環境資訊中心綜合外電;姜唯 編譯;林大利 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?
目錄
小師妹已經學完JVM的簡單部分了,接下來要進入的是JVM中比較晦澀難懂的概念,這些概念是那麼的枯燥乏味,甚至還有點惹人討厭,但是要想深入理解JVM,這些概念是必須的,我將會盡量嘗試用簡單的例子來解釋它們,但一定會有人看不懂,沒關係,這個系列本不是給所有人看的。
更多精彩內容且看:
小師妹:F師兄,我的基礎已經打牢了嗎?可以進入這麼複雜的內容環節了嗎?
小師妹不試試怎麼知道不行呢?了解點深入內容可以幫助你更好的理解之前的知識。現在我們開始吧。
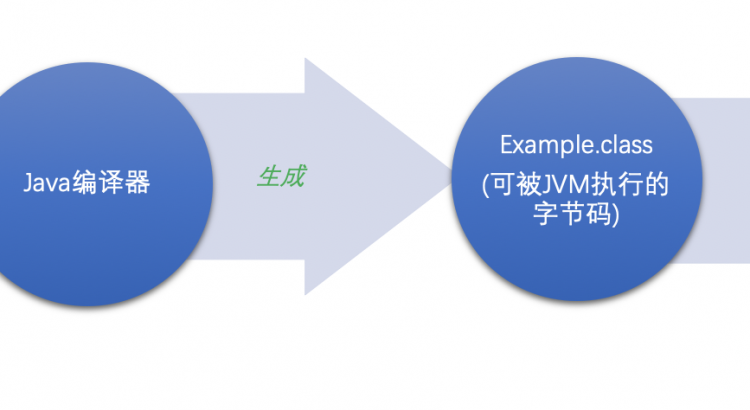
上次我們在講java程序的處理流程的時候,還記得那通用的幾步吧。
小師妹:當然記得了,編寫源代碼,javac編譯成字節碼,加載到JVM中執行。
對,其實在JVM的執行引擎中,有三個部分:解釋器,JIT編譯器和垃圾回收器。
解釋器會將前面編譯生成的字節碼翻譯成機器語言,因為每次都要翻譯,相當於比直接編譯成機器碼要多了一步,所以java執行起來會比較慢。
為了解決這個問題,JVM引入了JIT(Just-in-Time)編譯器,將熱點代碼編譯成為機器碼。
小師妹你知道嗎?在JDK8之前,HotSpot VM又分為三種。分別是 client VM, server VM, 和 minimal VM,分別用在客戶端,服務器,和嵌入式系統。
但是隨着硬件技術的發展,這些硬件上面的限制都不是什麼大事了。所以從JDK8之後,已經不再區分這些VM了,現在統一使用VM的實現來替代他們。
小師妹,你覺得Client VM和Server VM的本質區別在哪一部分呢?
小師妹,編譯成字節碼應該都是使用javac,都是同樣的命令,字節碼上面肯定是一樣的。難點是在執行引擎上面的不同?
說的對,因為Client VM和Server VM的出現,所以在JIT中出現了兩種不同的編譯器,C1 for Client VM, C2 for Server VM。
因為javac的編譯只能做少量的優化,其實大量的動態優化是在JIT中做的。C2相對於C1,其優化的程度更深,更加激進。
為了更好的提升編譯效率,JVM在JDK7中引入了分層編譯Tiered compilation的概念。
對於JIT本身來說,動態編譯是需要佔用用戶內存空間的,有可能會造成較高的延遲。
對於Server服務器來說,因為代碼要服務很多個client,所以磨刀不誤砍柴工,短暫的延遲帶來永久的收益,聽起來是可以接受的。
Server端的JIT編譯也不是立馬進行的,它可能需要收集到足夠多的信息之後,才進行編譯。
而對於Client來說,延遲帶來的性能影響就需要進行考慮了。和Server相比,它只進行了簡單的機器碼的編譯。
為了滿足不同層次的編譯需求,於是引入了分層編譯的概念。
大概來說分層編譯可以分為三層:
在JDK7中,你可以使用下面的命令來開啟分層編譯:
-XX:+TieredCompilation
而在JDK8之後,恭喜你,分層編譯已經是默認的選項了,不用再手動開啟。
小師妹:F師兄,你剛剛講到Server的JIT不是立馬就進行編譯的,它會等待一定的時間來搜集所需的信息,那麼代碼不是要從字節碼轉換成機器碼?
對的,這個過程就叫做OSR(On-Stack Replacement)。為什麼叫OSR呢?我們知道JVM的底層實現是一個棧的虛擬機,所以這個替換實際上是一系列的Stack操作。
上圖所示,m1方法從最初的解釋frame變成了後面的compiled frame。
這個世界是平衡的,有陰就有陽,有優化就有反優化。
小師妹:F師兄,為什麼優化了之後還要反優化呢?這樣對性能不是下降了嗎?
通常來說是這樣的,但是有些特殊的情況下面,確實是需要進行反優化的。
下面是比較常見的情況:
如果代碼正在進行單個步驟的調試,那麼之前被編譯成為機器碼的代碼需要反優化回來,從而能夠調試。
當一個被編譯過的方法,因為種種原因不可用了,這個時候就需要將其反優化。
有可能出現之前優化過的代碼可能不夠完美,需要重新優化的情況,這種情況下同樣也需要進行反優化。
除了JIT編譯成機器碼之外,JIT還有一下常見的代碼優化方式,我們來一一介紹。
舉個例子:
int a = 1;
int b = 2;
int result = add(a, b);
...
public int add(int x, int y) { return x + y; }
int result = a + b; //內聯替換
上面的add方法可以簡單的被替換成為內聯表達式。
通常來說對於條件分支,因為需要有一個if的判斷條件,JVM需要在執行完畢判斷條件,得到返回結果之後,才能夠繼續準備後面的執行代碼,如果有了分支預測,那麼JVM可以提前準備相應的執行代碼,如果分支檢查成功就直接執行,省去了代碼準備的步驟。
比如下面的代碼:
// make an array of random doubles 0..1
double[] bigArray = makeBigArray();
for (int i = 0; i < bigArray.length; i++)
{
double cur = bigArray[i];
if (cur > 0.5) { doThis();} else { doThat();}
}
如果我們在循環語句裏面添加了if語句,為了提升併發的執行效率,可以將if語句從循環中提取出來:
int i, w, x[1000], y[1000];
for (i = 0; i < 1000; i++) {
x[i] += y[i];
if (w)
y[i] = 0;
}
可以改為下面的方式:
int i, w, x[1000], y[1000];
if (w) {
for (i = 0; i < 1000; i++) {
x[i] += y[i];
y[i] = 0;
}
} else {
for (i = 0; i < 1000; i++) {
x[i] += y[i];
}
}
在循環語句中,因為要不斷的進行跳轉,所以限制了執行的速度,我們可以對循環語句中的邏輯進行適當的展開:
int x;
for (x = 0; x < 100; x++)
{
delete(x);
}
轉變為:
int x;
for (x = 0; x < 100; x += 5 )
{
delete(x);
delete(x + 1);
delete(x + 2);
delete(x + 3);
delete(x + 4);
}
雖然循環體變長了,但是跳轉次數變少了,其實是可以提升執行速度的。
什麼叫逃逸分析呢?簡單點講就是分析這個線程中的對象,有沒有可能會被其他對象或者線程所訪問,如果有的話,那麼這個對象應該在Heap中分配,這樣才能讓對其他的對象可見。
如果沒有其他的對象訪問,那麼完全可以在stack中分配這個對象,棧上分配肯定比堆上分配要快,因為不用考慮同步的問題。
我們舉個例子:
public static void main(String[] args) {
example();
}
public static void example() {
Foo foo = new Foo(); //alloc
Bar bar = new Bar(); //alloc
bar.setFoo(foo);
}
}
class Foo {}
class Bar {
private Foo foo;
public void setFoo(Foo foo) {
this.foo = foo;
}
}
上面的例子中,setFoo引用了foo對象,如果bar對象是在heap中分配的話,那麼引用的foo對象就逃逸了,也需要被分配在heap空間中。
但是因為bar和foo對象都只是在example方法中調用的,所以,JVM可以分析出來沒有其他的對象需要引用他們,那麼直接在example的方法棧中分配這兩個對象即可。
逃逸分析還有一個作用就是lock coarsening。
為了在多線程環境中保證資源的有序訪問,JVM引入了鎖的概念,雖然鎖可以保證多線程的有序執行,但是如果實在單線程環境中呢?是不是還需要一直使用鎖呢?
