。傳統的圖像目標檢測算法主要有三部分組成,建議框生成、特徵工程以及分類,包括著名的RCNN系列算法的優化思路也是基於這三部分進行的。
首先是建議框生成,該步驟最簡單的想法就是在圖片中crop出來一堆待檢測框,然後檢測該框內是否存在目標,如果存在,則該框在原圖中的位置即為目標檢測出的位置,因此在該步驟中對目標的覆蓋率越大,則建議框生成策略越好。常見的建議框生成策略有sliding window、Selective Search、Randomized Prim等等,生成大量的候選框,如下圖所示。
得到大量的候選框后,傳統的人臉檢測算法接下來最主要的部分就是特徵工程。特徵工程其實就是利用算法工程師的專家經驗對不同場景的人臉提取各種特徵,例如邊緣特徵、形狀形態學特徵、紋理特徵等等,具體的算法是技術有LBP、Gabor、Haar、SIFT等等特徵提取算法,將一張以二維矩陣表示的人臉圖片轉換成各種特徵向量的表示。
得到特徵向量之後,就可以通過傳統的機器學習分類器對特徵進行分類,得到是否是人臉的判斷,例如通過adaboost、cascade、SVM、隨機森林等等。通過傳統分類器分類之後就可以得到人臉的區域、特徵向量以及分類置信度等等。通過這些信息,我們就可以完成人臉對齊、特徵表示以及人臉匹配識別的工作。
以傳統方法中,經典的HAAR+AdaBoost的方法為例,在特徵提取階段,首先會利用haar特徵在圖片中提取出很多簡單的特徵。Haar特徵如下圖所示。為了滿足不同大小人臉的檢測,通常會利用高斯金字塔對不同分辨率的圖像進行Haar特徵的提取。
Haar特徵的計算方法是將白色區域內的像素和減去黑色區域,因此在人臉和非人臉的區域內,得到的值是不一樣的。一般在具體實現過程中,可以通過積分圖的方法快速實現。一般在歸一化到20*20的訓練圖片中,可供使用的Haar特徵數在一萬個左右,因此在這種特徵規模的情況下,可以利用機器學習的算法進行分類和識別。
得到Haar特徵后,可以利用Adaboost進行分類,Adaboost算法是一種將多個比較弱的分類方法合在一起,組合出新的強分類方法。根據該級聯分類器,和訓練好的各個特徵選擇閾值,就可以完成對人臉的檢測。
從上述方法可以看出,傳統的機器學習算法是基於特徵的算法,因此需要大量的算法工程師的專家經驗進行特徵工程和調參等工作,算法效果也不是很好。而且人工設計在無約束環境中對不同變化情況都魯棒很困難的。過去的圖像算法是工程師更多的是通過傳統的圖像處理方法,根據現實場景和專家經驗提取大量的特徵,然後對提取的特徵再進行統計學習的處理,這樣整體算法的性能就非常依賴於現實場景和專家經驗,對於人臉這種類別巨大,每類樣本不均衡情況嚴重的無約束場景效果並不是很好。因此,近幾年隨着深度學習在圖像處理中取得的巨大成功,人臉識別技術也都以深度學習為主,並且已經達到了非常好的效果。
在深度學習的人臉識別系統中,該問題被分成了一個目標檢測問題和一個分類問題,而目標檢測問題在深度學習中本質還是一個分類問題和回歸問題,因此隨着卷積神經網絡在圖片分類上的成功應用,人臉識別系統的效果得到了快速且巨大的提升,並以此誕生了大量的視覺算法公司,並將人臉識別應用在了社會生活的各個方面。
其實利用神經網絡來做人臉識別並不是什麼新思想,1997年就有研究者為人臉檢測、眼部定位和人臉識別提出了一種名為基於概率決策的神經網絡的方法。這種人臉識別 PDBNN 被分成了每一個訓練主體一個全連接子網絡,以降低隱藏單元的數量和避免過擬合。研究者使用密度和邊特徵分別訓練了兩個 PBDNN,然後將它們的輸出組合起來得到最終分類決定。但是受限於當時算力和數據的嚴重不足,算法相對簡單,因此該算法並沒有得到很好的效果。隨着僅今年反向傳播理論和算力框架等的日趨成熟,人臉識別算法的效果才開始得到巨大的提升。
在深度學習中,一個完整的人臉識別系統也包括圖1所示的四個步驟,其中第一步驟叫做人臉檢測算法,本質也是一個目標檢測算法。第二個步驟叫做人臉對齊,目前又基於關鍵點的幾何對齊和基於深度學習的人臉對齊。第三個步驟特徵表示,在深度學習中是通過分類網絡的思想,提取分類網絡中的一些feature層作為人臉的特徵表示,然後用相同的方式對標準人臉像進行處理,最後通過比對查詢的方式完成整體的人臉識別系統。下面主要對人臉檢測和人臉識別算法的發展進行簡單綜述。
深度學習在圖像分類中的巨大成功后很快被用於人臉檢測的問題,起初解決該問題的思路大多是基於CNN網絡的尺度不變性,對圖片進行不同尺度的縮放,然後進行推理並直接對類別和位置信息進行預測。另外,由於對feature map中的每一個點直接進行位置回歸,得到的人臉框精度比較低,因此有人提出了基於多階段分類器由粗到細的檢測策略檢測人臉,例如主要方法有Cascade CNN、 DenseBox和MTCNN等等。
MTCNN是一個多任務的方法,第一次將人臉區域檢測和人臉關鍵點檢測放在了一起,與Cascade CNN一樣也是基於cascade的框架,但是整體思路更加的巧妙合理,MTCNN總體來說分為三個部分:PNet、RNet和ONet,網絡結構如下圖所示。
首先PNet網絡對輸入圖片resize到不同尺寸,作為輸入,直接經過兩層卷積后,回歸人臉分類和人臉檢測框,這部分稱之為粗檢測。將粗檢測得到的人臉從原圖中crop出來后,在輸入的R-Net,再進行一次人臉檢測。最後將得到的人臉最終輸入O-Net,得到的O-Net輸出結果為最終的人臉檢測結果。MTCNN整體流程相對比較簡單,能夠快速的進行部署和實現,但是MTCNN的缺點也很多。包括多階段任務訓練費時,大量中間結果的保存需要佔用大量的存儲空間。另外,由於改網絡直接對feature點進行bounding box的回歸,對於小目標人臉檢測的效果也不是很好。還有,該網絡在推理的過程中為了滿足不同大小人臉檢測需要,要將人臉圖片resize到不同尺寸內,嚴重影響了推理的速度。
隨着目標檢測領域的發展,越來越多的實驗證據證明目標檢測中更多的瓶頸在於底層網絡語義低但定位精度相對較高和高層網絡語義高但定位精度低的矛盾,目標檢測網絡也開始流行anchor-based的策略和跨層融合的策略,例如著名的Faster-rcnn、SSD和yolo系列等。因此,人臉檢測算法也越來越多的利用anchor和多路輸出來滿足不同大小人臉檢出的效果,其中最著名的算法就是SSH網絡結構。
從上圖中可以看出,SSH網絡已經有對不同網絡層輸出進行處理的方法,只需要一遍推理就能完成不同大小人臉的檢測過程,因此稱之為Single Stage。SSH的網絡也比較簡單,就是對VGG不同卷積層驚醒了分支計算並輸出。另外還對高層feature進行了上採樣,與底層feature做Eltwise Sum來完成底層與高層的特徵融合。另外SSH網絡還設計了detection module和context module,其中context module作為detection module的一部分,採用了inception的結構,獲取更多上下文信息以及更大的感受野。
SSH中的detection module模塊SSH中detection module里的context module模塊
SSH利用1×1卷積對輸出最終的回歸和分類的分支結果,並沒有利用全連接層,因此可以保證不同尺寸圖片的輸入都能得到輸出的結果,也是響應了當時全卷積設計方式的潮流。遺憾的是該網絡並沒有輸出landmark點,另外其實上下文結構也沒有用到比較流行的特徵金字塔結構,VGG16的backbone也相對較淺,隨着人臉優化技術的不斷進行,各種各樣的trick也都日趨成熟。因此,最後向大家介紹一下目前人臉檢測算法中應用比較廣的Retinaface網絡。
