why 樹形結構
順序存儲的特點是各個存儲單位在邏輯和物理內存上都是相鄰的,典型的就是代表就是數組,物理地址相鄰因此我們可以通過下標很快的檢索出一個元素
我們想往數組中添加一個元素最快的方式就是往它的尾部添加.如果往頭部添加元素的話,效率就很低,因為需要將從第一個元素開始依次往後移動一位,這樣就能空出第一位的元素,然後才能我們指定的數據插入到第一個的位置上
鏈式存儲的特點是,各個節點之間邏輯是相鄰的,但是物理存儲上不相鄰,每一個節點都存放一個指針或者是引用用來指向它的前驅或者後繼節點, 因此我們想插入或者刪除一個元素時速度就會很塊,只需要變動一下指針的指向就行
但是對鏈表來說查找是很慢的, 因此對任意一個節點來書,他只知道自己的下一個節點或者是上一個節點在哪裡,再多的他就不不知道了,因此需要從頭結點開始遍歷…
樹型存儲結構有很多種,比如什麼二叉樹,滿二叉樹,紅黑樹,B樹等, 對於樹形結構來說,它會相對中和鏈式存儲結構和順序存儲結構的優缺點 (其中二叉排序樹最能直接的體會出樹中和鏈式存儲和線性存儲的特性,可以通過右邊的導航先去看看二叉排序樹)
樹的概述
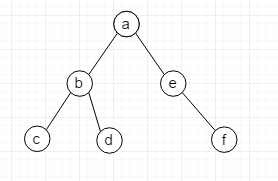
如上圖是一個二叉樹, 當然樹還能有三叉,四叉等等…
- 根節點: 最頂上的節點 即A
層: 根節點在第一層 BE在第二層
高度: 最大的層數
森林: 多個樹的組合
權: 節點上的值 如根節點的權是 A
恭弘=叶 恭弘子節點: 下層上的節點是上一層的恭弘=叶 恭弘子節點
雙親節點: 上層的節點是下層的節點的雙親節點(單個節點又是爸又是媽)
路徑: 找到C的路徑是 A-B-C
度: 就是直接子節點的個數
普通二叉樹
顧名思義就是度最大為2的樹就是二叉樹.而且對二叉樹來說,是嚴格區分左子樹和右子樹的,看上圖,雖然兩個樹的根節點都是1,但是他們的左右子樹不同,因此他們並不是相同的樹
像上圖這樣,所有的恭弘=叶 恭弘子節點都在最後一層,所有的且除了最後一層其他層的節點都有兩個子節點
二叉樹的全部節點計算公式是 2^n-1 , n是層數
像上圖這樣, 所有的恭弘=叶 恭弘子點都在最後一層或者是倒數第二層, 並且從左往右數是連續的
java&二叉樹
public class TreeNode {
// 權
private int value;
// 左節點
private TreeNode leftNode;
// 右節點
private TreeNode rightNode;
}
public class BinaryTree {
TreeNode root;
public void setRoot(TreeNode root) {
this.root = root;
}
public TreeNode getRoot() {
return this.getRoot();
}
}
遍歷
像這樣一顆二叉樹,通過不同的書序遍歷會得到不同的結果
前中后的順序說的是root節點的順序,前序的話就是先遍歷父節點, 中序就是左父右 後續就是左右父
public void frontShow() {
System.out.println(this.value);
if (leftNode != null)
leftNode.frontShow();
if (rightNode != null)
rightNode.frontShow();
}
public void middleShow() {
if (leftNode != null)
leftNode.middleShow();
System.out.println(value);
if (rightNode != null)
rightNode.middleShow();
}
public void backShow() {
if (leftNode != null)
leftNode.backShow();
if (rightNode != null)
rightNode.backShow();
System.out.println(value);
}
查找
其實有了上面三種遍歷的方式, 查找自然存在三種, 一遍遍歷一遍查找
public TreeNode frontSeach(int num) {
TreeNode node = null;
// 當前節點不為空,返回當前節點
if (num == this.value) {
return this;
} else {
// 查找左節點
if (leftNode != null) {
node = leftNode.frontSeach(num);
}
if (node != null)
return node;
// 查找右節點
if (rightNode != null)
node = rightNode.frontSeach(num);
}
return node;
}
刪除節點
刪除節點也是, 不考慮特別複雜的情況, 刪除節點就有兩種情況, 第一種要刪除的節點就是根節點, 那麼讓根節點=null就ok, 第二種情況要刪除的節點不是根節點,就處理它的左右節點, 左右節點還不是需要刪除的元素的話那麼就得遞歸循環這個過程