比如下面的例子:
public String getNames() {
Vector<String> v = new Vector<>();
v.add("Me");
v.add("You");
v.add("Her");
return v.toString();
}
Vector是一個同步對象,如果是在單線程環境中,這個同步鎖是沒有意義的,因此在JDK6之後,鎖只在被需要的時候才會使用。
這樣就能提升程序的執行效率。
本文介紹了JIT的原理和一些基本的優化方式。後面我們會繼續探索JIT和JVM的秘密,敬請期待。
本文作者:flydean程序那些事
本文鏈接:http://www.flydean.com/jvm-jit-in-detail/
本文來源:flydean的博客
歡迎關注我的公眾號:程序那些事,更多精彩等着您!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準

電池電動車與氫燃料電池車都有望成為新一代交通主力,但這兩種車款各採用不同的「充電方式」,一種是電力、一種是補充氫氣,各國得針對兩種不同的車系分別打造管線與「加油站」,而近日英國格拉斯哥大學打造新型液流電池,不僅可讓汽車在幾秒內完成燃料補充,還可以釋放電力與氫氣、完美解決兩種電動車系統不相容的狀況。
液流電池(flow battery)由兩個電解質槽組成,充放電時電解質會被幫補到中間的發電室,而發電室也會以薄膜隔開兩種溶液、形成兩個電極,最後產生離子交換來發電,而由於兩種電解質是分開存放,不會有電解質相互滲漏與自身放電等安全性問題,是一種良好的儲能生力軍。
只是液流電池體積龐大,即使該電池具有安全性與穩定性高等優點,仍不適合用於 3C 產品與電動車,目前大多研究團隊都是想把液流電池用在再生能源儲能系統。
而格拉斯哥大學這次想將突破以往液流電池無法用在汽車的印象,並成功透過奈米粒子溶液打造新型液流電池,其中團隊所用的電解質是一種奈米懸浮液(suspension),每個奈米粒子都可以當成一顆小型電池,儲存能量更是一般液流電池的 10 倍,還能以電力或氫氣的形式釋放。
且由於液流電池主要以液態電解質驅動,團隊更指出,新型液流電池可在幾秒內完成移除舊液體、補充新電解質,因此該系統的「充電」時間可跟一般汽油車一樣,大大縮短電動車的充電速度。
格拉斯哥大學 Regius Chair of Chemistry 教授 Leroy(Lee)Cronin 表示,若再生能源想要有效運作,還需要儲存容量、靈活性高的儲能系統來幫忙解決間歇性能源與電力尖峰等問題,而團隊提出的新型化學充電方式,除了可用在儲能系統,還可應用在電動車中。
該研究將有助於未來液流電池的應用,有望縮短液流電池與大規模商業化的距離。團隊也指出,新型液流電池的能量密度相當高,可提升將來電動車的續航里程與儲能系統的儲存容量,目前研究已發表在《》。
(首圖來源:。文/DaisyChuang)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準

新華社報導,中國新能源汽車和再生能源綜合應用商業化推廣專案正式啟動,據中國汽車工程學會常務副理事長兼秘書長張進華表示,整個專案營運期間將直接減排二氧化碳超過 20 萬噸。
張進華指出,新能源汽車和再生能源綜合應用商業化推廣專案的實施,是落實中國汽車產業中長期發展規劃的重要工作之一。據瞭解,為促進中國新能源汽車與再生能源產業綜合應用,充分發揮新能源汽車全生命週期的節能減排效益,減少溫室氣體排放,中國工信部和聯合國工業發展組織共同向全球環境基金申報此項目並獲得批准,中國汽車工程學會將全面承擔專案實施與組織工作,實施週期為 3 年。
據瞭解,該專案具體內容包括組織制定新能源汽車和再生能源綜合應用的政策和標準法規,展開智慧充電系統、再生能源微電網、車網互動、移動充電系統、退役電池梯次利用等技術示範和驗證工作。目前,已確定將中國上海市、江蘇省鹽城市和如皋市作為示範城市,展開新能源汽車和再生能源綜合應用的技術示範和驗證。
(本文內容由 授權使用。首圖來源:)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?

HashMap的原理也是大廠面試中經常會涉及的問題,同時也是工作中常用到的Java容器,本文主要通過對以下問題進行分析講解,來幫助大家理解HashMap的原理。
1.HashMap添加一個鍵值對的過程是怎麼樣的?
2.為什麼說HashMap不是線程安全的?
3.為什麼要一起重寫hashCode()和equal()方法?
這是網上找的一張流程圖,可以結合著步驟來看這個流程圖,了解添加鍵值對的過程。
判斷table是否為空或為null,否則執行resize()方法(resize方法一般是擴容時調用,也可以調用來初始化table)。
根據鍵值key計算hash值。(因為hashCode是一個int類型的變量,是4字節,32位,所以這裡會將hashCode的低16位與高16位進行一個異或運算,來保留高位的特徵,以便於得到的hash值更加均勻分佈)
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
根據(n – 1) & hash計算得到插入的數組下標i,然後進行判斷
那麼說明當前數組下標下,沒有hash衝突的元素,直接新建節點添加。
判斷table[i]的首個元素是否和key一樣,如果相同直接更新value。
判斷table[i] 是否為treeNode,即table[i] 是否是紅黑樹,如果是紅黑樹,則直接在樹中插入鍵值對。
上面的判斷條件都不滿足,說明table[i]存儲的是一個鏈表,那麼遍歷鏈表,判斷是否存在已有元素的key與插入鍵值對的key相等,如果是,那麼更新value,如果沒有,那麼在鏈表末尾插入一個新節點。插入之後判斷鏈表長度是否大於8,大於8的話把鏈錶轉換為紅黑樹。
插入成功后,判斷實際存在的鍵值對數量size是否超多了最大容量threshold(一般是數組長度*負載因子0.75),如果超過,進行擴容。
源代碼如下:
其實通過學習HashMap添加鍵值對的方法,我們可以看到整個方法內都沒有使用到鎖,所以一旦多線併發訪問,就有可能造成數據不一致的問題,
例如:
如果有兩個添加鍵值對的線程都執行到if ((tab = table) == null || (n = tab.length) == 0)這行語句,都對table變量進行數組初始化,就會造成已經初始化好的數組table被覆蓋,然後前面初始化的線程會將鍵值對添加到之前初始化的數組中去,造成鍵值對丟失。
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// tab為空則創建
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
...後面的代碼省略
}
當我們的對象一旦作為HashMap中的key,或者是HashSet中的元素使用時,就必須同時重寫hashCode()和equal()方法
可以看到Obejct類中的源碼如下,可以看到equals()方法的默認實現是判斷兩個對象的內存地址是否相同來決定返回結果。
public native int hashCode();
public boolean equals(Object obj) {
return (this == obj);
}
網上很多博客說hashCode的默認實現是返回內存地址,其實不對,以OpenJDK為例,hashCode的默認計算方法有5種,有返回隨機數的,有返回內存地址,具體採用哪一種計算方法取決於運行時庫和JVM的具體實現。
感興趣的朋友可以看看這篇博客
https://blog.csdn.net/xusiwei1236/article/details/45152201
static final int hash(Object key) {
int h;
//因為hashCode是一個int類型的變量,是4字節,32位,所以這裡會將hashCode的低16位與高16位進行一個異或運算,來保留高位的特徵,以便於得到的hash值更加均勻分佈
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
為了將一組鍵值對均勻得存儲在一個數組中,HashMap對key的hashCode進行計算得到一個hash值,用hash對數組長度取模,得到數組下標,將鍵值對存儲在數組下標對應的鏈表下(假設鏈表長度小於8,沒有達到轉換為紅黑樹的閥值)。
下面是添加鍵值對的putVal()方法,當數組下標對應的是一個鏈表時執行的代碼
//遍歷鏈表
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {//已經遍歷到鏈表末尾,說明鏈表不存在這個key
p.next = newNode(hash, key, value, null);//在末尾添加這個鍵值對
if (binCount >= TREEIFY_THRESHOLD - 1) //超過鏈錶轉化為紅黑樹的閥值(也急速鏈表長度》=8)
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
可以清楚地看到判斷添加的key與鏈表中已存在的key是否相等的方法主要是e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k))),
也就是:
1.先判斷hash值是否相等,不相等直接結束判斷,因為hash值不相等,key肯定不相等。
2.判斷兩個key對象的內存地址是否相等(相等指向內存中同一個對象)。
3.key不為null,調用key的equal()方法判斷是否相等,因為有可能兩個key在內存中存儲的地址不一樣,但是是相等的。
就像是
String a = new String("test");
String b = new String("test");
System.out.println("a==b is "+a==b);//打印為false
System.out.println("a.equals(b) is "+a.equals(b));//打印為true
假設我們有一個KeyObject類,假設我們認為兩個KeyObject的屬性a相等,那麼KeyObject就是相等的相等的,我們將KeyObject作為HashMap的key,以KeyObject是否相等作為去重標準,不能重複添加KeyObject相等,value不等的值到HashMap中去
public static class KeyObject {
Integer a;
public KeyObject(Integer a) {
this.a = a;
}
}
執行以下代碼:
public static void main(String[] args) {
KeyObject key1 = new KeyObject(1);
KeyObject key2 = new KeyObject(1);
System.out.println("key1的hashCode為"+ key1.hashCode());
System.out.println("key2的hashCode為" + key2.hashCode());
System.out.println("key1.equals(key2)的結果為"+(key1.equals(key2)));
HashMap<KeyObject,String> hashMap = new HashMap<KeyObject,String>();
hashMap.put(key1,"value1");
hashMap.put(key2,"value2");
//打印hashMap
for(KeyObject key :hashMap.keySet()){
System.out.println("KeyObject.a="+key.a+" : "+hashMap.get(key));
}
}
如果KeyObject的hashCode()方法和equals()方法都不重寫,那麼即便KeyObject的屬性a都是1,key1和key2的hashCode都是不相同的,key1和key2調用equals()方法也不相等,這樣hashMap中就可以同時存在key1和key2了。
打印結果:
key1的hashCode為728890494
key2的hashCode為1558600329
key1.equals(key2)的結果為false
KeyObject.a=1 : value1
KeyObject.a=1 : value2
執行以下代碼:
public static class KeyObject {
Integer a;
public KeyObject(Integer a) {
this.a = a;
}
@Override
public int hashCode() {
return a;
}
public static void main(String[] args) {
KeyObject key1 = new KeyObject(1);
KeyObject key2 = new KeyObject(1);
System.out.println("key1的hashCode為"+ key1.hashCode());
System.out.println("key2的hashCode為" + key2.hashCode());
System.out.println("key1.equals(key2)的結果為"+(key1.equals(key2)));
HashMap<KeyObject,String> hashMap = new HashMap<KeyObject,String>();
hashMap.put(key1,"value1");
hashMap.put(key2,"value2");
for(KeyObject key :hashMap.keySet()){
System.out.println("TestObject.a="+key.a+" : "+hashMap.get(key));
}
}
}
此時equal()方法的實現是默認實現,也就是當兩個對象的內存地址相等時,equal()方法才返回true,雖然key1和key2的a屬性是相同的,但是他們在內存中是不同的對象,所以key1==key2結果會是false,KeyObject的equals()方法默認實現是判斷兩個對象的內存地址,所以 key1.equals(key2)也會是false,所以這兩個鍵值對可以重複地添加到hashMap中去。
key1的hashCode為1
key2的hashCode為1
key1.equals(key2)的結果為false
TestObject.a=1 : value1
TestObject.a=1 : value2
public static class KeyObject {
Integer a;
public KeyObject(Integer a) {
this.a = a;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
KeyObject keyObject = (KeyObject) o;
return Objects.equals(a, keyObject.a);
}
public static void main(String[] args) {
KeyObject key1 = new KeyObject(1);
KeyObject key2 = new KeyObject(1);
System.out.println("key1的hashCode為"+ key1.hashCode());
System.out.println("key2的hashCode為" + key2.hashCode());
System.out.println("key1.equals(key2)的結果為"+(key1.equals(key2)));
HashMap<KeyObject,String> hashMap = new HashMap<KeyObject,String>();