Retinaface由google提出,本質是基於RetinaNet的網絡結構,採用特徵金字塔技術,實現了多尺度信息的融合,對檢測小物體有重要的作用。網絡結構如下所示。
從上圖可以看出,Retinaface的backbone網絡為常見的卷積神經網絡,然後加入特徵金子塔結構和Context Module模塊,進一步融合上下文的信息,並完成包括分類、檢測、landmark點回歸以及圖像自增強的多種任務。
因為人臉檢測的本質是目標檢測任務,目標檢測未來的方向也適用於人臉的優化方向。目前在目標檢測中小目標、遮擋目標的檢測依舊很困難,另外大部份檢測網絡更多的開始部署在端側,因此基於端側的網絡模型壓縮和重構加速等等更加考驗算法工程師對與深度學習檢測算法的理解和應用。
人臉識別問題本質是一個分類問題,即每一個人作為一類進行分類檢測,但實際應用過程中會出現很多問題。第一,人臉類別很多,如果要識別一個城鎮的所有人,那麼分類類別就將近十萬以上的類別,另外每一個人之間可獲得的標註樣本很少,會出現很多長尾數據。根據上述問題,要對傳統的CNN分類網絡進行修改。
我們知道深度卷積網絡雖然作為一種黑盒模型,但是能夠通過數據訓練的方式去表徵圖片或者物體的特徵。因此人臉識別算法可以通過卷積網絡提取出大量的人臉特徵向量,然後根據相似度判斷與底庫比較完成人臉的識別過程,因此算法網絡能不能對不同的人臉生成不同的特徵,對同一人臉生成相似的特徵,將是這類embedding任務的重點,也就是怎麼樣能夠最大化類間距離以及最小化類內距離。
在人臉識別中,主幹網絡可以利用各種卷積神經網絡完成特徵提取的工作,例如resnet,inception等等經典的卷積神經網絡作為backbone,關鍵在於最後一層loss function的設計和實現。現在從兩個思路分析一下基於深度學習的人臉識別算法中各種損失函數。
思路1:metric learning,包括contrastive loss, triplet loss以及sampling method
思路2:margin based classification,包括softmax with center loss, sphereface, normface, AM-sofrmax(cosface) 和arcface。
1. Metric Larning
(1)Contrastive loss
深度學習中最先應用metric learning思想之一的便是DeepID2了。其中DeepID2最主要的改進是同一個網絡同時訓練verification和classification(有兩個監督信號)。其中在verification loss的特徵層中引入了contrastive loss。
Contrastive loss不僅考慮了相同類別的距離最小化,也同時考慮了不同類別的距離最大化,通過充分運用訓練樣本的label信息提升人臉識別的準確性。因此,該loss函數本質上使得同一個人的照片在特徵空間距離足夠近,不同人在特徵空間里相距足夠遠直到超過某個閾值。(聽起來和triplet loss有點像)。
Contrastive loss引入了兩個信號,並通過兩個信號對網絡進行訓練。其中識別信號的表達式如下:
驗證信號的表達式如下:
基於這樣的信號,DeepID2在訓練的時候就不是以一張圖片為單位了,而是以Image Pair為單位,每次輸入兩張圖片,為同一人則為1,如果不是同一人則為-1.
(2)Triplet loss from FaceNet
這篇15年來自Google的FaceNet同樣是人臉識別領域分水嶺性質的工作。它提出了一個絕大部分人臉問題的統一解決框架,即:識別、驗證、搜索等問題都可以放到特徵空間里做,需要專註解決的僅僅是如何將人臉更好的映射到特徵空間。
Google在DeepID2的基礎上,拋棄了分類層即Classification Loss,將Contrastive Loss改進為Triplet loss,只為了一個目的:學習到更好的feature。
直接貼出Triplet loss的損失函數,其輸入的不再是Image Pair,而是三張圖片(Triplet),分別為Anchor Face, Negative Face和Positive Face。Anchor與Positive Face為同一人,與Negative Face為不同的人。那麼Triplet loss的損失函數即可表示為:
該式子的直觀解釋為:在特徵空間里Anchor與Positive的距離要小於Anchor與Negative的距離並超過一個Margin Alpha。他與Contrastive loss的直觀區別由下圖所示。
(3)Metric learning的問題
上述的兩個loss function效果很不錯,而且也符合人的客觀認知,在實際項目中也有大量的應用,但該方法仍有一些不足之處。
2. 對於Metric Learning不足進行修正的各種trick
(1)Finetune
參考論文:Deep Face Recognition
在論文《Deep Face Recognition》中,為了加快triplet loss的訓練,坐着先用softmax訓練人臉識別模型,然後移除頂層的classification layer,然後用triplet loss對模型進行特徵層finetune,在加速訓練的同時也取得了很不錯的效果。該方法也是現在訓練triplet loss時最常用的方法。
(2)對Triplet loss的修改
參考論文:In Defense of the Triplet Loss for Person Re-Identification
該作者說出了Triplet loss的缺點。對於Triplet loss訓練所需要的一個三元組,anchor(a)、positive(p)、negative(n)來說,需要從訓練集中隨機挑選。由於loss function的驅動,很有可能挑選出來的是很簡單的樣本組合,即很像的正樣本以及很不像的負樣本,而讓網絡一直在簡單樣本上進行學習,會限制網絡的范化能力。因此坐着修改了triplet loss並添加了新的trick,大量實驗證明,這種改進版的方法效果非常好。
在Google提供的facenet triplet loss訓練時,一旦選定B triplets集合,數據就會按照順序排好的3個一組,那麼總共的組合就有3B種,但是這些3B個圖像實際上有多達種有效的triplets組合,僅僅使用3B種就很浪費。
在該片論文中,作者提出了一個TriHard loss,其核心思想是在triplet loss的基礎上加入對hard example的處理:對於每一個訓練的batch, 隨機挑選P個ID的行人,每個行人隨機挑選K張不同的圖片,即一個batch含有P×K張圖片。之後對於batch中的每一張圖片a,我們可以挑選一個最難的正樣本和一個最難的負樣本和a組成一個三元組。首先我們定義和a為相同ID的圖片集為A,剩下不同ID的圖片圖片集為B,則TriHard損失表示為:
其中是人為設定的閾值參數。TriHard loss會計算a和batch中的每一張圖片在特徵空間的歐氏距離,然後選出與a距離最遠(最不像)的正樣本p和距離最近(最像)的負樣本n來計算三元組損失。其中d表示歐式距離。損失函數的另一種寫法如下:
另外,作者在輪中也提出了幾個實驗得到的觀點:
該方法考慮了hard example後效果比傳統的triplet loss好。
(3)對loss以及sample方法的修改
參考論文:Deep Metric Learning via Lifted Structured Feature Embedding