// 先判斷是否是根節點,在調用如下方法
public void deleteNode(int i) {
TreeNode parent = this;
// 處理左樹
if (parent.leftNode!=null&&parent.leftNode.value==i){
parent.leftNode=null;
return;
}
// 處理左樹
if (parent.rightNode!=null&&parent.rightNode.value==i){
parent.rightNode=null;
return;
}
// 遞歸-重置父節點
parent=leftNode;
if (parent!=null)
parent.deleteNode(i);
// 遞歸-重置父節點
parent=rightNode;
if (parent!=null)
parent.deleteNode(i);
}
順序存儲二叉樹
文章一開始剛說了, 順序存儲的數據結構的典型代表就是數組, 就像這樣
[1,2,3,4,5,6,7]
什麼是順序存儲的二叉樹呢? 其實就是將上面的數組看成了一顆樹,就像下圖這樣
數組轉換成二叉樹是有規律的, 這個規律就體現在他們的 下標的關聯上, 比如我們想找2節點的左子節點的下標就是 2*n -1 = 3 , 於是我們從數組中下標為3的位置取出4來
- 第n個元素的左子節點是 2n-1
- 第n個元素的右子節點是 2n-2
-
第n個元素的父節點是 (n-1)/2
-
遍歷順序存儲的二叉樹
public void frontShow(int start){
if (data==null||data.length==0){
return;
}
// 遍歷當前節點
System.out.println(data[start]);
// 遍歷左樹
if (2*start+1<data.length)
frontShow(2*start+1);
// 遍歷右樹
if (2*start+2<data.length)
frontShow(2*start+2);
}
線索二叉樹
假設我們有下面的二叉樹, 然後我們可以使用中序遍歷它, 中序遍歷的結果是 4,2,5,1,3,6 但是很快我們就發現了兩個問題, 啥問題呢?
-
問題1: 雖然可以正確的遍歷出 4,2,5,1,3,6 , 但是當我們遍歷到2時, 我們是不知道2的前一個是誰的,(哪怕我們剛才遍歷到了它的前一個節點就是4)
-
問題2: node4,5,6,3的左右節點的引用存在空閑的情況
針對這個現狀做出了改進就是線索化二叉樹, 它可以充分利用各個節點中剩餘的node這個現狀…線索化后如下圖
- 如果這個節點的右節點為空,我們就讓它讓它指向自己的後繼節點, 例如上圖的紅線
- 如何節點的左節點為空, 就讓這個空閑的節點指向它的前驅節點,例如上圖的藍色線
這樣的話, 就實現了任意獲取出一個節點我們都能直接的得知它的前驅節點后後繼節點到底是誰
java&中序化二叉樹;
思路: 按照原來中序遍歷樹的思路,對樹進行中序遍歷,一路遞歸到4這個節點, 檢查到它的左節點為空,就將他的左節點指向它的前驅節點, 可是4本來就是最前的節點,故4這個節點的左節點自然指向了null
然後看它的右節點也為空,於是將他的右節點指向它的後繼節點, 可是這時依然沒獲取到2節點的引用怎麼辦呢? 於是先找個變量將4節點臨時存起來, 再往後遞歸,等遞歸到2節點時,取出臨時變量的4節點, 4節點.setRightNode(2節點)
然後重複這個過程
// 臨時保存上一個節點
private TreeNode preNode;
// 中序線索化二叉樹
void threadNode(TreeNode node) {
if (node == null)
return;
// 處理左邊
threadNode(node.getLeftNode());
// 左節點為空,說明沒有左子節點, 讓這個空出的左節點指向它的上一個節點
if (node.getLeftNode() == null) {
// 指向上一個節點
node.setLeftNode(preNode);
// 標識節點的類型
node.setLeftType(1);
}
// 處理前驅節點的右指針
// 比如現在遍歷到了1, 1的上一個節點是5, 5的右邊空着了, 於是讓5的有節點指向1
if (preNode != null && preNode.getRightNode() == null) {
preNode.setRightNode(node);
preNode.setRightType(1);
}
// 每次遞歸調用一次這個方法就更新前驅節點
preNode = node;
// 處理右邊
threadNode(node.getRightNode());
}
遍歷二叉樹
public void threadIterator() {
TreeNode node = root;
while (node != null) {