hashMap.put(key1,"value1");
hashMap.put(key2,"value2");
for(KeyObject key :hashMap.keySet()){
System.out.println("TestObject.a="+key.a+" : "+hashMap.get(key));
}
}
}
假設只equals()方法,hashCode方法會是默認實現,具體的計算方法取決於JVM,(測試時發現是內存地址不同但是相等的對象,它們的hashCode不相同),所以計算得到的數組下標不相同,會存儲到hashMap中不同數組下標下的鏈表中,也會導致HashMap中存在重複元素。
key1的hashCode為1289479439
key2的hashCode為6738746
key1.equals(key2)的結果為true
TestObject.a=1 : value1
TestObject.a=1 : value2
所以當我們的對象一旦作為HashMap中的key,或者是HashSet中的元素使用時,就必須同時重寫hashCode()和equal()方法,因為hashCode會影響key存儲的數組下標及與鏈表元素的初步判斷,equal()是作為判斷key與鏈表中的key是否相等的最後標準。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
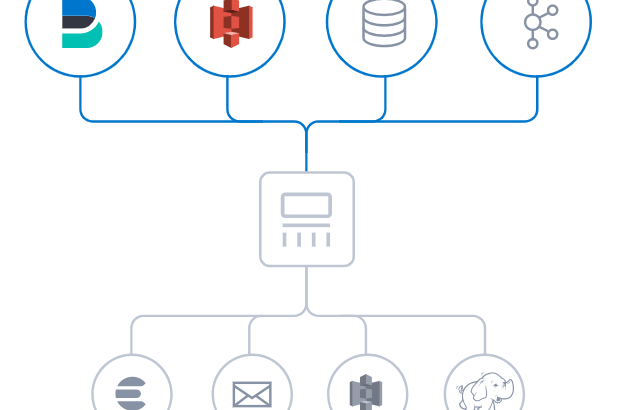
本篇文章採用的採用的是logstash–7.7.0版本,主要從如下幾個方面介紹
1、logstash是什麼,可以用來幹啥
2、logstash的基本原理是什麼
3、怎麼去玩這個elk的組件logstash
官方概念:Logstash是免費且開放的服務器端數據處理管道,能夠從多個來源採集數據,轉換數據,然後將數據發送到您最喜歡的“存儲庫”中。
Logstash能夠動態地採集、轉換和傳輸數據,不受格式或複雜度的影響。利用Grok從非結構化數據中派生出結構,從IP地址解碼出地理坐標,匿名化或排除敏感字段,並簡化整體處理過程。
能夠採集各種樣式、大小和來源的數據往往以各種各樣的形式,比如log日誌,收集redis、kafka等熱門分佈式技術的數據,並且還可以收集實現了java的JMS規範的消息中心的數據,或分散或集中地存在於很多系統中。Logstash支持各種輸入選擇,可以同時從眾多常用來源捕捉事件。能夠以連續的流式傳輸方式,輕鬆地從日誌、指標、Web應用、數據存儲以及各種AWS服務採集數據
數據從源傳輸到存儲庫的過程中,Logstash過濾器能夠解析各個事件,識別已命名的字段以構建結構,並將它們轉換成通用格式,以便進行更強大的分析和實現商業價值。
Logstash能夠動態地轉換和解析數據,不受格式或複雜度的影響:
數據輸入端從各種數據源收集到的數據可能會有很多不是我們想要的,這時我們可以給Logstash定義過濾器,過濾器可以定義多個,它們依次執行,最終把我們想要的數據過濾出來,然後把這些數據解析成目標數據庫,如elasticsearch等能支持的數據格式存儲數據。
選擇好存儲庫,導出數據到存儲庫進行存儲,儘管Elasticsearch是我們的首選輸出方向,能夠為我們的搜索和分析帶來無限可能,但它並非唯一選擇。Logstash提供眾多輸出選擇,可以將數據發送到您要指定的地方,比如redis、kafka等
logstash分為三個步驟:inputs(必須的)→ filters(可選的)→ outputs(必須的),inputs生成時間,filters對其事件進行過濾和處理,outputs輸出到輸出端或者決定其存儲在哪些組件里。inputs和outputs支持編碼和解碼。
Logstash是協調inputs、filters和outputs執行事件處理的管道。
Logstash管道中的每個input階段都在自己的線程中運行。將寫事件輸入到內存(默認)或磁盤上的中心隊列。每個管道工作線程從該隊列中取出一批事件,通過配置的filter處理該批事件,然後通過output輸出到指定的組件存儲。管道處理數據量的大小和管道工作線程的數量是可配置的
默認情況下,Logstash使用管道階段(input→filter和filter→output)之間的內存限制隊列來緩衝事件。如果Logstash不安全地終止,存儲在內存中的所有事件都將丟失。為了幫助防止數據丟失,可以啟用Logstash將飛行中的事件持久化到磁盤。有關詳細信息,請參閱持久隊列https://www.elastic.co/guide/en/logstash/current/persistent-queues.html
如下是目前logstash7.7.0支持的inputs、outputs、filters
inputs:
azure_event_hubs,beats,cloudwatch,couchdb_changes,dead_letter_queue,elasticsearch,exec,file,ganglia,gelf,generator,github,google_cloud_storage,google_pubsub,graphite,heartbeat,http,http_poller,imap,irc,java_generator,java_stdin,jdbc,jms,jmx,kafka,kinesis,log4j,lumberjack,meetup,pipe,puppet_facter,rabbitmq,redis,relp,rss,s3,s3-sns-sqs,salesforce,snmp,snmptrap,sqlite,sqs,stdin,stomp,syslog,tcp,twitter,udp,unix,varnishlog,websocket,wmi,xmpp
outputs:
boundary, circonus, cloudwatch, csv, datadog, datadog_metrics, elastic_app_search, elasticsearch, email, exec, file, ganglia, gelf, google_bigquery, google_cloud_storage, google_pubsub, graphite, graphtastic, http, influxdb, irc, sink, java_stdout, juggernaut, kafka, librato, loggly, lumberjack, metriccatcher, mongodb, nagios, nagios_nsca, opentsdb, pagerduty, pipe, rabbitmq, redis, redmine, riak, riemann, s3, sns, solr_http, sqs, statsd, stdout, stomp, syslog, tcp, timber, udp, webhdfs, websocket, xmpp, zabbix
filters:
aggregate, alter, bytes, cidr, cipher, clone, csv, date, de_dot, dissect, dns, drop, elapsed, elasticsearch, environment, extractnumbers, fingerprint, geoip, grok, http, i18n, java_uuid, jdbc_static, jdbc_streaming, json, json_encode, kv, memcached, metricize, metrics, mutate, prune, range, ruby, sleep, split, syslog_pri, threats_classifier, throttle, tld, translate, truncate, urldecode, useragent, uuid, xml
下載地址1:https://www.elastic.co/cn/downloads/logstash
下載地址2:https://elasticsearch.cn/download/
這裏需要安裝jdk,我使用的是elasticsearch7.7.0自帶的jdk:
解壓即安裝:
tar -zxvf logstash-7.7.0.tar.gz
來個logstash版本的HelloWorld:
./bin/logstash -e 'input { stdin { } } output { stdout {} }'
logstash.yml:包含Logstash配置標誌。您可以在此文件中設置標誌,而不是在命令行中傳遞標誌。在命令行上設置的任何標誌都會覆蓋logstash中的相應設置
pipelines.yml:包含在單個Logstash實例中運行多個管道的框架和指令。
jvm.options:包含JVM配置標誌。使用此文件設置總堆空間的初始值和最大值。您還可以使用此文件為Logsta設置語言環境
log4j2.properties:包含log4j 2庫的默認設置
start.options (Linux):用於配置啟動服務腳本
logstash.yml文件詳解:
node.name #默認主機名,該節點的描述名字 path.data #LOGSTASH_HOME/data ,Logstash及其插件用於任何持久需求的目錄 pipeline.id #默認main,pipeline的id pipeline.java_execution #默認true,使用java執行引擎 pipeline.workers #默認為主機cpu的個數,表示并行執行管道的過濾和輸出階段的worker的數量 pipeline.batch.size #默認125 表示單個工作線程在嘗試執行過濾器和輸出之前從輸入中收集的最大事件數 pipeline.batch.delay #默認50 在創建管道事件時,在將一個小批分派給管道工作者之前,每個事件需要等待多長時間(毫秒) pipeline.unsafe_shutdown #默認false,當設置為true時,即使內存中仍有運行的事件,強制Logstash在關閉期間將會退出。默認情況下,Logstash將拒絕退出,直到所有接收到的事件都被推入輸出。啟用此選項可能導致關機期間數據丟失 pipeline.ordered #默認auto,設置管道事件順序。true將強制對管道進行排序,如果有多個worker,則阻止logstash啟動。如果為false,將禁用維持秩序所需的處理。訂單順序不會得到保證,但可以節省維護訂單的處理成本 path.config #默認LOGSTASH_HOME/config 管道的Logstash配置的路徑 config.test_and_exit #默認false,設置為true時,檢查配置是否有效,然後退出。請注意,使用此設置不會檢查grok模式的正確性 config.reload.automatic #默認false,當設置為true時,定期檢查配置是否已更改,並在更改時重新加載配置。這也可以通過SIGHUP信號手動觸發 config.reload.interval #默認3s ,檢查配置文件頻率 config.debug #默認false 當設置為true時,將完全編譯的配置显示為調試日誌消息 queue.type #默認memory ,用於事件緩衝的內部排隊模型。為基於內存中的遺留隊列指定內存,或為基於磁盤的脫機隊列(持久隊列)指定持久內存 path.queue #默認path.data/queue ,在啟用持久隊列時存儲數據文件的目錄路徑 queue.page_capacity #默認64mb ,啟用持久隊列時(隊列),使用的頁面數據文件的大小。隊列數據由分隔為頁面的僅追加數據文件組成 queue.max_events #默認0,表示無限。啟用持久隊列時,隊列中未讀事件的最大數量 queue.max_bytes #默認1024mb,隊列的總容量,以字節為單位。確保磁盤驅動器的容量大於這裏指定的值 queue.checkpoint.acks #默認1024,當啟用持久隊列(隊列)時,在強制執行檢查點之前被隔離的事件的最大數量 queue.checkpoint.writes #默認1024,當啟用持久隊列(隊列)時,強制執行檢查點之前的最大寫入事件數 queue.checkpoint.retry #默認false,啟用后,對於任何失敗的檢查點寫,Logstash將對每個嘗試的檢查點寫重試一次。任何後續錯誤都不會重試。並且不推薦使用,除非是在那些特定的環境中 queue.drain #默認false,啟用后,Logstash將等待,直到持久隊列耗盡,然後關閉 path.dead_letter_queue#默認path.data/dead_letter_queue,存儲dead-letter隊列的目錄 http.host #默認"127.0.0.1" 表示endpoint REST端點的綁定地址。 http.port #默認9600 表示endpoint REST端點的綁定端口。 log.level #默認info,日誌級別fatal,error,warn,info,debug,trace, log.format #默認plain 日誌格式 path.logs #默認LOGSTASH_HOME/logs 日誌目錄
keystore可以保護一些敏感的信息,使用變量的方式替代,比如使用ES_PWD代替elasticsearch的密碼,可以通過${ES_PWD}來獲取elasticsearch的密碼,這樣就是的密碼不再是明文密碼。
./bin/logstash-keystore create #創建一個keyword ./bin/logstash-keystore add ES_PWD #創建一個elastic的passwd,然後通過${ES_PWD}使用該密碼 ./bin/logstash-keystore list #查看已經設置好的鍵值對 ./bin/logstash-keystore remove ES_PWD #刪除在keyword中的key
例如:
注意:參數和logstash.yml配置文件對應(這裏不詳解,請查看3.2節)
-n, --node.name NAME -f, --path.config CONFIG_PATH -e, --config.string CONFIG_STRING --field-reference-parser MODE --modules MODULES -M, --modules.variable MODULES_VARIABLE --setup --cloud.id CLOUD_ID --cloud.auth CLOUD_AUTH --pipeline.id ID -w, --pipeline.workers COUNT --pipeline.ordered ORDERED --java-execution --plugin-classloaders -b, --pipeline.batch.size SIZE -u, --pipeline.batch.delay DELAY_IN_MS --pipeline.unsafe_shutdown --path.data PATH -p, --path.plugins PATH -l, --path.logs PATH --log.level LEVEL --config.debug -i, --interactive SHELL -V, --version -t, --config.test_and_exit -r, --config.reload.automatic --config.reload.interval --http.host HTTP_HOST --http.port HTTP_PORT --log.format FORMAT --path.settings SETTINGS_DIR
輸入,解析過濾,輸出,其中filter不是必須的,其他兩個是必須的。
input {
...