該論文首先提出了現有的三元組方法無法充分利用minibatch SGD training的training batches的優勢,創造性的將the vector of pairwise distances轉換成the matrix of pairwise distance,然後設計了一個新的結構化損失函數,取得了非常好的效果。如下圖所示,是contrastice embedding,triplet embedding以及lifted structured embedding三種方式的採樣示意圖。
直觀上看,lifted structured embedding涉及的分類模式更多,作者為了避免大量數據造成的訓練困難,作者在此基礎上給出了一個結構化的損失函數。如下圖所示。
其中P是正樣本集合,N是負樣本集合。可以看到對比上述的損失函數,該損失函數開始考慮一個樣本集合的問題。但是,並不是所有樣本對之間的negative edges都攜帶了有用的信息,也就是說隨機採樣的樣本對之間的negative edges攜帶了非常有限的信息,因此我們需要設計一種非隨機的採樣方法。
通過上述的結構化損失函數我們可以看到,在最終計算損失函數時,考慮了最像和最不像的hard pairs(也就是損失函數中max的用處),也就相當於在訓練過程中添加了difficult neighbors的信息了訓練mini-batch,通過這種方式訓練數據能夠大概率的搜尋到hard negatives和hard positives的樣本,而隨着訓練的不斷進行,對hard樣本的訓練也將實現最大化類間距離和最小化類內距離的目的。
如上圖所示,該文章在進行metric learning的時候並沒有隨機的選擇sample pairs,而是綜合了多類樣本之間較難區分者進行訓練。此外,文中還提到了以為的尋求max的過程或者尋求single hardest negative的過程會導致網絡收斂到一個bad local optimum,我猜想可能是因為max的截斷效應,使得梯度比較陡峭或者梯度間斷點過多。作者進一步改進了loss function,採用了smooth upper bound,即下式所示。
(4)對sample方式和對triplet loss的進一步修改
參考論文:Sampling Matters in Deep Embedding Learning
文章指出hard negative樣本由於anchor的距離較小,這是如果有噪聲,那麼這種採樣方式就很容易受到噪聲的影響,從而造成訓練時的模型坍塌。FaceNet曾經提出一種semi-hard negative mining的方法,它提出的方法是讓採樣的樣本不是太hard。但是根據作者的分析認為,sample應該在樣本中進行均勻的採樣,因此最佳的採樣狀態應該是在分散均勻的負樣本中,既有hard,又有semi-hard,又有easy的樣本,因此作者提出了一種新的採樣方法Distance weighted sampling。
在現實狀態下,我們隊所有的樣本進行兩兩採樣,計算其距離,最終得到點對距離的分佈有着如下的關係:
那麼根據給定的距離,通過上述函數的反函數就可以得到其採樣概率,根據該概率決定每個距離需要採樣的比例。給定一個anchor,採樣負例的概率為下式:
由於訓練樣本與訓練梯度強相關,因此作者也繪製出了採樣距離、採樣方法與數據梯度方差的關係,如下圖所示。從圖中可以看出,hard negative mining方法採樣的樣本都處於高方差的區域,如果數據集中有噪聲的話,採樣很容易受到噪聲的影響,從而導致模型坍塌。隨機採樣的樣本容易集中在低方差的區域,從而使得loss很小,但此時模型實際上並沒有訓練好。Semi-hard negative mining採樣的範圍很小,這很可能導致模型在很早的時候就收斂,loss下降很慢,但實際上此時模型也還沒訓練好;而本文提出的方法,能夠實現在整個數據集上均勻採樣。
作者在觀察constractive loss和triplet loss的時候發現一個問題,就是負樣本在非常hard的時候loss函數非常的平滑,那麼也就意味着梯度會很小,梯度小對於訓練來說就意味着非常hard的樣本不能充分訓練,網絡得不到hard樣本的有效信息,因此hard樣本的效果就會變差。所以如果在hard樣本周圍loss不是那麼平滑,也就是深度學習中經常用的導數為1(像relu一樣),那麼hard模式會不會就解決了梯度消失的問題。另外loss function還要實現triplet loss對正負樣本的兼顧,以及具備margin設計的功能,也就是自適應不同的數據分佈。損失函數如下:
我們稱anchor樣本與正例樣本之間的距離為正例對距離;稱anchor樣本與負例樣本之間的距離為負例對距離。公式中的參數beta定義了正例對距離與負例對距離之間的界限,如果正例對距離Dij大於beta,則損失加大;或者負例對距離Dij小於beta,損失加大。A控制樣本的分離間隔;當樣本為正例對時,yij為1,樣本為負例對時,yij為-1。下圖為損失函數曲線。
從上圖可以看出為什麼在非常hard的時候會出現梯度消失的情況,因為離0點近的時候藍色的線越來越平滑,梯度也就越來越小了。另外作者對的設置也進行了調優,加入了樣本偏置、類別偏置以及超參,對損失函數進一步優化,能夠根據訓練過程自動修改的值。
3. Margin Based Classification
Margin based classification不像在feature層直接計算損失的metric learning那樣對feature加直觀的強限制,是依然把人臉識別當 classification 任務進行訓練,通過對 softmax 公式的改造,間接實現了對 feature 層施加 margin 的限制,使網絡最後得到的 feature 更 discriminative。
(1)Center loss
參考論文:A Discriminative Feature Learning Approach for Deep Face Recognition
ECCV 2016的這篇文章主要是提出了一個新的Loss:Center Loss,用以輔助Softmax Loss進行人臉的訓練,為了讓同一個類別壓縮在一起,最終獲取更加discriminative的features。center loss意思即為:為每一個類別提供一個類別中心,最小化min-batch中每個樣本與對應類別中心的距離,這樣就可以達到縮小類內距離的目的。下圖為最小化樣本和類別中心距離的損失函數。
為每個batch中每個樣本對應的類別中心,和特徵的維度一樣,用歐式距離作為高維流形體距離表達。因此,在softmax的基礎上,center loss的損失函數為:
個人理解Center loss就如同在損失函數中加入了聚類的功能,隨着訓練的進行,樣本自覺地聚類在每一個batch的中心,進一步實現類間差異最大化。但是我覺得,對於高維特徵,歐氏距離並不能反映聚類的距離,因此這樣簡單的聚類並不能在高維上取得更好的效果。
(2)L-Softmax
原始的Softmax的目的是使得,將向量相乘的方式變換為向量的模與角度的關係,即,在這個基礎上,L-Softmax希望可以通過增加一個正整數變量m,可以看到:
使得產生的決策邊界可以更加嚴格地約束上述不等式,讓類內的間距更加的緊湊,讓類間的間距更加有區分性。所以基於上式和softmax的公式,可以得到L-softmax的公式為:
由於cos是減函數,所以乘以m會使得內積變小,最終隨着訓練,類本身之間的距離會增大。通過控制m的大小,可以看到類內和類間距離的變化,二維圖显示如下:
作者為了保障在反向傳播和推理過程中能夠滿足類別向量之間的角度都能夠滿足margin的過程,並保證單調遞減,因此構建了一種新的函數形式:
有人反饋L-Softmax調參難度較大,對m的調參需要反覆進行,才能達到更好的效果。
(3)Normface
參考論文:NormFace: L2 Hypersphere Embedding for Face Verification
這篇論文是一篇很有意思的文章,文章對於權重與特徵歸一化做了很多有意思的探討。文章提出,sphereface雖然好,但是它不優美。在測試階段,sphereface通過特徵間的餘弦值來衡量相似性,即以角度為相似性度量。但在訓練過程中也有一個問題,權重沒有歸一化,loss function在訓練過程中減小的同時,會使得權重的模越來越大,所以sphereface損失函數的優化方向並不是很嚴謹,其實優化的方向還有一部分去增大特徵的長度了。有博主做實驗發現,隨着m的增大,坐標的尺度也在不斷增大,如下圖所示。
因此作者在優化的過程中,對特徵做了歸一化處理。相應的損失函數也如下所示:
其中W和f都為歸一化的特徵,兩個點積就是角度餘弦值。參數s的引入是因為數學上的性質,保證了梯度大小的合理性,原文中有比較直觀的解釋,可以閱讀原論文,並不是重點。s既可以變成可學習的參數,也可以變成超參,論文作者給了很多推薦值,可以在論文中找到。其實,FaceNet中歸一化的歐氏距離,和餘弦距離是統一的。
4. AM-softmax/CosFace
參考論文:Additive Margin Softmax for Face Verification
CosFace: Large Margin Cosine Loss for Deep Face Recognition
看上面的論文,會發現少了一個東西,那就是margin,或者說是margin的意味少了一些,所以AM-softmax在歸一化的基礎上有引入了margin。損失函數如下:
直觀上來看,-m比更小,所以損失函數值比Normface里的更大,因此有了margin的感覺。m是一個超參數,控制懲罰,當m越大,懲罰越強。該方法好的一點是容易復現,而且沒有很多調參的tricks,效果也很好。
(1)ArcFace
與 AM-softmax 相比,區別在於 Arcface 引入 margin 的方式不同,損失函數:
乍一看是不是和 AM-softmax一樣?注意 m 是在餘弦裏面。文章指出基於上式優化得到的特徵間的 boundary 更為優越,具有更強的幾何解釋。
然而這樣引入 margin 是否會有問題?仔細想 cos(θ+m) 是否一定比 cos(θ) 小?
最後我們用文章中的圖來解釋這個問題,並且也由此做一個本章 Margin-based Classification 部分的總結。
這幅圖出自於 Arcface,橫坐標為 θ 為特徵與類中心的角度,縱坐標為損失函數分子指數部分的值(不考慮 s),其值越小損失函數越大。
看了這麼多基於分類的人臉識別論文,相信你也有種感覺,大家似乎都在損失函數上做文章,或者更具體一點,大家都是在討論如何設計上圖的 Target logit-θ 曲線。
這個曲線意味着你要如何優化偏離目標的樣本,或者說,根據偏離目標的程度,要給予多大的懲罰。兩點總結:
1. 太強的約束不容易泛化。例如 Sphereface 的損失函數在 m=3 或 4 的時候能滿足類內最大距離小於類間最小距離的要求。此時損失函數值很大,即 target logits 很小。但並不意味着能泛化到訓練集以外的樣本。施加太強的約束反而會降低模型性能,且訓練不易收斂。
2. 選擇優化什麼樣的樣本很重要。Arcface 文章中指出,給予 θ∈[60° , 90°] 的樣本過多懲罰可能會導致訓練不收斂。優化 θ ∈ [30° , 60°] 的樣本可能會提高模型準確率,而過分優化 θ∈[0° , 30°] 的樣本則不會帶來明顯提升。至於更大角度的樣本,偏離目標太遠,強行優化很有可能會降低模型性能。
這也回答了上一節留下的疑問,上圖曲線 Arcface 後面是上升的,這無關緊要甚至還有好處。因為優化大角度的 hard sample 可能沒有好處。這和 FaceNet 中對於樣本選擇的 semi-hard 策略是一個道理。
1. A discriminative feature learning approach for deep face recognition [14]
提出了 center loss,加權整合進原始的 softmax loss。通過維護一個歐式空間類中心,縮小類內距離,增強特徵的 discriminative power。
2. Large-margin softmax loss for convolutional neural networks [10]
Sphereface 作者的前一篇文章,未歸一化權重,在 softmax loss 中引入了 margin。裏面也涉及到 Sphereface 的訓練細節。
人臉識別算法實現解釋
本文我們部署的人臉識別算法模型主要包括兩部分:
如下圖所示,整體算法實現的流程分為線下和線上兩個部分,在每次對不同的人進行識別之前首先利用訓練好的算法生成人臉標準底庫,將底庫數據保存在modelarts上。然後在每次推理的過程中,圖片輸入會經過人臉檢測模型和人臉識別模型得到人臉特徵,然後基於該特徵在底庫中搜索相似對最高的特徵,完成人臉識別的過程。
在實現過程中,我們採用了基於Retinaface+resnet50+arcface的算法完成人臉圖像的特徵提取,其中Retinaface作為檢測模型,resnet50+arcface作為特徵提取模型。
在鏡像中,運行訓練的腳本有兩個,分別對應人臉檢測的訓練和人臉識別的訓練。
run_face_detection_train.sh
該腳本的啟動命令為
sh run_face_detection_train.sh data_path model_output_path
其中model_output_path為模型輸出的路徑,data_path為人臉檢測訓練集的輸入路徑,輸入的圖片路徑結構如下:
detection_train_data/ train/ images/ label.txt val/ images/ label.txt test/ images/ label.txt
run_face_recognition_train.sh
該腳本的啟動命令為
sh run_face_recognition_train.sh data_path model_output_path
其中model_output_path為模型輸出的路徑,data_path為人臉檢測訓練集的輸入路徑,輸入的圖片路徑結構如下:
recognition_train_data/
cele.idx
cele.lst
cele.rec
property
run_generate_data_base.sh
該腳本的啟動命令為:
sh run_generate_data_base.sh data_path detect_model_path recognize_model_path db_output_path
其中data_path為底庫輸入路徑,detect_model_path為檢測模型輸入路徑,recognize_model_path為識別模型輸入路徑,db_output_path為底庫輸出路徑。
run_face_recognition.sh
該腳本的啟動命令為:
sh run_generate_data_base.sh data_path db_path detect_model_path recognize_model_path
