環境資訊中心綜合外電;姜唯 編譯;林大利 審校
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※新北清潔公司,居家、辦公、裝潢細清專業服務
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?
※網頁設計最專業,超強功能平台可客製化
摘錄自2019年9月23日公視報導
瑞士居民為阿爾卑斯山的冰川舉行了葬禮,受氣候變遷影響,這座冰川從2006年消融速度加快,現在已經消失了90%面積。
大約250個瑞士居民,22日穿著黑衣,披著黑頭紗爬了約兩小時的路程,登上海拔約2700公尺的皮措爾山山頂,為這座即將消失的冰川舉行葬禮。
瑞士蘇黎世聯邦理工學院冰川專家赫斯表示,「照目前情況來看,我們還有約4個足球場大小的冰川,但過去兩年冰川消融的速度迅速增加。」
皮措爾冰川位在瑞士境內的阿爾卑斯山,自從2006年以來,已經失去了將近90%面積,現在只剩下約兩萬6000平方公尺,不到四個足球場大小,科學家認為,冰川消融如此快速是受到氣候變遷影響,如果再不控制溫室氣體排放,這座冰川將會在2030年前完全消失。
本站聲明:網站內容來源環境資訊中心https://e-info.org.tw/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?
※FB行銷專家,教你從零開始的技巧
chromedp是go寫的,支持Chrome DevTools Protocol 的一個驅動瀏覽器的庫。並且它不需要依賴其他的外界服務(比如 Selenium 和 PhantomJs)。
Chrome DevTools Protocol (CDP) 的主頁在:https://chromedevtools.github.io/devtools-protocol/。 它提供一系列的接口來查看,檢查,調整並且檢查 Chromium 的性能。Chrome 的開發者工具就是使用這一系列的接口,並且 Chrome 開發者工具來維護這些接口。
所謂 CDP 的協議,本質上是什麼呢?本質上是基於 websocket 的一種協議。比如
在我們打開 webtool 調試工具的時候,其實調試工具也是一個web頁面,兩個web頁面通過websocket建立了一個聯繫。
所以我們如果寫了一個客戶端程序,也和目標頁面創建一個基於 CDP 的 websocket連接,我們也可以通過這個協議來對頁面進行操作。
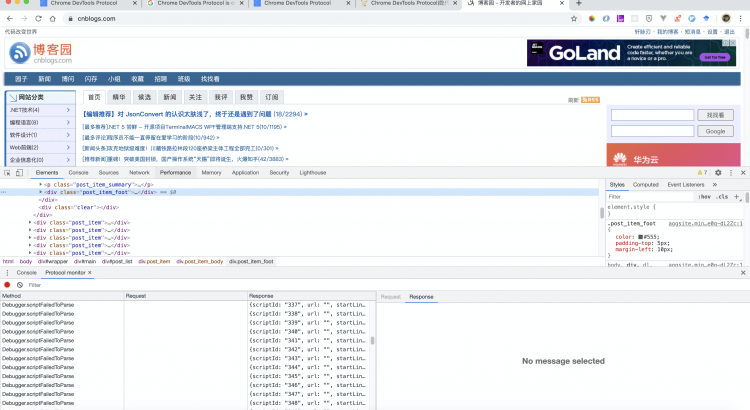
在chrome的開發者工具中
打開實驗選項 Protocol Monitor
重啟chrome,在console的更多裏面就可以打開對應的 Monitor
我們從 Protocol Monitor 面板中可以看到,其中有幾個字樣,Method,Request,Response。
這裏的 Method 就是對應官網 https://chromedevtools.github.io/devtools-protocol/ 左側每個Domain的 Event。
這裏的每個Method方法可能是調試頁面給目標頁面發送的,但是更多是目標頁面給調試頁面發送的消息。所以我們需要讀懂每個Method的內容。不過很可惜,我個人感覺官網的每個Method文檔的描述寫的實在是太簡單了,也沒有看到更詳細的描述,只能通過名字和事件來猜測每個Method意思了。
chromedp的使用最快的方法就是看 https://github.com/chromedp/examples 這個項目
基本我們可以熟悉最常用的幾個方法了:
我們嘗試打開 https://www.cnblogs.com/ 的首頁,然後獲取所有文章的標題和鏈接:
package main
import (
"context"
"fmt"
"log"
"github.com/chromedp/cdproto/cdp"
"github.com/chromedp/chromedp"
)
func main() {
ctx, cancel := chromedp.NewContext(
context.Background(),
chromedp.WithLogf(log.Printf),
)
defer cancel()
var nodes []*cdp.Node
err := chromedp.Run(ctx,
chromedp.Navigate("https://www.cnblogs.com/"),
chromedp.WaitVisible(`#footer`, chromedp.ByID),
chromedp.Nodes(`.//a[@class="titlelnk"]`, &nodes),
)
if err != nil {
log.Fatal(err)
}
fmt.Println("get nodes:", len(nodes))
// print titles
for _, node := range nodes {
fmt.Println(node.Children[0].NodeValue, ":", node.AttributeValue("href"))
}
}
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!