}
filter {
...
}
output {
...
}
array:數組可以是單個或者多個字符串值。
users => [ {id => 1, name => bob}, {id => 2, name => jane} ]
Lists:集合
path => [ "/var/log/messages", "/var/log/*.log" ] uris => [ "http://elastic.co", "http://example.net" ]
Boolean:true 或者false
ssl_enable => true
Bytes:字節類型
my_bytes => "1113" # 1113 bytes my_bytes => "10MiB" # 10485760 bytes my_bytes => "100kib" # 102400 bytes my_bytes => "180 mb" # 180000000 bytes
Codec:編碼類型
codec => "json"
Hash:哈希(散列)
match => { "field1" => "value1" "field2" => "value2" ... } # or as a single line. No commas between entries: match => { "field1" => "value1" "field2" => "value2" }
Number:数字類型
port => 33
Password:密碼類型
my_password => "password"
URI:uri類型
my_uri => "http://foo:bar@example.net"
Path: 路徑類型
my_path => "/tmp/logstash"
String:字符串類型,字符串必須是單個字符序列。注意,字符串值被括在雙引號或單引號中
配置賬號,一個種是role,一種是user,配置方式有兩種,一種是通過elasticsearch的API配置,一種是通過kibana配置:
#添加一個logstash_writer的角色 POST _xpack/security/role/logstash_writer { "cluster": ["manage_index_templates", "monitor", "manage_ilm"], "indices": [ { "names": [ "logstash-*" ], #索引的模式匹配 "privileges": ["write","create","delete","create_index","manage","manage_ilm"] #權限內容 } ] } #添加一個有logstash_writer角色權限的用戶:logstash_internal POST _xpack/security/user/logstash_internal { "password" : "x-pack-test-password", "roles" : [ "logstash_writer"], #分配角色 "full_name" : "Internal Logstash User" } #添加一個logstash_reader角色,只有read權限 POST _xpack/security/role/logstash_reader { "indices": [ { "names": [ "logstash-*" ], "privileges": ["read","view_index_metadata"] } ] } #添加一個有logstash_reader角色權限的用戶:logstash_user POST _xpack/security/user/logstash_user { "password" : "x-pack-test-password", "roles" : [ "logstash_reader", "logstash_admin"], "full_name" : "Kibana User for Logstash" }
Management > Roles
Management > Users
權限選擇見elasticsearch官網:
https://www.elastic.co/guide/en/elasticsearch/reference/current/authorization.html
https://www.elastic.co/guide/en/elasticsearch/reference/current/security-privileges.html
如果需要在同一個進程中運行多個管道,Logstash提供了一種通過名為pipelines.yml的配置文件來實現此目的的方法。
例如:
- pipeline.id: my-pipeline_1 path.config: "/etc/path/to/p1.config" pipeline.workers: 3 - pipeline.id: my-other-pipeline path.config: "/etc/different/path/p2.cfg" queue.type: persisted
該文件在YAML文件格式中,並包含一個字典列表,其中每個字典描述一個管道,每個鍵/值對指定該管道的設置。該示例展示了通過id和配置路徑描述的兩個不同管道。對於第一個管道,為pipeline.workers的值設置為3,而在另一个中,持久隊列特性被啟用。未在pipelines.yml顯式設置的值。yml文件將使用到logstash中指定的默認值。
當啟動Logstash不帶參數時,它將讀取管道pipelines.yml。yml文件並實例化文件中指定的所有管道。另一方面,當使用-e或-f時,Logstash會忽略管道。
注意:
各管道之間的通信原理:https://www.elastic.co/guide/en/logstash/current/pipeline-to-pipeline.html,有興趣的可以了解下。
在我們運行logstash的過程,不想停掉logstash進程,但是又想修改配置,就可以使用到配置的重新加載了,有兩種方式。
bin/logstash -f apache.config --config.reload.automatic
Logstash每3秒檢查一次配置更改。要更改此間隔,請使用–config.reload.interval <interval>選項,其中interval指定Logstash檢查配置文件更改的頻率(以秒為單位),請注意,必須使用單位限定符(s)
kill -SIGHUP pid #pid為logstash的pid
自動配置重新加載配置注意點:
注:grok插件是一個十分耗費資源的插件
官網:https://www.elastic.co/guide/en/logstash/current/plugins-filters-grok.html
Grok是將非結構化日誌數據解析為結構化和可查詢內容的好方法,非常適合syslog日誌,apache和其他Web服務器日誌,mysql日誌等等
首先官方提供了120中的匹配模式(但是我一直都沒打開這個網址):https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
還有一個用來驗證自定義的解析是否正確的一個網址:http://grokdebug.herokuapp.com/
既然我沒能打開官方提供的120個的模式匹配,從一片博客中找到了一部分的匹配模式(如下):https://blog.csdn.net/cui929434/article/details/94390617
USERNAME [a-zA-Z0-9._-]+ USER %{USERNAME} INT (?:[+-]?(?:[0-9]+)) BASE10NUM (?<![0-9.+-])(?>[+-]?(?:(?:[0-9]+(?:\.[0-9]+)?)|(?:\.[0-9]+))) NUMBER (?:%{BASE10NUM}) BASE16NUM (?<![0-9A-Fa-f])(?:[+-]?(?:0x)?(?:[0-9A-Fa-f]+)) BASE16FLOAT \b(?<![0-9A-Fa-f.])(?:[+-]?(?:0x)?(?:(?:[0-9A-Fa-f]+(?:\.[0-9A-Fa-f]*)?)|(?:\.[0-9A-Fa-f]+)))\b POSINT \b(?:[1-9][0-9]*)\b NONNEGINT \b(?:[0-9]+)\b WORD \b\w+\b NOTSPACE \S+ SPACE \s* DATA .*? GREEDYDATA .* QUOTEDSTRING (?>(?<!\\)(?>"(?>\\.|[^\\"]+)+"|""|(?>'(?>\\.|[^\\']+)+')|''|(?>`(?>\\.|[^\\`]+)+`)|``)) UUID [A-Fa-f0-9]{8}-(?:[A-Fa-f0-9]{4}-){3}[A-Fa-f0-9]{12} # Networking MAC (?:%{CISCOMAC}|%{WINDOWSMAC}|%{COMMONMAC}) CISCOMAC (?:(?:[A-Fa-f0-9]{4}\.){2}[A-Fa-f0-9]{4}) WINDOWSMAC (?:(?:[A-Fa-f0-9]{2}-){5}[A-Fa-f0-9]{2}) COMMONMAC (?:(?:[A-Fa-f0-9]{2}:){5}[A-Fa-f0-9]{2}) IPV6 ((([0-9A-Fa-f]{1,4}:){7}([0-9A-Fa-f]{1,4}|:))|(([0-9A-Fa-f]{1,4}:){6}(:[0-9A-Fa-f]{1,4}|((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){5}(((:[0-9A-Fa-f]{1,4}){1,2})|:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3})|:))|(([0-9A-Fa-f]{1,4}:){4}(((:[0-9A-Fa-f]{1,4}){1,3})|((:[0-9A-Fa-f]{1,4})?:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){3}(((:[0-9A-Fa-f]{1,4}){1,4})|((:[0-9A-Fa-f]{1,4}){0,2}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){2}(((:[0-9A-Fa-f]{1,4}){1,5})|((:[0-9A-Fa-f]{1,4}){0,3}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(([0-9A-Fa-f]{1,4}:){1}(((:[0-9A-Fa-f]{1,4}){1,6})|((:[0-9A-Fa-f]{1,4}){0,4}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:))|(:(((:[0-9A-Fa-f]{1,4}){1,7})|((:[0-9A-Fa-f]{1,4}){0,5}:((25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)(\.(25[0-5]|2[0-4]\d|1\d\d|[1-9]?\d)){3}))|:)))(%.+)? IPV4 (?<![0-9])(?:(?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})[.](?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})[.](?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2})[.](?:25[0-5]|2[0-4][0-9]|[0-1]?[0-9]{1,2}))(?![0-9]) IP (?:%{IPV6}|%{IPV4}) HOSTNAME \b(?:[0-9A-Za-z][0-9A-Za-z-]{0,62})(?:\.(?:[0-9A-Za-z][0-9A-Za-z-]{0,62}))*(\.?|\b) HOST %{HOSTNAME} IPORHOST (?:%{HOSTNAME}|%{IP}) HOSTPORT %{IPORHOST}:%{POSINT} # paths PATH (?:%{UNIXPATH}|%{WINPATH}) UNIXPATH (?>/(?>[\w_%!$@:.,-]+|\\.)*)+ TTY (?:/dev/(pts|tty([pq])?)(\w+)?/?(?:[0-9]+)) WINPATH (?>[A-Za-z]+:|\\)(?:\\[^\\?*]*)+ URIPROTO [A-Za-z]+(\+[A-Za-z+]+)? URIHOST %{IPORHOST}(?::%{POSINT:port})? # uripath comes loosely from RFC1738, but mostly from what Firefox # doesn't turn into %XX URIPATH (?:/[A-Za-z0-9$.+!*'(){},~:;=@#%_\-]*)+ #URIPARAM \?(?:[A-Za-z0-9]+(?:=(?:[^&]*))?(?:&(?:[A-Za-z0-9]+(?:=(?:[^&]*))?)?)*)? URIPARAM \?[A-Za-z0-9$.+!*'|(){},~@#%&/=:;_?\-\[\]]* URIPATHPARAM %{URIPATH}(?:%{URIPARAM})? URI %{URIPROTO}://(?:%{USER}(?::[^@]*)?@)?(?:%{URIHOST})?(?:%{URIPATHPARAM})? # Months: January, Feb, 3, 03, 12, December MONTH \b(?:Jan(?:uary)?|Feb(?:ruary)?|Mar(?:ch)?|Apr(?:il)?|May|Jun(?:e)?|Jul(?:y)?|Aug(?:ust)?|Sep(?:tember)?|Oct(?:ober)?