// 循環找
while (node.getLeftType() == 0)
node = node.getLeftNode();
// 打印當前節點
System.out.println(node.getValue());
// 如果當前的節點的右type=1說明它有指針指向自己的前一個節點
// 比如現在位置是4, 通過下面的代碼可以讓node=2
while (node.getRightType() == 1) {
node = node.getRightNode();
System.out.println(node.getValue());
}
// 替換遍歷的節點, 可以讓 node從2指向 5, 或者從3指向1
node = node.getRightNode();
}
}
赫夫曼樹(最優二叉樹)
定義: 什麼是赫夫曼樹
赫夫曼樹又稱為最優二叉樹
定義: 在N個帶權的恭弘=叶 恭弘子節點的所組成的所有二叉樹中,如果你能找出那個帶權路徑最小的二叉樹,他就是赫夫曼樹
一說起來赫夫曼樹,其實我們可以只關心它的恭弘=叶 恭弘子節點, 權, 路徑這三個要素
所謂權,其實就是節點的值, 比如上圖中node4的權是8 , node5的權是6 ,node3的權是1, 而且我們只關心恭弘=叶 恭弘子節點的權
啥是帶權路徑呢? 比如上圖中 node4的帶權路徑是 1-2-4
- 樹的帶權路徑長度(weight path length) 簡稱 WPL
其實就是這個樹所有的恭弘=叶 恭弘子節點的帶權路徑長度之和,
計算左樹的WPL =2*8+2*6+1*1 = 29
計算左樹的WPL =2*1+2*6+1*8 = 22
總結: 權值越大的節點,離根節點越近的節點是最優二叉樹
### 實戰: 將數組轉換為赫夫曼樹
假設我們現在已經有了數組 [3,5,7,8,11,14,23,29], 如何將這個數組轉換成赫夫曼樹呢?
取出這裏最小的node3 和 倒數第二小的node5 ,構建成新的樹, 新樹的根節點是 node3,5的權值之和, 將構建完成的樹放回到原數組中
重複這個過程, 將最小的node7,node8取出,構建新樹, 同樣新樹的權重就是 node7,8的權重之和, 再將構建完成的樹放回到原數組中
如此往複,最終得到的樹就是huffman樹
封裝TreeNode, 看上面的過程可以看到,需要比較權重的大小,因此重寫它的compareTo方法
public class TreeNode implements Comparable{
// 權
private int value;
private TreeNode leftNode;
private TreeNode rightNode;
@Override
public int compareTo(Object o) {
TreeNode node = (TreeNode) o;
return this.value-node.value;
}
構建赫夫曼樹, 思路就是上圖的過程, 將數組中的各個元素轉換成Node. 然後存放在List容器中,每輪構建新樹時需要排序, 當集合中僅剩下一個節點,也就是根節點時完成樹的構建
// 創建赫夫曼樹
private static TreeNode buildHuffmanTree(int[] arr) {
// 創建一個集合,存放將arr轉換成的二叉樹
ArrayList<TreeNode> list = new ArrayList<>();
for (int i : arr) {
list.add(new TreeNode(i));
}
// 開始循環, 當集合中只剩下一棵樹時
while (list.size() > 1) {
// 排序
Collections.sort(list);
// 取出權值最小的數
TreeNode leftNode = list.get(list.size() - 1);
// 取出權值次要小的數
TreeNode rightNode = list.get(list.size() - 2);
// 移除取出的兩棵樹
list.remove(leftNode);
list.remove(rightNode);
// 創建新的樹根節點
TreeNode parentNode = new TreeNode(leftNode.getValue() + rightNode.getValue(), leftNode, rightNode);
// 將新樹放到原樹的集合中
list.add(parentNode);
}
return list.get(0);
}
實戰: 赫夫曼樹與數據壓縮
通過上面的介紹我們能直觀的看出來,赫夫曼樹很顯眼的特徵就是它是各個節點能組成的樹中,那顆WPL,帶權路徑長度最短的樹, 利用這條性質常用在數據壓縮領域, 即我們將現有的數據構建成一個赫夫曼樹, 其中出現次數越多的字符,就越靠近根節點, 經過這樣的處理, 就能用最短的方式表示出原有字符
假設我們有這條消息can you can a can as a canner can a can.