其中data_path為測試圖片輸入路徑,db_path為底庫路徑,detect_model_path為檢測模型的輸入路徑,recognize_model_path為識別模型的輸入路徑
華為雲ModelArts有訓練作業的功能,可以用來作模型訓練以及對模型訓練的參數和版本進行管理。這個功能對於多版本迭代開發的開發者有一定的幫助。訓練作業中有預置的一些鏡像和算法,當前對於常用的框架均有預置鏡像(包括Caffe, MXNet, Pytorch, TensorFlow )和華為自己的昇騰芯片的引擎鏡像(Ascend-Powered-Engine)。
本文我們會基於ModelArts的自定義鏡像特性,上傳自己在本機調試完畢的完整鏡像,利用華為雲的GPU資源訓練模型。
我們是想在華為雲上的ModelArts基於網站上常見的明星的數據訓練完成一個人臉識別模型。在這個過程中,由於人臉識別網絡是工程師自己設計的網絡結構,所以需要通過自定義鏡像進行上傳。所以整個人臉訓練的過程分為以下九步:
構建本地Docker環境
Docker環境可以在本地計算機進行構建,也可以在華為雲上購買一台彈性雲服務器進行Docker環境構建。全過程參考Docker官方的文檔進行:
https://docs.docker.com/engine/install/binaries/#install-static-binaries
從華為雲下載基礎鏡像
官網說明網址:
https://support.huaweicloud.com/engineers-modelarts/modelarts_23_0085.html#modelarts_23_0085__section19397101102
我們訓練需要使用到的是MXNet的環境,首先需要從華為雲上下載相對應的自定義鏡像的基礎鏡像。官網給出的下載命令如下:
在訓練作業基礎鏡像的規範里,找到了這個命令的解釋。
https://support.huaweicloud.com/engineers-modelarts/modelarts_23_0217.html
根據我們的腳本要求,我使用的是cuda9的鏡像:
官方還給出了另一種方法,就是使用docker file的。基礎鏡像的dockerfile也是在訓練作業基礎鏡像的規範里找到的。可以參考一下的dockerfile:
https://github.com/huaweicloud/ModelArts-Lab/tree/master/docs/custom_image/custom_base
根據自己需求構建自定義鏡像環境
由於比較懶,所以還是沒有使用Dockerfile的方式自己構建鏡像。我採用的是另一種方式!
因為我們的需求就是cuda 9 還有一些相關的python依賴包,假設官方的鏡像提供的是cuda 9的,我們大可以在訓練腳本中跟着這個教程加一個requirement.txt。簡單高效快捷就能解決需求!!!下面是教程~~~
https://support.huaweicloud.com/modelarts_faq/modelarts_05_0063.html
上傳自定義鏡像到SWR
官網教程:
上傳鏡像的頁面寫着,文件解壓后不得超過2GB。但是官方提供的基礎鏡像就3.11GB,我們加上需要的預訓練的模型後鏡像是5+GB,所以不能使用頁面進行上傳的工作,必須使用客戶端。上傳鏡像首先要創建組織,
如果覺得產品文檔理解還是比較難,可以嘗試一下SWR頁面的pull/push鏡像體驗:
這裏後面引導了客戶如何將本地鏡像推上雲端,第一步是登陸倉庫:
第二步拉取鏡像,這個我們就用自己打的自定義鏡像代替,
第三步修改組織,使用根據產品文檔創建的組織名。在這一步需要將本地的一個鏡像重命名為雲上識別的鏡像命。具體看下圖解釋:
第四步推送鏡像,
當熟練掌握這四步技巧的時候,可以脫離這個教程,使用客戶端進行上傳。使用客戶端登陸然後上傳。客戶端登陸可以使用生成臨時docker loging指令。這個頁面在”我的鏡像“-> ”客戶端上傳“->”生成臨時docker login指令“中:
在本地docker環境中,使用這個生成的臨時docker login指令登陸后,使用下面的命令進行上傳鏡像:
華為雲ModelArts提供訓練作業給用戶進行模型訓練。在訓練作業中有預置鏡像和可以選擇自定義鏡像。預置的鏡像包含市面上大部分框架,沒有特殊要求的時候,使用這些框架的鏡像進行訓練也是很方便的。本次測試還是使用的自定義鏡像。
自定義鏡像中不僅需要在鏡像中進行配置自己的環境,假如改變了訓練作業啟動的方式,還需要修改訓練的啟動腳本。從華為雲ModelArts官網拉取下來的官方鏡像的/home/work/路徑下有一個啟動腳本”run_train.sh”,自定義的啟動腳本需要基於這個腳本進行修改。主要是要注意 “dls_get_app”,這個是從OBS下載相關的命令。其他的部分根據自己的訓練腳本進行修改。
如果需要上傳訓練結果或者模型到OBS,需要參考”dls_get_app”加”dls_upload_model”的命令。在我們這次訓練中,上傳的腳本如下:
訓練作業進行調試的時候,當前可以使用免費提供的一小時V100。ModelArts的訓練作業一個比較好的地方是方便了我們版本管理。版本中會記錄所有通過運行參數傳入到訓練腳本里的所有參數,還可以使用版本對比進行參數對比。還有個比較方便的地方是可以基於某一個版本進行修改,減少了重新輸入所有參數這一步驟,比較方便調試。
在訓練作業中訓練完成后,還可以在ModelArts中進行模型部署上線。
目前針對人臉識別算法的優化已經到達一個瓶頸期,但是在技術層面針對人臉面部結構的相似性、人臉的姿態、年齡變化、複雜環境的光照變化、人臉的飾物遮擋等還面臨這很多的問題,因此基於多種算法技術的融合解決人臉識別中的各種問題仍然在安防、互聯網中有着巨大的市場。另外,隨着人臉支付的逐漸完善,人臉識別系統也應用於銀行、公安系統、商場等等,因此人臉識別的安全問題和防攻擊問題也是一個亟待解決的問題,例如活體檢測、3D面部識別等等。
最後,人臉識別作為目前深度學習中應用比較成熟的項目,其發展還與深度學習本身技術發展息息相關,目前在很多優化上,深度學習最大的缺點是沒有相應的數學理論支撐,優化所提升的性能也很有限,因此對深度學習算法本身的研究也是未來的重點。
點擊關注,第一時間了解華為雲新鮮技術~
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※台北網頁設計公司全省服務真心推薦
※想知道最厲害的網頁設計公司"嚨底家"!
※推薦評價好的iphone維修中心
※網頁設計最專業,超強功能平台可客製化
※別再煩惱如何寫文案,掌握八大原則!
什麼是async/await?
await和async是.NET Framework4.5框架、C#5.0語法裏面出現的技術,目的是用於簡化異步編程模型。
async和await的關係?
async和await是成對出現的。
async出現在方法的聲明裡,用於批註一個異步方法。光有async是沒有意義的。
await出現在方法內部,Task前面。只能在使用async關鍵字批註的方法中使用await關鍵字。
private async Task DoSomething()
{
await Task.Delay(TimeSpan.FromSeconds(10));
}
async/await會創建新的線程嗎?
不會。async/await關鍵字本身是不會創建新的線程的,但是被await的方法內部一般會創建新的線程。
asp.net mvc/webapi action中使用async/await會提高請求的響應速度嗎?