|Nov(?:ember)?|Dec(?:ember)?)\b MONTHNUM (?:0?[1-9]|1[0-2]) MONTHNUM2 (?:0[1-9]|1[0-2]) MONTHDAY (?:(?:0[1-9])|(?:[12][0-9])|(?:3[01])|[1-9]) # Days: Monday, Tue, Thu, etc... DAY (?:Mon(?:day)?|Tue(?:sday)?|Wed(?:nesday)?|Thu(?:rsday)?|Fri(?:day)?|Sat(?:urday)?|Sun(?:day)?) # Years? YEAR (?>\d\d){1,2} HOUR (?:2[0123]|[01]?[0-9]) MINUTE (?:[0-5][0-9]) # '60' is a leap second in most time standards and thus is valid. SECOND (?:(?:[0-5]?[0-9]|60)(?:[:.,][0-9]+)?) TIME (?!<[0-9])%{HOUR}:%{MINUTE}(?::%{SECOND})(?![0-9]) # datestamp is YYYY/MM/DD-HH:MM:SS.UUUU (or something like it) DATE_US %{MONTHNUM}[/-]%{MONTHDAY}[/-]%{YEAR} DATE_EU %{MONTHDAY}[./-]%{MONTHNUM}[./-]%{YEAR} ISO8601_TIMEZONE (?:Z|[+-]%{HOUR}(?::?%{MINUTE})) ISO8601_SECOND (?:%{SECOND}|60) TIMESTAMP_ISO8601 %{YEAR}-%{MONTHNUM}-%{MONTHDAY}[T ]%{HOUR}:?%{MINUTE}(?::?%{SECOND})?%{ISO8601_TIMEZONE}? DATE %{DATE_US}|%{DATE_EU} DATESTAMP %{DATE}[- ]%{TIME} TZ (?:[PMCE][SD]T|UTC) DATESTAMP_RFC822 %{DAY} %{MONTH} %{MONTHDAY} %{YEAR} %{TIME} %{TZ} DATESTAMP_RFC2822 %{DAY}, %{MONTHDAY} %{MONTH} %{YEAR} %{TIME} %{ISO8601_TIMEZONE} DATESTAMP_OTHER %{DAY} %{MONTH} %{MONTHDAY} %{TIME} %{TZ} %{YEAR} DATESTAMP_EVENTLOG %{YEAR}%{MONTHNUM2}%{MONTHDAY}%{HOUR}%{MINUTE}%{SECOND} # Syslog Dates: Month Day HH:MM:SS SYSLOGTIMESTAMP %{MONTH} +%{MONTHDAY} %{TIME} PROG (?:[\w._/%-]+) SYSLOGPROG %{PROG:program}(?:\[%{POSINT:pid}\])? SYSLOGHOST %{IPORHOST} SYSLOGFACILITY <%{NONNEGINT:facility}.%{NONNEGINT:priority}> HTTPDATE %{MONTHDAY}/%{MONTH}/%{YEAR}:%{TIME} %{INT} # Shortcuts QS %{QUOTEDSTRING} # Log formats SYSLOGBASE %{SYSLOGTIMESTAMP:timestamp} (?:%{SYSLOGFACILITY} )?%{SYSLOGHOST:logsource} %{SYSLOGPROG}: COMMONAPACHELOG %{IPORHOST:clientip} %{USER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response} (?:%{NUMBER:bytes}|-) COMBINEDAPACHELOG %{COMMONAPACHELOG} %{QS:referrer} %{QS:agent} # Log Levels LOGLEVEL ([Aa]lert|ALERT|[Tt]race|TRACE|[Dd]ebug|DEBUG|[Nn]otice|NOTICE|[Ii]nfo|INFO|[Ww]arn?(?:ing)?|WARN?(?:ING)?|[Ee]rr?(?:or)?|ERR?(?:OR)?|[Cc]rit?(?:ical)?|CRIT?(?:ICAL)?|[Ff]atal|FATAL|[Ss]evere|SEVERE|EMERG(?:ENCY)?|[Ee]merg(?:ency)?)
grok內置的一些匹配模式
基礎語法,一種是自帶的模式,一種是自定義的模式:
自帶的模式語法: %{SYNTAX:SEMANTIC}
SYNTAX是將匹配文本模式的名稱,grok自帶的那些匹配模式名
SEMANTIC是你給一段文字的標識相匹配該匹配模式匹配到的內容,相當於一個字段名
例如:
%{NUMBER:duration} %{IP:client}
比如要解析如下的日誌:
55.3.244.1 GET /index.html 15824 0.043
就可以使用該匹配模式去匹配:
%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}
得出的結果如下:
client: 55.3.244.1 method: GET request: /index.html bytes: 15824 duration: 0.043
自定義的模式語法:(?<field_name>the pattern here)
例如:
(?<queue_id>[0-9A-F]{10,11}) #表示10-11個字符的16進制
我們可以創建一個目錄pattters,把我自定義的模式添加進去,在使用的時候就可以使用grok自帶的匹配模式的語法,例如:
我們在./patterns/postfix文件中添加如下內容 POSTFIX_QUEUEID [0-9A-F]{10,11}
如上我們就定義了一個匹配模式了,可以使用如下的方式使用。假如我們有如下的日誌格式:
Jan 1 06:25:43 mailserver14 postfix/cleanup[21403]: BEF25A72965: message-id=<20130101142543.5828399CCAF@mailserver14.example.com>
然後我們對其就行解析:
filter { grok { patterns_dir => ["./patterns"] #指定自定義的匹配模式路徑 match => { "message" => "%{SYSLOGBASE} %{POSTFIX_QUEUEID:queue_id}: %{GREEDYDATA:syslog_message}" } } }
解析出的結果如下:
timestamp: Jan 1 06:25:43 logsource: mailserver14 program: postfix/cleanup pid: 21403 queue_id: BEF25A72965 syslog_message: message-id=<20130101142543.5828399CCAF@mailserver14.example.com>
grok的配置選項:
break_on_match 值類型是布爾值 默認是true 描述:match可以一次設定多組,預設會依照順序設定處理,如果日誌滿足設定條件,則會終止向下處理。但有的時候我們會希望讓Logstash跑完所有的設定,這時可以將break_on_match設為false。 keep_empty_captures 值類型是布爾值 默認值是 false 描述:如果為true,捕獲失敗的字段將設置為空值 match 值類型是數組 默認值是 {} 描述:字段值的模式匹配 例如: filter { grok { match => { "message" => "Duration: %{NUMBER:duration}" } } } #如果你需要針對單個字段匹配多個模式,則該值可以是一組,例如: filter { grok { match => { "message" => [ "Duration: %{NUMBER:duration}", "Speed: %{NUMBER:speed}" ] } } } named_captures_only 值類型是布爾值 默認值是 true 描述:如果設置為true,則僅存儲來自grok的命名捕獲 overwrite 值類型是 array 默認是[] 描述:覆蓋已經存在的字段內容 例如: filter { grok { match => { "message" => "%{SYSLOGBASE} %{DATA:message}" } overwrite => [ "message" ] } } 如果日誌是May 29 16:37:11 sadness logger: hello world經過match屬性match => { “message” => “%{SYSLOGBASE} %{DATA:message}” }處理后,message的值變成了hello world。這時如果使用了overwrite => [ “message” ]屬性,那麼原來的message的值將被覆蓋成新值。 pattern_definitions 值類型是 數組 默認值是 {} 描述:模式名稱和模式正則表達式,也是用於定義當前過濾器要使用的自定義模式。匹配現有名稱的模式將覆蓋預先存在的定義。可以將此視為僅適用於grok定義的內聯模式,patterns_dir是將模式寫在外部。 例如: filter { grok { patterns_dir => "/usr/local/elk/logstash/patterns" pattern_definitions => {"MYSELFTIMESTAMP" => "20%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{HOUR}:?%{MINUTE}(?::?%{SECOND})"} match => {"message" => ["%{MYSELFTIMESTAMP:timestamp} %{JAVACLASS:message}","%{MYSELF:content}"]} } } patterns_dir 值類型是數組 默認值是 [] 描述:一些複雜的正則表達式,不適合直接寫到filter中,可以指定一個文件夾,用來專門保存正則表達式的文件,需要注意的是該文件夾中的所有文件中的正則表達式都會被依次加載,包括備份文件。 patterns_dir => ["/opt/logstash/patterns", "/opt/logstash/extra_patterns"] 正則文件以文本格式描述: patterns_file_glob 屬性值的類型:string 默認值:“*” 描述:針對patterns_dir屬性中指定的文件夾里哪些正則文件,可以在這個filter中生效,需要本屬性來指定。默認值“*”是指所有正則文件都生效。 tag_on_failure 值類型是數組 默認值是 [“_grokparsefailure”] 描述:沒有成功匹配時,將值附加到字段到tags tag_on_timeout 值類型是字符串 默認值是 “_groktimeout” 描述:如果Grok正則表達式超時,則應用標記。 timeout_millis 值類型是数字 默認值是 30000 描述: 嘗試在這段時間后終止正則表達式。如果應用了多個模式,則這適用於每個模式。這將永遠不會提前超時,但超時可能需要一些時間。實際的超時時間是基於250ms量化的近似值。設置為0以禁用超時。
各組件的公共配置選項:
break_on_match 值類型是布爾值 默認是true 描述:match可以一次設定多組,預設會依照順序設定處理,如果日誌滿足設定條件,則會終止向下處理。但有的時候我們會希望讓Logstash跑完所有的設定,這時可以將break_on_match設為false。 keep_empty_captures 值類型是布爾值 默認值是 false 描述:如果為true,捕獲失敗的字段將設置為空值 match 值類型是數組 默認值是 {} 描述:字段值的模式匹配 例如: filter { grok { match => { "message" => "Duration: %{NUMBER:duration}" } } } #如果你需要針對單個字段匹配多個模式,則該值可以是一組,例如: filter { grok { match => { "message" => [ "Duration: %{NUMBER:duration}", "Speed: %{NUMBER:speed}" ] } } } named_captures_only 值類型是布爾值 默認值是 true 描述:如果設置為true,則僅存儲來自grok的命名捕獲 overwrite 值類型是 array 默認是[] 描述:覆蓋已經存在的字段內容 例如: filter { grok { match => { "message" => "%{SYSLOGBASE} %{DATA:message}" } overwrite => [ "message" ] } } 如果日誌是May 29 16:37:11 sadness logger: hello world經過match屬性match => { “message” => “%{SYSLOGBASE} %{DATA:message}” }處理后,message的值變成了hello world。這時如果使用了overwrite => [ “message” ]屬性,那麼原來的message的值將被覆蓋成新值。 pattern_definitions 值類型是 數組 默認值是 {} 描述:模式名稱和模式正則表達式,也是用於定義當前過濾器要使用的自定義模式。匹配現有名稱的模式將覆蓋預先存在的定義。可以將此視為僅適用於grok定義的內聯模式,patterns_dir是將模式寫在外部。 