數據對計算機來說不過是0-1這樣的数字, 我們看看將上面的字符轉換成01這樣的二進制數它長什麼樣子
1. 將原字符串的每一個char強轉換成 byte == ASCII
99 97 110 32 121 111 117 32 99 97 110 32 97 32 99 97 110 32 97 115 32 97 32 99 97 110 110 101 114 32 99 97 110 32 97 32 99 97 110
2. 將byte toBinaryString 轉換成01串如下:
1100011110000111011101000001111001110111111101011
0000011000111100001110111010000011000011000001100
0111100001110111010000011000011110011100000110000
1100000110001111000011101110100000110001111000011
1011101101110110010111100101000001100011110000111
011101000001100001100000110001111000011101110101110
也就是說,如果我們不對其進行壓縮時, 它將會轉換成上面那一大坨在網絡上進行傳輸
使用赫夫曼進行編碼:
思路: 我們將can you can a can as a canner can a can. 中的每一個符號,包括 點 空格,全部封裝進TreeNode
TreeNode中屬性如下: 包含權重: 也就是字符出現的次數, 包含data: 字符本身
public class TreeNode implements Comparable{
// 存放權重就是字符出現的次數
private int weight;
// 存放英文數值
private Byte data; //
private TreeNode leftNode;
private TreeNode rightNode;
封裝完成后, 按照權重的大小倒序排序,各個節點長成這樣:
a:11 :11 n:8 c:7 o:1 .:1 y:1 e:1 u:1 s:1 r:1
將赫夫曼樹畫出來長這樣:
特徵,我們讓左側的路徑上的值是0, 右邊是1. 因此通過這個赫夫曼樹其實我們可以得到一張赫夫曼編碼錶,
比如像下面這樣:
n: 00
: 01
a: 10
c: 111
// 每一個字符的編碼就是從根節點到它的路徑
有了這樣編碼錶, 下一步就是對數據進行編碼, 怎麼編碼呢? 不就是做一下替換嗎? 我們現在開始循環遍歷一開始的字符串, 挨個取出裏面的字符, 比如我們取出第一個字符是c, 拿着c來查詢這個表發現,c的編碼是111,於是我們將c替換成111, 遍歷到第二個字符是a, 拿着a查詢表,發現a的值是10, 於是我們將a替換成10, 重複這個過程, 最終我們得到的01串明顯比原來短很多
怎麼完成解碼呢? 解碼也不複雜, 前提也是我們得獲取到huffman編碼錶, 使用前綴匹配法, 比如我們現在接收到了
1111000xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
使用前綴就是先取出1 去查查編碼錶有沒有這個數? 有的話就返回對應的字符, 沒有的話就用11再去匹配
大家可以看看上面的那顆霍夫曼樹, 所有的data都在恭弘=叶 恭弘子節點上,所以使用前綴匹配完全可以,絕對不會出現重複的情況
思路概覽:
- 將原生的字節數組轉化成一個個的TreeNode
- 取出所有的TreeNode封裝成赫夫曼樹
- 通過赫夫曼樹踢去出赫夫曼編碼錶
- 使用這個編碼錶進行編碼
- 解碼
private static byte[] huffmanZip(byte[] bytes) {
// 先統計每個byte出現的次數,放入集合中
List<TreeNode> treeNodes = buildNodes(bytes);
// 創建赫夫曼樹
TreeNode node = createHuffmanTree(treeNodes);
// 創建huffman編碼錶
Map<Byte, String> codes = createHuffmanCodeTable(node);
// 編碼, 將每一個byte替換成huffman編碼錶中的V
byte[] encodeBytes = encodeHuffmanByte(bytes, codes);
// 使用huffman編碼進行解碼
byte[] decodeBytes = decode(encodeBytes);
return decodeBytes;
}
將原生的byte數組,封裝成一個個的TreeNode節點,保存在一個容器中,並且記錄下這個節點出現的次數, 因此我們需要將出現次數多的節點靠近根節點
/**
* 將byte轉換成node集合
*
* @param bytes
* @return
*/
private static List<TreeNode> buildNodes(byte[] bytes) {
ArrayList<TreeNode> list = new ArrayList<>();
HashMap<Byte, Integer> countMap = new HashMap<>();