不會。
我們都知道web應用不同於winform、wpf等客戶端應用,客戶端應用為了保證UI渲染的一致性往往都是採用單線程模式,這個UI線程稱為主線程,如果在主線程做耗時操作就會導致程序界面假死,所以客戶端開發中使用多線程異步編程非常必要。
可web應用本身就是多線程模式,服務器會為每個請求分配工作線程。
既然async/await不能創建新線程,又不能使提高請求的響應速度,那.NET Web應用中為什麼要使用async/await異步編程呢?
在 web 服務器上,.NET Framework 維護用於處理 ASP.NET 請求的線程池。 當請求到達時,將調度池中的線程以處理該請求。 如果以同步方式處理請求,則處理請求的線程將在處理請求時處於繁忙狀態,並且該線程無法處理其他請求。
在啟動時看到大量併發請求的 web 應用中,或具有突發負載(其中併發增長突然增加)時,使 web 服務調用異步會提高應用程序的響應能力。 異步請求與同步請求所需的處理時間相同。 如果請求發出需要兩秒鐘時間才能完成的 web 服務調用,則該請求將需要兩秒鐘,無論是同步執行還是異步執行。 但是,在異步調用期間,線程在等待第一個請求完成時不會被阻止響應其他請求。 因此,當有多個併發請求調用長時間運行的操作時,異步請求會阻止請求隊列和線程池的增長。
下面用代碼來實際測試一下:
public ActionResult Index()
{
DateTime startTime = DateTime.Now;//進入DoSomething方法前的時間
var startThreadId = Thread.CurrentThread.ManagedThreadId;//進入DoSomething方法前的線程ID
DoSomething();//耗時操作
DateTime endTime = DateTime.Now;//完成DoSomething方法的時間
var endThreadId = Thread.CurrentThread.ManagedThreadId;//完成DoSomething方法后的線程ID
return Content($"startTime:{ startTime.ToString("yyyy-MM-dd HH:mm:ss:fff") } startThreadId:{ startThreadId }<br/>endTime:{ endTime.ToString("yyyy-MM-dd HH:mm:ss:fff") } endThreadId:{ endThreadId }<br/><br/>");
}
/// <summary>
/// 耗時操作
/// </summary>
/// <returns></returns>
private void DoSomething()
{
Thread.Sleep(10000);
}
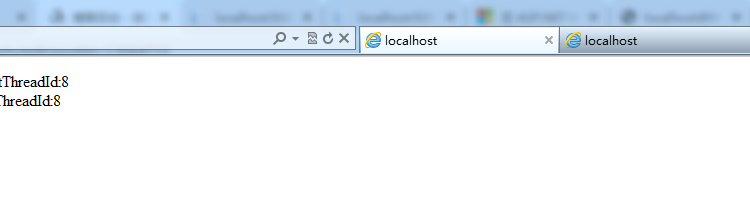
使用瀏覽器開3個標籤頁進行測試(因為瀏覽器對同一域名下的連接數有限制,一般是6個左右,所以就弄3個吧):
可以看到耗時都是10秒,開始和結束的線程ID一致。
public async Task<ActionResult> Index()
{
DateTime startTime = DateTime.Now;//進入DoSomething方法前的時間
var startThreadId = Thread.CurrentThread.ManagedThreadId;//進入DoSomething方法前的線程ID
await DoSomething();//耗時操作
DateTime endTime = DateTime.Now;//完成DoSomething方法的時間
var endThreadId = Thread.CurrentThread.ManagedThreadId;//完成DoSomething方法后的線程ID
return Content($"startTime:{ startTime.ToString("yyyy-MM-dd HH:mm:ss:fff") } startThreadId:{ startThreadId }<br/>endTime:{ endTime.ToString("yyyy-MM-dd HH:mm:ss:fff") } endThreadId:{ endThreadId }<br/><br/>");
}
/// <summary>
/// 耗時操作
/// </summary>
/// <returns></returns>
private async Task DoSomething()
{
await Task.Run(() => Thread.Sleep(10000));
}
結果:
可以看到3次請求中,雖然耗時都是10秒,但是出現了開始和結束的線程ID不一致的情況,ID為22的這個線程工作了多次,這意味着使用異步方式在同一時間可以處理更多的請求!(這句話不太對,3個同步的併發請求必然會分配3個工作線程,但是使用異步的話,同一個線程可以被多個請求重複利用。因為線程池的線程數量是有上限的,所以在相同數量的線程下,使用異步方式能處理更多的請求。)
IIS默認隊列長度:
await關鍵字不會阻塞線程直到任務完成。 它將方法的其餘部分註冊為任務的回調,並立即返回。 當await的任務最終完成時,它將調用該回調,並因此在其中斷時繼續執行方法。
簡單來說:就是使用同步方法時,線程會被耗時操作一直佔有,直到耗時操作完成。而使用異步方法,程序走到await關鍵字時會立即return,釋放線程,餘下的代碼會放進一個回調中(Task.GetAwaiter()的UnsafeOnCompleted(Action)回調),耗時操作完成時才會回調執行,所以async/await是語法糖,其本質是一個狀態機。
那是不是所有的action都要用async/await呢?
不是。一般的磁盤IO或者網絡請求等耗時操作才考慮使用異步,不要為了異步而異步,異步也是需要消耗性能的,使用不合理會適得其反。
async/await異步編程不能提升響應速度,但是可以提升響應能力(吞吐量)。異步和同步各有優劣,要合理選擇,不要為了異步而異步。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
※網頁設計最專業,超強功能平台可客製化
※別再煩惱如何寫文案,掌握八大原則!