例如: filter { grok { patterns_dir => "/usr/local/elk/logstash/patterns" pattern_definitions => {"MYSELFTIMESTAMP" => "20%{YEAR}-%{MONTHNUM}-%{MONTHDAY} %{HOUR}:?%{MINUTE}(?::?%{SECOND})"} match => {"message" => ["%{MYSELFTIMESTAMP:timestamp} %{JAVACLASS:message}","%{MYSELF:content}"]} } } patterns_dir 值類型是數組 默認值是 [] 描述:一些複雜的正則表達式,不適合直接寫到filter中,可以指定一個文件夾,用來專門保存正則表達式的文件,需要注意的是該文件夾中的所有文件中的正則表達式都會被依次加載,包括備份文件。 patterns_dir => ["/opt/logstash/patterns", "/opt/logstash/extra_patterns"] 正則文件以文本格式描述: patterns_file_glob 屬性值的類型:string 默認值:“*” 描述:針對patterns_dir屬性中指定的文件夾里哪些正則文件,可以在這個filter中生效,需要本屬性來指定。默認值“*”是指所有正則文件都生效。 tag_on_failure 值類型是數組 默認值是 [“_grokparsefailure”] 描述:沒有成功匹配時,將值附加到字段到tags tag_on_timeout 值類型是字符串 默認值是 “_groktimeout” 描述:如果Grok正則表達式超時,則應用標記。 timeout_millis 值類型是数字 默認值是 30000 描述: 嘗試在這段時間后終止正則表達式。如果應用了多個模式,則這適用於每個模式。這將永遠不會提前超時,但超時可能需要一些時間。實際的超時時間是基於250ms量化的近似值。設置為0以禁用超時。 常用選項 所有過濾器插件都支持以下配置選項: dd_field 值類型是散列 默認值是 {} 描述:如果匹配成功,向此事件添加任意字段。字段名可以是動態的,並使用%{Field}包含事件的一部分 filter { grok { add_field => { "foo_%{somefield}" => "Hello world, from %{host}" } } } # 你也可以一次添加多個字段 filter { grok { add_field => { "foo_%{somefield}" => "Hello world, from %{host}" "new_field" => "new_static_value" } } } add_tag 值類型是數組 默認值是 [] 描述:如果此過濾器成功,請向該事件添加任意標籤。標籤可以是動態的,並使用%{field} 語法包含事件的一部分。 例如: filter { grok { add_tag => [ "foo_%{somefield}" ] } } # 你也可以一次添加多個標籤 filter { grok { add_tag => [ "foo_%{somefield}", "taggedy_tag"] } } enable_metric 值類型是布爾值 默認值是 true 描述:禁用或啟用度量標準 id 值類型是字符串 此值沒有默認值。 描述:向插件實例添加唯一ID,此ID用於跟蹤插件特定配置的信息。 例如: filter { grok { id => "ABC" } } periodic_flush 值類型是布爾值 默認值是 false 描述:如果設置為ture,會定時的調用filter的更新函數(flush method) remove_field 值的類型:array 默認值:[] 描述:刪除當前文檔中的指定filted filter { grok { remove_field => [ "foo_%{somefield}" ] } } # 你也可以一次移除多個字段: filter { grok { remove_field => [ "foo_%{somefield}", "my_extraneous_field" ] } } remove_tag 值類型是數組 默認值是 [] 描述:如果此過濾器成功,請從該事件中移除任意標籤。標籤可以是動態的,並使用%{field} 語法包括事件的一部分。 例如: filter { grok { remove_tag => [ "foo_%{somefield}" ] } } # 你也可以一次刪除多個標籤 filter { grok { remove_tag => [ "foo_%{somefield}", "sad_unwanted_tag"] } }
官網網址:https://www.elastic.co/guide/en/logstash/current/plugins-filters-mutate.html
mutate允許對字段執行常規改變。可以重命名、刪除、替換和修改事件中的字段。
二話不說,來個例子先:
filter { mutate { split => ["hostname", "."] #切分 add_field => { "shortHostname" => "%{hostname[0]}" } #獲取切分后的第一個字段作為添加字段 } mutate { rename => ["shortHostname", "hostname" ] #重命名 } }
mutate的配置選項:
常用的一些操作: convert:轉換數據類型,數據類型hash 可以裝換的數據類型有:integer,string,integer_eu(和integer相同,显示格式為1.000),float,float_eu,boolean 實例: filter { mutate { convert => { "fieldname" => "integer" "booleanfield" => "boolean" } } } copy:類型hash,將現有字段複製到另一個字段。現有的目標域將被覆蓋 實例: filter { mutate { copy => { "source_field" => "dest_field" } } } gsub:類型array,根據字段值匹配正則表達式,並用替換字符串替換所有匹配項。只支持字符串或字符串數組的字段。對於其他類型的字段,將不採取任何操作。 實例: filter { mutate { gsub => [ # replace all forward slashes with underscore "fieldname", "/", "_", # replace backslashes, question marks, hashes, and minuses # with a dot "." "fieldname2", "[\\?#-]", "." ] } } join:類型hash,用分隔符連接數組。對非數組字段不執行任何操作 實例: filter { mutate { join => { "fieldname" => "," } } } lowercase:類型array,轉為小寫 實例: filter { mutate { lowercase => [ "fieldname" ] } } merge:類型hash,合併數組或散列的兩個字段。字符串字段將自動轉換為數組 實例: filter { mutate { merge => { "dest_field" => "added_field" } } } coerce:類型hash,設置存在但為空的字段的默認值 實例: filter { mutate { # Sets the default value of the 'field1' field to 'default_value' coerce => { "field1" => "default_value" } } } rename:類型hash,重命名 實例: filter { mutate { # Renames the 'HOSTORIP' field to 'client_ip' rename => { "HOSTORIP" => "client_ip" } } } replace:類型hash,用新值替換字段的值 實例: filter { mutate { replace => { "message" => "%{source_host}: My new message" } } } split:類型hash,使用分隔符將字段分割為數組。只對字符串字段有效 實例: filter { mutate { split => { "fieldname" => "," } } } strip:類型array,字段中刪除空白。注意:這隻對前導和后導空格有效。 實例: filter { mutate { strip => ["field1", "field2"] } } update:類型hash,使用新值更新現有字段。如果該字段不存在,則不採取任何操作。 實例: filter { mutate { update => { "sample" => "My new message" } } } uppercase:類型array,轉為大寫 實例: filter { mutate { uppercase => [ "fieldname" ] } } capitalize:類型array,將字符串轉換為等效的大寫字母。 實例: filter { mutate { capitalize => [ "fieldname" ] } } tag_on_failure:類型string,如果在應用此變異篩選器期間發生故障,則終止其餘操作,默認值:_mutate_error
公共配置見:grok公共配置
date filter用於從字段解析日期,然後使用該日期或時間戳作為事件的logstash時間戳
date常用的配置選項:
match:類型array,字段名在前,格式模式在後的數組[ field,formats... ],表示該字段能夠匹配到的時間模式,時間模式可以有多種 實例: filter { date { match => [ "logdate", "MMM dd yyyy HH:mm:ss" ] } } tag_on_failure:類型array,默認值["_dateparsefailure"],當沒有成功匹配時,將值追加到tags字段 target:類型String,默認值"@timestamp",將匹配的時間戳存儲到給定的目標字段中。如果沒有提供,默認更新事件到@timestamp字段。 timezone:類型String,表示時區,可以在該網址查看:http://joda-time.sourceforge.net/timezones.html
公共配置見:grok公共配置
這裏只對如上三種filter說明,具體其他的filter請見官網:https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
這個例子屬官網的一個例子:https://www.elastic.co/guide/en/logstash/current/advanced-pipeline.html
但是我這裏不弄這麼負責,我們不使用filebeat,直接使用logstash,apache日誌的數據集下載:https://download.elastic.co/demos/logstash/gettingstarted/logstash-tutorial.log.gz
我這裏不打算安裝apach,所以直接使用官方提供的數據集。
下載數據集,然後解壓文件,就可以得到我們的一個日誌文件:logstash-tutorial.log
首先我們看一下apache日誌的格式:
[elk@lgh ~]$ tail -3 logstash-tutorial.log 86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] "GET /projects/xdotool/ HTTP/1.1" 200 12292 "http://www.haskell.org/haskellwiki/Xmonad/Frequently_asked_questions" "Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0" 86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] "GET /reset.css HTTP/1.1" 200 1015 "http://www.semicomplete.com/projects/xdotool/" "Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0" 86.1.76.62 - - [04/Jan/2015:05:30:37 +0000] "GET /style2.css HTTP/1.1" 200 4877 "http://www.semicomplete.com/projects/xdotool/" "Mozilla/5.0 (X11; Linux x86_64; rv:24.0) Gecko/20140205 Firefox/24.0 Iceweasel/24.3.0"
然後開始配置:
cd logstash-7.7.0/ && mkdir conf.d cd conf.d/ vim apache.conf #############apache.conf的內容如下################### input { file { path => "/home/elk/logstash-tutorial.log" type => "log" start_position => "beginning" } } filter { grok { match => { "message" => "%{COMBINEDAPACHELOG}"} } } output { stdout { codec => rubydebug } }
然後啟動命令(可以選擇用nohup後台啟動):
cd logstash-7.7.0/ && ./bin/logstash -f conf.d/apache.conf
執行結果如下(部分結果):