// 統計每一個節點的出現的次數
for (byte aByte : bytes) {
Integer integer = countMap.get(aByte);
if (integer == null) {
countMap.put(aByte, 1);
} else {
countMap.put(aByte, integer + 1);
}
}
// 將k-v轉化成node
countMap.forEach((k, v) -> {
list.add(new TreeNode(v, k));
});
return list;
}
構建赫夫曼樹
/**
* 創建huffman樹
*
* @param treeNodes
* @return
*/
private static TreeNode createHuffmanTree(List<TreeNode> treeNodes) {
// 開始循環, 當集合中只剩下一棵樹時
while (treeNodes.size() > 1) {
// 排序
Collections.sort(treeNodes);
// 取出權值最小的數
TreeNode leftNode = treeNodes.get(treeNodes.size() - 1);
// 取出權值次要小的數
TreeNode rightNode = treeNodes.get(treeNodes.size() - 2);
// 移除取出的兩棵樹
treeNodes.remove(leftNode);
treeNodes.remove(rightNode);
// 創建新的樹根節點
TreeNode parentNode = new TreeNode(leftNode.getWeight() + rightNode.getWeight(), leftNode, rightNode);
// 將新樹放到原樹的集合中
treeNodes.add(parentNode);
}
return treeNodes.get(0);
}
從赫夫曼樹中提取出編碼錶, 思路: 下面是完了個遞歸, 我們規定好左樹是0,右邊是1, 通過一個SpringBuilder, 每次迭代都記錄下原來走過的路徑,當判斷到它的data不為空時,說明他就是恭弘=叶 恭弘子節點,立即保存這個節點曾經走過的路徑,保存在哪裡呢? 保存在一個map中, Key就是byte value就是走過的路徑
static StringBuilder stringBuilder = new StringBuilder();
static Map<Byte, String> huffCode = new HashMap<>();
/**
* 創建huffman便編碼錶
*
* @param node
* @return
*/
private static Map<Byte, String> createHuffmanCodeTable(TreeNode node) {
if (node == null)
return null;
getCodes(node.getLeftNode(), "0", stringBuilder);
getCodes(node.getRightNode(), "1", stringBuilder);
return huffCode;
}
/**
* 根據node, 獲取編碼
*
* @param node
* @param code
* @param stringBuilder
*/
private static void getCodes(TreeNode node, String code, StringBuilder stringBuilder) {
StringBuilder sb = new StringBuilder(stringBuilder);
sb.append(code);
// 如果節點的data為空,說明根本不是恭弘=叶 恭弘子節點,接着遞歸
if (node.getData() == null) {
getCodes(node.getLeftNode(), "0", sb);
getCodes(node.getRightNode(), "1", sb);
} else {
// 如果是恭弘=叶 恭弘子節點,就記錄它的data和路徑
huffCode.put(node.getData(), sb.toString());
}
}
根據赫夫曼編碼錶進行編碼:
思路:
舉個例子: 比如,原byte數組中的一個需要編碼的字節是a
a的ASCII==97
97正常轉成二進制的01串就是 0110 0001
但是現在我們有了編碼錶,就能根據97從編碼錶中取出編碼: 10
換句話說,上面 0110 0001 和 10 地位相同
若干個需要編碼的數append在一起,於是我們就有了一個比原來短一些的01串, 但是問題來了,到這裏就結束了嗎? 我們是將這些01串轉換成String, 在getBytes()返回出去嗎? 其實不是的,因為我們還需要進行解碼,你想想解碼不得編碼map中往外取值? 取值不得有key? 我們如果在這裏將這個01串的byte數組直接返回出去了,再按照什麼樣的方式將這個byte[]轉換成String串呢? ,因為我們要從這個String串中解析出key