首先來介紹下什麼是優雅地停止,簡而言之,就是對應用進程發送停止指令之後,能保證正在執行的業務操作不受影響,可以繼續完成已有請求的處理,但是停止接受新請求。
在 Spring Boot 2.3 中增加了新特性優雅停止,目前 Spring Boot 內置的四個嵌入式 Web 服務器(Jetty、Reactor Netty、Tomcat 和 Undertow)以及反應式和基於 Servlet 的 Web 應用程序都支持優雅停止。
下面,我們先用新版本嘗試下:
首先創建一個 Spring Boot 的 Web 項目,版本選擇 2.3.0.RELEASE,Spring Boot 2.3.0.RELEASE 版本內置的 Tomcat 為 9.0.35。
然後需要在 application.yml 中添加一些配置來啟用優雅停止的功能:
# 開啟優雅停止 Web 容器,默認為 IMMEDIATE:立即停止
server:
shutdown: graceful
# 最大等待時間
spring:
lifecycle:
timeout-per-shutdown-phase: 30s
其中,平滑關閉內置的 Web 容器(以 Tomcat 為例)的入口代碼在 org.springframework.boot.web.embedded.tomcat 的 GracefulShutdown 里,大概邏輯就是先停止外部的所有新請求,然後再處理關閉前收到的請求,有興趣的可以自己去看下。
內嵌的 Tomcat 容器平滑關閉的配置已經完成了,那麼如何優雅關閉 Spring 容器了,就需要 Actuator 來實現 Spring 容器的關閉了。
然後加入 actuator 依賴,依賴如下所示:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
然後接着再添加一些配置來暴露 actuator 的 shutdown 接口:
# 暴露 shutdown 接口
management:
endpoint:
shutdown:
enabled: true
endpoints:
web:
exposure:
include: shutdown
其中通過 Actuator 關閉 Spring 容器的入口代碼在 org.springframework.boot.actuate.context 包下 ShutdownEndpoint 類中,主要的就是執行 doClose() 方法關閉並銷毀 applicationContext,有興趣的可以自己去看下。
配置搞定后,然後在 controller 包下創建一個 WorkController 類,並有一個 work 方法,用來模擬複雜業務耗時處理流程,具體代碼如下:
@RestController
public class WorkController {
@GetMapping("/work")
public String work() throws InterruptedException {
// 模擬複雜業務耗時處理流程
Thread.sleep(10 * 1000L);
return "success";
}
}
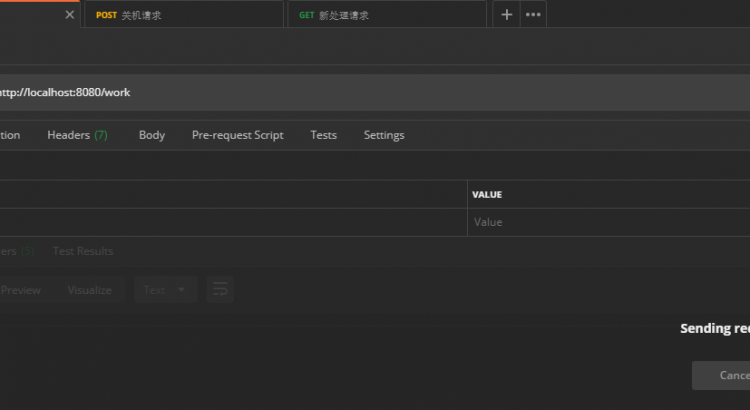
然後,我們啟動項目,先用 Postman 請求 http://localhost:8080/work 處理業務:
然後在這個時候,調用 http://localhost:8080/actuator/shutdown 就可以執行優雅地停止,返回結果如下:
{
"message": "Shutting down, bye..."
}
如果在這個時候,發起新的請求 http://localhost:8080/work,會沒有反應:
再回頭看第一個請求,返回了結果:success。
其中有幾條服務日誌如下:
2020-05-20 23:05:15.163 INFO 102724 --- [ Thread-253] o.s.b.w.e.tomcat.GracefulShutdown : Commencing graceful shutdown. Waiting for active requests to complete
2020-05-20 23:05:15.287 INFO 102724 --- [tomcat-shutdown] o.s.b.w.e.tomcat.GracefulShutdown : Graceful shutdown complete
2020-05-20 23:05:15.295 INFO 102724 --- [ Thread-253] o.s.s.concurrent.ThreadPoolTaskExecutor : Shutting down ExecutorService 'applicationTaskExecutor'
從日誌中也可以看出來,當調用 shutdown 接口的時候,會先等待請求處理完畢后再優雅地停止。
到此為止,Spring Boot 2.3 的優雅關閉就講解完了,是不是很簡單呢?如果是在之前不支持優雅關閉的版本如何去做呢?
在這裏介紹 GitHub 上 issue 里 Spring Boot 開發者提供的一種方案:
選取的 Spring Boot 版本為 2.2.6.RELEASE,首先要實現 TomcatConnectorCustomizer 接口,該接口是自定義 Connector 的回調接口:
@FunctionalInterface
public interface TomcatConnectorCustomizer {
void customize(Connector connector);
}
除了定製 Connector 的行為,還要實現 ApplicationListener<ContextClosedEvent> 接口,因為要監聽 Spring 容器的關閉事件,即當前的 ApplicationContext 執行 close() 方法,這樣我們就可以在請求處理完畢後進行 Tomcat 線程池的關閉,具體的實現代碼如下:
@Bean
public GracefulShutdown gracefulShutdown() {
return new GracefulShutdown();
}
private static class GracefulShutdown implements TomcatConnectorCustomizer, ApplicationListener<ContextClosedEvent> {
private static final Logger log = LoggerFactory.getLogger(GracefulShutdown.class);
private volatile Connector connector;
@Override
public void customize(Connector connector) {
this.connector = connector;
}
@Override
public void onApplicationEvent(ContextClosedEvent event) {
this.connector.pause();
Executor executor = this.connector.getProtocolHandler().getExecutor();
if (executor instanceof ThreadPoolExecutor) {
try {
ThreadPoolExecutor threadPoolExecutor = (ThreadPoolExecutor) executor;
threadPoolExecutor.shutdown();
if (!threadPoolExecutor.awaitTermination(30, TimeUnit.SECONDS)) {
log.warn("Tomcat thread pool did not shut down gracefully within 30 seconds. Proceeding with forceful shutdown");
}
} catch (InterruptedException ex) {
Thread.currentThread().interrupt();
}
}
}
}
有了定製的 Connector 回調,還需要在啟動過程中添加到內嵌的 Tomcat 容器中,然後等待監聽到關閉指令時執行,addConnectorCustomizers 方法可以把定製的 Connector 行為添加到內嵌的 Tomcat 中,具體代碼如下:
@Bean
public ConfigurableServletWebServerFactory tomcatCustomizer() {
TomcatServletWebServerFactory factory = new TomcatServletWebServerFactory();
factory.addConnectorCustomizers(gracefulShutdown());
return factory;
}
到此為止,內置的 Tomcat 容器平滑關閉的操作就完成了,Spring 容器優雅停止上面已經說過了,再次就不再贅述了。
通過測試,同樣可以達到上面那樣優雅停止的效果。
本文主要講解了 Spring Boot 2.3 版本和舊版本的優雅停止,避免強制停止導致正在處理的業務邏輯會被中斷,進而導致產生業務異常的情形。
另外使用 Actuator 的同時要注意安全問題,比如可以通過引入 security 依賴,打開安全限制並進行身份驗證,設置單獨的 Actuator 管理端口並配置只對內網開放等。
本文的完整代碼在 https://github.com/wupeixuan/SpringBoot-Learn 的 graceful-shutdown 目錄下。
最好的關係就是互相成就,大家的在看、轉發、留言三連就是我創作的最大動力。
參考
https://github.com/spring-projects/spring-boot/issues/4657
https://github.com/wupeixuan/SpringBoot-Learn
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計最專業,超強功能平台可客製化
※回頭車貨運收費標準
遇到這樣一個疑問:當where查詢中In一個索引字段作為條件,那麼在查詢中還會使用到索引嗎?
SELECT * FROM table_name WHERE column_index in (expr)
上面的sql語句檢索會使用到索引嗎?帶着這個問題,在網上查找了很多文章,但是有的說 in 會導致放棄索引,全表掃描;有的說Mysql5.5之前的版本不會走,之後的innodb版本會走索引…
越看越迷糊,那答案到底是怎樣的呢?
唯有實踐是檢驗真理的唯一方式!
拿出我們的利刃——EXPLAIN,去剖析 SELECT 語句,一探究竟!