{ "verb" => "GET", "bytes" => "8948", "type" => "log", "host" => "gxt_126_233", "httpversion" => "1.0", "message" => "67.214.178.190 - - [04/Jan/2015:05:20:59 +0000] \"GET /blog/geekery/installing-windows-8-consumer-preview.html HTTP/1.0\" 200 8948 \"http://www.semicomplete.com/\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.7; rv:21.0) Gecko/20100101 Firefox/21.0\"", "timestamp" => "04/Jan/2015:05:20:59 +0000", "referrer" => "\"http://www.semicomplete.com/\"", "@timestamp" => 2020-06-17T01:23:47.817Z, "path" => "/data/hd05/elk/logstash-tutorial.log", "ident" => "-", "response" => "200", "@version" => "1", "request" => "/blog/geekery/installing-windows-8-consumer-preview.html", "clientip" => "67.214.178.190", "agent" => "\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.7; rv:21.0) Gecko/20100101 Firefox/21.0\"", "auth" => "-" } { "verb" => "GET", "bytes" => "1015", "type" => "log", "host" => "gxt_126_233", "httpversion" => "1.1", "message" => "66.249.73.185 - - [04/Jan/2015:05:18:48 +0000] \"GET /reset.css HTTP/1.1\" 200 1015 \"-\" \"Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)\"", "timestamp" => "04/Jan/2015:05:18:48 +0000", "referrer" => "\"-\"", "@timestamp" => 2020-06-17T01:23:47.815Z, "path" => "/data/hd05/elk/logstash-tutorial.log", "ident" => "-", "response" => "200", "@version" => "1", "request" => "/reset.css", "clientip" => "66.249.73.185", "agent" => "\"Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)\"", "auth" => "-" } { "verb" => "GET", "bytes" => "28370", "type" => "log", "host" => "gxt_126_233", "httpversion" => "1.0", "message" => "207.241.237.220 - - [04/Jan/2015:05:21:16 +0000] \"GET /blog/tags/projects HTTP/1.0\" 200 28370 \"http://www.semicomplete.com/blog/tags/C\" \"Mozilla/5.0 (compatible; archive.org_bot +http://www.archive.org/details/archive.org_bot)\"", "timestamp" => "04/Jan/2015:05:21:16 +0000", "referrer" => "\"http://www.semicomplete.com/blog/tags/C\"", "@timestamp" => 2020-06-17T01:23:47.817Z, "path" => "/data/hd05/elk/logstash-tutorial.log", "ident" => "-", "response" => "200", "@version" => "1", "request" => "/blog/tags/projects", "clientip" => "207.241.237.220", "agent" => "\"Mozilla/5.0 (compatible; archive.org_bot +http://www.archive.org/details/archive.org_bot)\"", "auth" => "-" }
執行結果
首先安裝nginx:nginx功能介紹和基本安裝
這裏我們也不使用filebeat,因為這篇文章只是介紹logstash
配置:
cd conf.d/ vim nginx.conf ############nginx.conf配置如下##################### input { file { path => "/usr/local/nginx/logs/access.log" type => "log" start_position => "beginning" } } filter { grok { match => { "message" => ["(?<RemoteIP>(\d*.\d*.\d*.\d*)) - %{DATA:[nginx][access][user_name]} \[%{HTTPDATE:[nginx][access][time]}\] \"%{WORD:[nginx][access][method]} %{DATA:[nginx][access][url]} HTTP/%{NUMBER:[nginx][access][http_version]}\" %{NUMBER:[nginx][access][response_code]} %{NUMBER:[nginx][access][body_sent][bytes]} \"%{DATA:[nginx][access][referrer]}\" \"%{DATA:[nginx][access][agent]}\""] } add_field => { "Device" => "Charles Desktop" } remove_field => "message" remove_field => "beat.version" remove_field => "beat.name" } } output { elasticsearch { hosts => ["192.168.110.130:9200"] index => "nginx-log-%{+YYYY.MM.dd}" } }
如上的配置中輸出到elasticsearch中,這裏沒有設置密碼,所以不需要用戶和密碼,還有就是這裏使用的默認模板,如果想要修改的話可以使用,可以添加如下配置:
user => "elastic" #用戶 password => "${ES_PWD}" #通過keystore存儲的密碼 manage_template => false #關閉默認的模板 template_name => "elastic-slowquery" #指定自定義的模板
執行命令啟動logstash
cd logstash-7.7.0/ && ./bin/logstash -f conf.d/nginx.conf
執行的結果(查看elasticsearch集群):
從上面的兩個圖看,一個創建了我們在nginx.conf中指定的一個索引,然後索引的內容都是解析出來的一些字段內容。
這是實例我們採用filebeat+logstash+elasticsearch,還有權限驗證進行試驗:
這裏主要是對elasticsearch的慢日誌查詢做解析,雖然我在一篇文章搞懂filebeat(ELK)中篇文章中直接通過filebeat的elasticsearch(beat版本)的模塊對其做過解析,但是解析的還是不夠特別完善,這裏引入logstash對其解析,過濾。
首先配置filebeat文件(這裏只配置了一個輸入和一個輸出,沒有做多餘的處理,只是用來收集日誌):
#=========================== Filebeat inputs ============================= filebeat.inputs: # Each - is an input. Most options can be set at the input level, so # you can use different inputs for various configurations. # Below are the input specific configurations. - type: log # Change to true to enable this input configuration. enabled: true # Paths that should be crawled and fetched. Glob based paths. paths: - /var/logs/es_aaa_index_search_slowlog.log - /var/logs/es_bbb_index_search_slowlog.log #- c:\programdata\elasticsearch\logs\* #================================ Outputs ===================================== # Configure what output to use when sending the data collected by the beat. #----------------------------- Logstash output -------------------------------- output.logstash: # The Logstash hosts hosts: ["192.168.110.130:5044","192.168.110.131:5044","192.168.110.132:5044"] loadbalance: true #這裏採用負載均衡機制, # Optional SSL. By default is off. # List of root certificates for HTTPS server verifications #ssl.certificate_authorities: ["/etc/pki/root/ca.pem"] # Certificate for SSL client authentication #ssl.certificate: "/etc/pki/client/cert.pem" # Client Certificate Key #ssl.key: "/etc/pki/client/cert.key"
然後啟動filebeat:
cd filebeat-7.7.0-linux-x86_64 && ./filebeat -e
然後配置logstash的配置文件:
cd conf.d/ vim es.conf ############es.conf配置如下############## input { beats{ port => 5044 } } filter { grok { match => {"message" => "\[%{TIMESTAMP_ISO8601:query_time},%{NUMBER:number1}\]\s*\[%{DATA:log_type}\]\s*\[%{DATA:index_query_type}\]\s*\[%{DATA:es_node}\]\s*\[%{DATA:index_name}\]\s*\[%{NUMBER:share_id}\]\s*took\[%{DATA:times_s}\],\s*took_millis\[%{NUMBER:query_times_ms}\],\s*types\[%{DATA:types}\],\s*stats\[%{DATA:status}\],\s*search_type\[%{DATA:search_type}\],\s*total_shards\[%{NUMBER:total_shards}\],\s*source\[%{DATA:json_query}\],\s*extra_source"} remove_field => ["message","@version","status","times_s","@timestamp","number1"] } mutate{ convert => { "query_times_ms" => "integer" } } } output { elasticsearch { hosts => ["192.168.110.130:9200","192.168.110.131:9200","192.168.110.132:9200"] index => "elastic-slowquery-222" user => "elastic" password => "${ES_PWD}" manage_template => false template_name => "elastic-slowquery" } }
如上配置使用了用戶的權限驗證,以及elasticsearch的自定義模板
啟動logstash
cd logstash-7.7.0/ && ./bin/logstash -f conf.d/es.conf
登錄es查看結果:
logstash就介紹到這裏了,如果有疑問多看官網比較好
參考:
logstash官網:https://www.elastic.co/guide/en/logstash/current/index.html
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?