然後這裏我們進行約定, 將現在得到的01串按照每8位為一組轉換成int數, 再將這個int強轉成byte, 解碼的時候我們就知道了.就按照8位一組進行解碼. 解析出來數組再轉換成01串,我們就重新拿到了這個編碼后的01串,它是個String串
每遇到8個0或者1,就將它強轉成Int, 再強轉成type, 經過這樣的轉換可能會出現負數,因此01串的最前面有個符號位,1表示負數
比如說: 如果你打印一下面代碼中的encodeByte,你會發現打印的第一個數是-23, 這個-23被保存在新創建的byte數組的第一個位置上, 後續解碼時,就從這個byte數組中的第一個位置上獲取出這個-23, 將它轉換成01二進制串
怎麼轉換呢? 比如不是-23, 而是-1
真值 1
原碼:1,0001
補碼: 2^(4+1) +1 = 100000 + (-1) = 1,1111
我們獲取到的結果就是1111
/**
* 進行編碼
*
* @param bytes
* @param codes
* @return
*/
private static byte[] encodeHuffmanByte(byte[] bytes, Map<Byte, String> codes) {
StringBuilder builder = new StringBuilder();
for (byte aByte : bytes) {
builder.append(codes.get(aByte));
}
// 將這些byte按照每8位一組進行編碼
int length = 0;
if (builder.length() % 8 == 0) {
length = builder.length() / 8;
} else {
length = builder.length() / 8 + 1;
}
// 用於存儲壓縮后的byte
byte[] resultByte = new byte[length];
// 記錄新byte的位置
int index = 0;
// 遍歷新得到的串
for (int i = 0; i < builder.length(); i += 8) {
String str = null;
if (i + 8 > builder.length()) {
str = builder.substring(i);
} else {
str = builder.substring(i, i + 8);
}
// 將八位的二進制轉換成byte
// 這裏出現負數了.... 涉及到補碼的問題
byte encodeByte = (byte) Integer.parseInt(str, 2);
// 存儲起來
resultByte[index] = encodeByte;
index++;
}
return resultByte;
}
解碼: 前面我們知道了,約定是按照8位轉換成的int 再轉換成type[] , 現在按照這個約定,反向轉換出我們一開始的01串
/**
* 按照指定的赫夫曼編碼錶進行解碼
*
* @param encodeBytes
* @return
*/
private static byte[] decode(byte[] encodeBytes) {
List<Byte> list = new ArrayList();
StringBuilder builder = new StringBuilder();
for (byte encodeByte : encodeBytes) {
// 判斷是否是最後一個,如果是最後一次不用用0補全, 因此最後一位本來就不夠8位
boolean flag = encodeByte == encodeBytes[encodeBytes.length - 1];
String s = byteToBitStr(!flag, encodeByte);
builder.append(s);
}
// 調換編碼錶的k-v
Map<String, Byte> map = new HashMap<>();
huffCode.forEach((k, v) -> {
map.put(v, k);
});
// 處理字符串
for (int i = 0; i < builder.length(); ) {
int count = 1;
boolean flag = true;
Byte b = null;
while (flag){
String key = builder.substring(i,i+count);
b=map.get(key);
if (b==null){
count++;
}else {
flag=false;
}
}
list.add(b);
i+=count;
}
// 將list轉數組
byte[] bytes = new byte[list.size()];
int i=0;
for (Byte aByte : list) {
bytes[i]=aByte;
i++;
}
return bytes;
}
/**
* 將byte轉換成二進制的String
*
* @param b
* @return
*/
public static String byteToBitStr(boolean flag, byte b) {
/**
* 目標: 全部保留八位.正數前面就補零, 負數前面補1
* 為什麼選256呢? 因為我們前面約定好了, 按照8位進行分隔的