在 SELECT 語句前加上 EXPLAIN 就可以了 ,例如:
EXPLAIN SELECT * FROM table_name [WHERE Clause]
EXPLAIN 命令的輸出內容為一個表格形式,表的每一個字段含義如下:
| 列名 | 解釋 |
|---|---|
| id | SELECT 查詢的標識符. 每個 SELECT 都會自動分配一個唯一的標識符 |
| select_type | SELECT 查詢的類型 |
| table | 查詢的是哪個表 |
| partitions | 匹配的分區 |
| type | join 類型 |
| possible_keys | 此次查詢中可能選用的索引 |
| key | 此次查詢中確切使用到的索引 |
| ref | 哪個字段或常數與 key 一起被使用;與索引比較的列 |
| rows | 显示此查詢一共掃描了多少行, 這個是一個估計值 |
| filtered | 表示此查詢條件所過濾的數據的百分比 |
| extra | 額外的信息 |
| 查詢類型 | 解釋 |
|---|---|
| SIMPLE | 表示此查詢不包含 UNION 查詢或子查詢 |
| PRIMARY | 表示此查詢是最外層的查詢 |
| UNION | 表示此查詢是 UNION 的第二或隨後的查詢 |
| DEPENDENT UNION | UNION 中的第二個或後面的查詢語句, 取決於外面的查詢 |
| UNION RESULT | UNION 的結果 |
| SUBQUERY | 子查詢中的第一個 SELECT |
| DEPENDENT SUBQUERY | 子查詢中的第一個 SELECT,取決於外面的查詢。子查詢依賴於外層查詢的結果 |
| MATERIALIZED | Materialized subquery |
表示查詢涉及的表或衍生表 。 這也可以是以下值之一:
查詢將匹配記錄的分區。該值適用NULL於未分區的表。
聯接類型。 提供了判斷查詢是否高效的重要依據依據。通過 type 字段,我們判斷此次查詢是全表掃描還是索引掃描等。 從最佳類型到最差類型:
system: 該表只有一行(=系統表)。這是const聯接類型的特例 。
const: 針對主鍵或唯一索引的等值查詢掃描,最多只返回一行數據。const 查詢速度非常快,因為它僅僅讀取一次即可 。
SELECT * FROM tbl_name WHERE primary_key=1;
SELECT * FROM tbl_name
WHERE primary_key_part1=1 AND primary_key_part2=2;
eq_ref: 此類型通常出現在多表的 join 查詢,表示對於前表的每一個結果,都只能匹配到后表的一行結果。並且查詢的比較操作通常是 =,查詢效率較高
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;
ref : 此類型通常出現在多表的 join 查詢,針對於非唯一或非主鍵索引,或者是使用了最左前綴規則索引的查詢。ref可以用於使用=或<=> 運算符進行比較的索引列。
SELECT * FROM ref_table WHERE key_column=expr;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;
ref_or_null: 這種連接類型類似於 ref,但是除了MySQL會額外搜索包含NULL值的行。此聯接類型優化最常用於解析子查詢。
SELECT * FROM ref_table
WHERE key_column=expr OR key_column IS NULL;
unique_subquery: 只是一個索引查找函數,它完全替代了子查詢以提高效率。
value IN (SELECT primary_key FROM single_table WHERE some_expr)
index_subquery:此連接類型類似於 unique_subquery。它代替IN子查詢,但適用於以下形式的子查詢中的非唯一索引。
range: 表示使用索引範圍查詢, 通過索引字段範圍獲取表中部分數據記錄。這個類型通常出現在 =,<>,>,>=,<,<=,IS NULL,<=>,BETWEEN,IN() 操作中。
當 type 是 range 時,那麼 EXPLAIN 輸出的 ref 字段為 NULL,並且 key_len 字段是此次查詢中使用到的索引的最長的那個 。
SELECT * FROM tbl_name
WHERE key_column = 10;
SELECT * FROM tbl_name
WHERE key_column BETWEEN 10 and 20;
SELECT * FROM tbl_name
WHERE key_column IN (10,20,30);
SELECT * FROM tbl_name
WHERE key_part1 = 10 AND key_part2 IN (10,20,30);
index: 表示全索引掃描(full index scan)和 ALL 類型類似,只不過 ALL 類型是全表掃描,而 index 類型則僅僅掃描所有的索引,而不掃描數據。
index 類型通常出現在: 所要查詢的數據直接在索引樹中就可以獲取到,而不需要掃描數據。當是這種情況時,Extra 字段 會显示 Using index
ALL: 表示全表掃描,這個類型的查詢是性能最差的查詢之一。
我們的查詢不應該出現 ALL 類型的查詢,因為這樣的查詢在數據量大的情況下,對數據庫的性能是巨大的災難。如一個查詢是 ALL 類型查詢,那麼一般來說可以對相應的字段添加索引來避免 。
表示 MySQL 在查詢時,能夠使用到的索引。
即使有些索引在 possible_keys 中出現,但是並不表示此索引會真正地被 MySQL 使用到。MySQL 在查詢時具體使用了哪些索引,由 key 字段決定。
是 MySQL 在當前查詢時所真正使用到的索引。
表示查詢優化器使用了索引的字節數。
這個字段可以評估組合索引是否完全被使用,或只有最左部分字段被使用到。key_len 的計算規則如下:
查詢優化器根據統計信息,估算 SQL 要查找到結果集需要掃描讀取的數據行數。這個值非常直觀显示 SQL 的效率好壞,原則上 rows 越少越好。
這個 rows 就是 mysql 認為必須要逐行去檢查和判斷的記錄的條數。舉個例子來說,假如有一個語句 select * from t where column_a = 1 and column_b = 2; 全表假設有 100 條記錄,column_a 字段有索引(非聯合索引),column_b沒有索引。column_a = 1 的記錄有 20 條, column_a = 1 and column_b = 2 的記錄有 5 條。
EXplain 中的很多額外的信息會在 Extra 字段显示,常見的有以下幾種內容:
說到最後,那 WHERE column_index in (expr) 到底走不走索引呢? 答案是不確定的。
走不走索引是由 expr 來決定的,不是一概而論走還是不走。
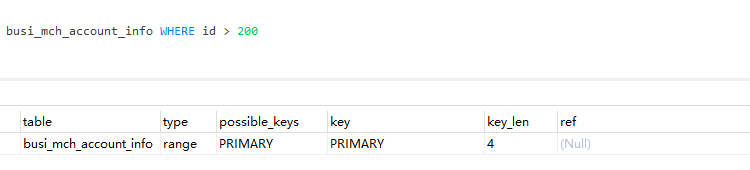
SELECT * FROM a WHERE id in (1,23,456,7,8)
-- id 是主鍵,查詢是走索引的。type = range,key = PRIMARY
SELECT * FROM a WHERE id in (SELECT b.a_id FROM b WHERE some_expr)
-- id 是主鍵,如果 some_expr 是一個索引查詢,那麼 select a 將走索引;
-- some_expr 不是索引查詢,那麼 select a 將全表掃描;
上面是兩個通用案例,但到底對不對了,還是自己去實踐最好了,拿起EXPLAIN去剖析吧~
參考文章: https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!