摘錄自2018年8月21日中央廣播電台報導
路透社報導,在執政聯盟內部的反對下,澳洲總理滕博爾(Malcolm Turnbull)今天(20日)取消能源政策中要求減少排放溫室氣體的部分。但他表示,澳洲仍信守巴黎氣候協議(Paris Agreement)承諾。
滕博爾政府的能源政策「國家能源保障」(National Energy Guarantee),先前要求發電產業的溫室氣體排放量,到2030年以前,必須比2005年減少26%。
墨爾本大學(University of Melbourne)政治學教授艾克斯利(Robyn Eckersley)則說:「這完全是對澳洲自由黨(Liberal Party)
右翼成員投降,他們希望永久保留澳洲的煤礦經濟。」
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準
摘錄自2018年8月24日中央社報導
法國政府規劃在南部庇里牛斯山區野放兩頭母熊以促進繁衍。這片山區目前只有43頭熊,其中一頭保有當地原生熊的最後血脈,即使畜牧業者反對,政府對野放的態度也是勢在必行。
根據法國國家狩獵及野生動物局(ONCFS)於2017年調查,庇里牛斯山區還有43頭熊,但棲息地分布不平衡,主要集中在山區的中部和東部,西部只有兩頭公熊。
因此,生態部規劃今年秋天把兩頭生於斯洛維尼亞的母熊引入庇里牛斯山西北部的貝亞納(Bearn)地區,讓物種有機會繁衍。
庇里牛斯山-大西洋省(Pyrenees-Atlantiques)和奧克西塔尼大區(Occitanie)警署於今年6月到7月調查約6000名網路使用者的意願,結果顯示多達88.9%的受調者贊成引入兩頭熊到庇里牛斯山,只有8.9%不贊成。
在所有受調者中,約27%是庇里牛斯山區附近省份的居民,這些人有71.6%贊成野放,25.4%反對;若只看貝亞納地區的「當事人」意見,贊成比率降到58.6%,但仍超過半數。
法國政府今年5月公布2018年到2028年「庇里牛斯山區棕熊保育計畫」,未來10年內可能會執行不只一次的野放計畫,若牧羊人因熊攻擊而蒙受損失,也會予以賠償。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?
| |
經濟參考報報導,中國產自佛山(雲浮)產業轉移工業園的氫能燃料電池汽車,在今年《北京國際風能與中國太陽能大會暨展覽會》上,吸引眾多人的圍觀。在展期間舉行的「氫產業•氫生活•氫未來」主題新聞發布會上,業內人士認為,氫能早已過了概念性的階段,預計三到五年時間內,氫能產業即會進入爆發期。 中國科技部部長萬鋼日前在第十九屆中國科協年會上也表示,氫具來源廣泛、大規模穩定儲存、持續供應、遠距離運輸以及快速補充等特點,在未來車用能源中,氫燃料與電力將並存互補,共同支撐新能源汽車產業發展;且必須加強協同創新,加快推動氫能燃料電池產業全面發展。 目前,中國各地也都在積極推動燃料電池發展。今年9月上海發布《上海市燃料電池汽車發展規畫》,規劃到2020年,上海將會聚集超過100家燃料電池汽車相關企業,於2025年建成50座加氫站,到2030年實現燃料電池汽車技術和製造整體達到海外同等水準,上海燃料電池汽車全產業鏈年產值突破3,000億元人民幣。 而上述來自佛山產業轉移工業園的氫能燃料電池汽車,則包含氫能乘用車、氫燃料電池城市客車以及燃料電池物流車等多款車型。同時,2016年5月,廣東國鴻氫能科技與加拿大巴拉德簽署引進9SSL電堆生產線技術協定,在中國建設年生產兩萬台電堆和5,000套系統的首條商業化燃料電池電堆及系統整合生產線,該項目已於今年7月1日正式投產,首批試製電堆樣品主要性能指標達到國際先進水準,計畫今年生產3000台9SSL電堆,系統整合1,000套。 佛山市委常委許國也認為,現在氫能產業發展最大的障礙不是技術而是基礎設施建設。不過,預計後續加氫站的建設在中國會取得突飛猛進的效果,中國央企尤其是中石化正在對中國的加油站合建加氫站的問題進行全面布局。 中國全國氫能標準技術委員會高級顧問陳霖新認為,氫能早已過了概念性的階段,現在要進入踏踏實實發展的階段。許國則判斷,中國國家政策還是以示範為主,未來產業技術好的區域自然能搶佔先機,取得更多的市場份額,預計在未來三到五年時間內,即2020年左右,氫能產業會取得突飛猛進的發展,而這個爆發點只會提前不會推遲。 (本文內容由授權使用。首圖來源:by pixelfreestyle via Flickr CC2.0)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※台北網頁設計公司這麼多該如何選擇?
※智慧手機時代的來臨,RWD網頁設計為架站首選
※評比南投搬家公司費用收費行情懶人包大公開
※回頭車貨運收費標準

 |
對石油巨擘來說,最大的心腹之患,就是未來電動車若普及,最大宗石油需求之一:內燃機車輛用的汽柴油,就會大幅萎縮,其次則是終有一日可再生能源發展到不只可取代煤,還能取代燃氣發電,往往與石油一併產出的天然氣也不知該何處去了。依此觀點,油氣大廠應該全面抵制電動車與綠能,不過,資本家想的不一樣,不管是出於避險,或是「打不贏就加入」,國際油氣大廠殼牌、道達爾大力投資電動車、綠能。 電動車發展的最大障礙之一就是充電站不夠普及,而石油巨擘殼牌(Shell)不旦不針對這點打擊潛在對手,還「贈敵予鹽」出手相助。2017 年 10 月 13 日,殼牌宣布購併電動車充電站企業 NewMotion,NewMotion 身為歐洲最大電動車充電網路之一,旗下管理 3 萬座住宅與商業充電站,加上其他結盟充電站系統,並可提供車主使用 5 萬座以上充電站。 殼牌會不會採取是「買下後拋棄」策略,購併關鍵環節後,藉由故意拖慢其發展,打算藉此拖累電動車的普及進度?就殼牌的動作來說,看來並不像,因為殼牌不僅大動作投資 NewMotion,更實際推動充電站數量增加,在殼牌加油站本身就提供電動車快速充電服務,可於 30 分鐘內充電 80%。殼牌此計畫預定將從英國北部開始,從英國 400 座殼牌加油站先挑選 10 座測試。除了支援電動車的充電站,殼牌還將於 2017 年內於英國 3 個所屬加油站設立氫燃料電池車的加氫站。
 |
(Source:Flickr/Mike Mozart CC BY 2.0) 事實上殼牌並非突發奇想,投資綠能早已是殼牌的長期策略。殼牌目前每年投資 2 億美元在可再生能源,更計畫到 2020 年時提升到 10 億美元;推動電動車充電站的計畫也不僅在英國,還包括挪威、菲律賓、荷蘭。殼牌積極跨足電動車可說是未雨綢繆,根據殼牌自身估算,2040 年全球將有四分之一汽車為電動車,在傳統汽車市佔不可避免逐漸受侵蝕的情況下,殼牌當然得先在電動車領域建立灘頭堡。 法國石油巨擘道達爾的看法也英雄所見略同。道達爾估計至 2030 年時電動車將佔有新車市場 15%~30%,石油需求預計屆時將達頂峰,之後不再成長甚至逐漸下滑。艾克森美孚(ExxonMobil)、英國石油(BP)則分別預期到 2035 年、2040 年,全球電動車總數量就會超過 1 億輛。 因此,殼牌買下 NewMotion,道達爾也出手買下兼營天然氣與電動車充電的 PitPoint,殼牌也與道達爾共同參與全球氫能會議未來 5 年對氫能 107 億美元的投資。殼牌也擁有 400 百萬瓦(megawatt)規模的風力發電場。英國石油則在美國擁有 1.5 吉瓦(gigawatt)風力發電容量。挪威國家石油公司(Statoil)則計劃將於 2018 年為蘇格蘭 Hywind 漂浮式離岸風電計畫添加 1,000 度電儲能容量的鋰電池能源儲存系統。
 |
(Source:statoil) 除此之外,道達爾先前 2017 年 9 月大舉投資法國 EREN 集團可再生能源部門(EREN RE),以 2.375 億歐元買下 23% 股權,以及 5 年內可買下剩下所有股權的選擇權。EREN 可再生能源部門將改名為「道達爾 EREN」,道達爾表示希望此投資能大幅加速道達爾打進太陽能與風能市場的速度;同月,道達爾也買下法國節能公司 GreenFlex。 道達爾先前已宣布 2035 年前將投資五分之一資產配置於可再生能源,先前就已積極投資,2011 年注資 14 億美元投資美國晶矽太陽能電池龍頭太陽能源(SunPower),到 2017 年並設立道達爾太陽能部門,打算發展商用及工業等級太陽能發電場;2016 年時,道達爾斥資 11 億美元買下生產鎳氫、鎳鎘與一次性鋰電池的法國電池廠 Saft,道達爾風險創投部門則投資美國風機租賃業者聯合風能(United Wind)。 比起其他同業,艾克森美孚則較鍾情替代燃料。2009 年時宣布注資 6 億美元與合成基因公司(Synthetic Genomics)合作,發展藻類生質燃料,當時艾克森美孚樂觀認為 10 年內就能有所成果,不過如今改為預期要數十年。合成基因以基因科技改造藻類,以提升製造燃料的效率,原本藻類只製造 10%~15% 油脂,這個先天問題讓眾多藻類生質燃料新創企業都遇上困難,但透過基因改造後,2017 年 6 月艾克森美孚與合成基因發表成果,可將藻類製造油脂率拉升到 40%。即使如此,要達到商業可行的規模與成本,還有相當距離。 生質燃料受葉綠素光能轉換率遠低於太陽能電池的基本理論弱點影響,發展遠遜於其他可再生能源,這使艾克森美孚想要靠生質燃料在減碳辯論時保住內燃機汽車的努力可能終究化為泡影。即使最「鐵齒」的艾克森美孚也與電動車有沾到邊,艾克森美孚化學部門早在 2008 年就曾發表生產電動車用電池的薄膜,供應給加拿大電池廠 Electrovaya,用於當年推出的原型電動車 Maya-300。 當前,這些石油巨擘最主要的投資重心仍然還是油氣本業,道達爾最近最大筆投資,是以 75 億美元買下快桅油氣(Maersk Oil & Gas);殼牌每年花在油氣新計畫的預算高達 250 億美元。比起來,雙方對電動車、綠能相關投資,仍是小巫見大巫,這樣的投資規模比例,比較是「避險」性質,還沒有到全盤轉型的程度。
 |
(Source:Ørsted ) 不過,隨著電動車與可再生能源技術日漸成熟,市場接受度也越來越高,或許有一天,會看到過往的石油巨擘,成為電動車或綠能巨擘,一如丹能集團(DONG Energy)原為丹麥石油與天然氣(Danish Oil and Natural Gas)縮寫,積極由傳統能源公司轉型成為綠能公司,並將公司名稱改為沃旭能源(Ørsted )的例子。 (合作媒體:。)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※南投搬家公司費用需注意的眉眉角角,別等搬了再說!
※教你寫出一流的銷售文案?