* 256的二進製表示是 1 0000 0000
* 假設我們現在是 1
* 計算 1 0000 0000
* 或 0 0000 0001
* ----------------------
* 1 0000 0001
* 結果截取8位就是 0000 0001
*
* 假設我們現在是 -1
* 轉換成二進制: 1111 1111 1111 1111 1111 1111 1111 1111
*
* 計算 1 0000 0000
* 或 1111 1111 1111 1111 1111 1111 1111 1111
* ----------------------
* 1 1111 1111
* 結果截取8位就是 1111 1111
*
*
*/
int temp = b;
if (flag) {
temp |= 256;
}
String str = Integer.toBinaryString(temp);
if (flag) {
return str.substring(str.length() - 8);
} else {
return str;
}
}
二叉排序樹
二叉排序樹, 又叫二叉搜索樹 , BST (Binary Search Tree)
比如我們有一個數組 [7,3,10,12,5,1,9]
雖然我們可以直接取出下標為幾的元素,但是卻不能直接取出值為幾的元素, 比如,我們如果想取出值為9的元素的話,就得先去遍歷這個數組, 然後挨個看看當前位置的數是不是9 , 就這個例子來說我們得找7次
假設我們手裡的數組已經是一個有序數組了 [1,3,5,7,9,11,12]
我們可以通過二分法快速的查找到想要的元素,但是對它依然是數組,如果想往第一個位置上插入元素還是需要把從第一個位置開始的元素,依次往後挪. 才能空出第一個位置,把新值放進去
假設我們將這一行數轉換成鏈式存儲, 確實添加, 刪除變的異常方便, 但是查找還是慢, 不管是查詢誰, 都得從第一個開始往後遍歷
二叉排序樹有如下的特點:
- 對於二叉排序樹中的任意一個非恭弘=叶 恭弘子節點都要求他的左節點小於自己, 右節點大於自己
- 空樹也是二叉排序樹
將上面的無序的數組轉換成二叉排序樹長成下圖這樣
如果我們按照中序遍歷的話結果是: 1 3 5 7 9 11 12 , 正好是從小到大完成排序
再看他的特徵: 如果我們想查找12 , 很簡單 7-10-12 , 如果我們想插入也很簡單,它有鏈表的特性
java&二叉排序樹
封裝Node和Tree
// tree
public class BinarySortTree {
Node root;
}
// node
public class Node {
private int value;
private Node leftNode;
private Node rightNode;
}
構建一顆二叉排序樹, 思路是啥呢? 如果沒有根節點的話,直接返回,如果存在根節點, 就調用根節點的方法,將新的node添加到根節點上, 假設我們現在遍歷到的節點是NodeA. 新添加的節點是NodeB, 既然想添加就得比較一下NodeA和NodeB的值的大小, 將如果NodeB的值小於NodeA,就添加在NodeA的右邊, 反之就添加在NodeA的左邊
-----------BinarySortTree.class---------------
/**
* 向二叉排序樹中添加節點
*/
public void add(Node node) {
if (root == null) {
root = node;
} else {
root.add(node);
}
}
-------------Node.class------------
/**
* 添加節點
*
* @param node
*/
public void add(Node node) {
if (node == null)
return;
//判斷需要添加的節點的值比傳遞進來的節點的值大還是小
// 添加的節點小於當前節點的值
if (node.value < this.value) {
if (this.leftNode == null) {
this.leftNode = node;
} else {
this.leftNode.add(node);
}
} else {
if (this.rightNode == null) {
this.rightNode = node;
} else {
this.rightNode.add(node);
}
}
}
刪除一個節點
刪除一節點如如下幾種情況, 但是無論是哪種情況,我們都的保存當前節點的父節點, 通過他的父節點對應節點=null實現節點的刪除
情況1: 如圖
這是最好處理的情況, 就是說需要刪除的元素就是單個的子節點
情況2: 如圖
這種情況也不麻煩,我們讓當前比如我們想上刪除上圖中的3號節點, 我們首先保存下node3的父節點 node7, 刪除node3時發現node3有一個子節點,於是我們讓 node7 的 leftNode = node3
情況3: 如圖
比如我們想刪除7, 但是7這個節點還有一個子樹 按照中序遍歷這個樹的順序是 1,3,5,7,9,11,13, 想刪除7的話,其實
- 臨時存儲node9
- 刪除node9
- 用臨時存儲的node9替換node7
如果node9還有右節點怎麼辦呢?
- 臨時保存node9
- 刪除node9
- 讓node9的右節點替換node9
- 讓臨時存儲的node9替換node7
/**
* 刪除一個節點
*
* @param value
* @return
*/
public void delete(int value) {
if (root == null) {
return;
} else {
// 找到這個節點
Node node = midleSearch(value);
if (node == null)
return;
// 找到他的父節點
Node parentNode = searchParent(value);
// todo 當前節點是恭弘=叶 恭弘子節點
if (node.getLeftNode() == null && node.getRightNode() == null) {
if (parentNode.getLeftNode().getValue() == value) {
parentNode.setLeftNode(null);
} else {
parentNode.setRightNode(null);
}
// todo 要刪除的節點存在兩個子節點
} else if (node.getLeftNode() != null && node.getRightNode() != null) {
// 假設就是刪除7
//1. 找到右子樹中最小的節點,保存它的值,然後刪除他
int minValue = deleteMin(node.getRightNode());
//2.替換被刪除的節點值
node.setValue(minValue);
} else { // todo 要刪除的節點有一個左子節點或者是右子節點
// 左邊有節點
if (node.getLeftNode() != null) {
// 要刪除的節點是父節點的左節點
if (parentNode.getLeftNode().getValue() == value) {
parentNode.setLeftNode(node.getLeftNode());
} else {// 要刪除的節點是父節點的右節點
parentNode.setRightNode(node.getLeftNode());
}
} else { // 右邊有節點
// 要刪除的節點是父節點的右節點
if (parentNode.getLeftNode().getValue() == value) {
parentNode.setLeftNode(node.getRightNode());
} else {// 要刪除的節點是父節點的右節點
parentNode.setRightNode(node.getRightNode());
}
}
}
}
}
/**
* 刪除並保存以當前點為根節點的樹的最小值節點
* @param node
* @return
*/
private int deleteMin(Node node) {
// 情況1: 值最小的節點沒有右節點
// 情況2: 值最小的節點存在右節點
// 但是下面我們使用delete,原來考慮到了
while(node.getLeftNode()!=null){
node=node.getLeftNode();
}
delete(node.getValue());
return node.getValue();
}
/**
* 搜索父節點
*
* @param value
* @return
*/
public Node searchParent(int value) {
if (root == null) {
return null;
} else {
return root.searchParent(value);
}
}
缺點
二叉排序樹其實對節點權是有要求的, 比如我們的數組就是[1,2,3,4] 那麼畫成平衡二叉樹的話長下面這樣
它不僅沒有二叉排序樹的優點,而且還不如單鏈表的速度快
AVL樹(平衡二叉樹)
定義: 什麼是平衡二叉樹
平衡二叉樹的出現就是為了 解決上面二叉排序樹[1,2,3,4,5,6]這樣成單條鏈的略勢的情況,它要求,每個樹的左子樹和右子樹的高度之差不超過1, 如果不滿足這種情況了,馬上馬對各個節點進行調整,這樣做保證了二叉排序樹的優勢
如何調整
- 情況1: 對於node1來說, 它的左邊深度0 , 右邊的深度2 , 於是我們將它調整成右邊的樣子
- 情況2: 在1234的情況下, 添加node5,導致node2不平衡, 進行如下的調整
- 情況3: 在12345的基礎上添加node6,導致node4不平衡, 對node4進行調整, 其實就和情況1相同了
- 情況4: 在1234567的情況下,進行添加8. 打破了node5的平衡, 因此進行旋轉
一個通用的旋轉規律
看這個典型的有旋轉的例子
node4的出現,使用node8的平衡被打破, 因此我們需要進行調整, 按照下面的步驟進行調整
下面說的this是根節點node8, 按照下面的步驟在紙上畫一畫就ok
- 創建新node, 使新node.value = this.value
- 新節點的rightNode = this.rightNode
- 新節點的leftNode = this.leftNode.rightNode
- this.value = this.LeftNode.value
- this.leftNode = this.leftNode .leftNode
- this.leftNode = 新創建的node
需要注意的情況:
新添加6使得node8不再平衡,但是如果你按照上面的步驟進行旋轉的話,會得到右邊的結果, 但是右邊的結果中對於node4還是不平衡的,因此需要預處理一下
再進行右旋轉時,提前進行檢驗一下,當前節點的左子樹是否存在右邊比左邊高的情況, 如果右邊比較高的話,就先將這個子樹往左旋轉, 再以node8為根,整體往右旋轉
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※帶您來看台北網站建置,台北網頁設計,各種案例分享
※小三通物流營運型態?
※快速運回,大陸空運推薦?