1、首先要在 添加好友 這個按鈕上添加一個事件,也就是在detail.wxml的添加好友這個按鈕的哪裡,添加一個點擊事件 handleAddFriend
並且添加好友還要考慮,現在是已登陸狀態還是未登陸狀態的,只有是登陸狀態的時候,才可以發起添加好友的請求的
所以就要先判斷一下它是否已經登陸了
因為只要是登陸之後,就會把用戶的id寫入到全局的userinfo下面的
handleAddFriend(){ if( app.userInfo._id){ } else{ wx.showToast({ title: '請先登陸', duration : 2000, // 然後不要讓它显示圖標 icon : 'none', success: ()=>{ // 如果成功的話就直接跳轉到我的頁面去 // 但是注意了這裏不能用 navigator to,因為它主要是跳轉 // 普通的頁面,而這裏“我的頁面”其實是同tabbar來進行配置的 } }) } }
這個時候就可以查找一下 小程序文檔 中關於“路由”的介紹了
可以看到要用wx.switchtab來進行操作了
然後因為我們設置了那個提示“請先登陸”是維持兩秒鐘,所以我們也要設置這個跳轉到我的頁面中的時間也是兩秒鐘
handleAddFriend(){ if( app.userInfo._id){ } else{ wx.showToast({ title: '請先登陸', duration : 2000, // 然後不要讓它显示圖標 icon : 'none', success: ()=>{ // 如果成功的話就直接跳轉到我的頁面去 // 但是注意了這裏不能用 navigator to,因為它主要是跳轉 // 普通的頁面,而這裏“我的頁面”其實是同tabbar來進行配置的 setTimeout(()=>{ wx.switchTab({ url: '/pages/user/user', }) } , 2000); } }) } }
上面的加入 沒登陸的情況也寫好了,下面就是對已經登陸了之後的設計了
就要在數據可以中建立一個message集合,主要是用來存儲好友消息,或者是系統的消息給這個用戶的一個信息集合的
這個集合裏面的每一個信息,包含了userID也就是這個好友請求或者是信息是發送給哪一個人的
然後還有一個其他想要加他好友的用戶id list數組,因為每個人都可以給這個人發起好友請求的,這就是對於數據庫1的建立了
所以在已經登陸之後,先查看一下有沒有這個發起好友的信息了,如果還有的話,就在數據庫中創立這個字段了
這個數據庫裏面的userid字段存的其實就是我們要加的這個人的id標識了,然後這個人的id我們可以從這個人的詳情頁面(detail)下的data中來獲得的
通過where就可以定位到在數據庫中這個用戶對應的字段了,然後用get就可以開始對這個字段裏面的東西進行查詢了
如果這個信息已經存在了就做更新操作,如果不存在的話就做創建操作即可了
if( app.userInfo._id){ db.collection('mesasge').where({ userId : this.data.detail._id }).get().then((res)=>{ if( res.data.length){//更新 } else{ //tianjia1 db.collection('message').add({ data : { userId : this.data.detail._id, list : [ app.userInfo._id] } }) } }); }
之後就可以查看數據可以中的message 集合
這樣的話,說明就調用成功了
二、更新message 信息
因為如果已經申請過了的話,就不能再往list裏面添加自己的id了,所以就要檢測一下現在是否在list中,
可以直接調用數組的include方法來進行查詢,如果找到了的話,就提示“已申請過了”如果沒找到的話就要往這個數組裡面進行數據更新了
查看了微信開放文檔之後會發現,如果是單個數據進行更新的話可以直接用doc好到之後進行更新就好了,但是如果對大量的數據進行批量的更新的話
因為在客戶端的更新能力還是有限的,所以就要到服務端上來完成了,也就是用雲函數來完成了(其實這個方法我們已經寫好了,也就是雲函數update了
else{ wx.cloud.callFunction({ // name也就是我們要修改的數據庫的名字,data就是在雲函數中 // 想要的參數了 name : 'updata', data : { collection : 'message', where :{ userId : this.data.detail._id }, data : { } } }) }
注意了,在調用雲函數的時候,前面的data和後面的data是不一樣的,錢買你的是給雲函數的參數,但是後面的是我們要修改的數據了
在要修改list的數據到時候,就涉及了要對數組進行添加,也就是push操作了,其實在數據可以中也內置了一些的方法,commend.push等等
注意:在detail.js文件中,如果找到了這個數據流,但是沒有申請的話,就是進行更新,在更新的時候用到了update雲更新函數,
給這個雲函數傳入的data中
data : `{list : _.unshift(' ${app.userInfo._id} ')}`
注意:最外面那層 並不是 單引號,而是 鍵盤 Esc下面的那個標點
三、添加好友功能之監聽message消息
在數據庫加入了一個 帶有list和userid的數據,所以在userid這個人登陸小程序之後,就應該可以看到有沒有人給他發送消息了
並且還是要實時的更新,就是這個人在登陸狀態的話,也可以直接收到了,也就是要實現實時的監聽數據庫中list的實時變化了
在開發者文檔中:雲開發-》實時數據的推送:
https://developers.weixin.qq.com/miniprogram/dev/wxcloud/guide/database/realtime.html
(它的意思就是我們可以監聽到數據庫發送的變化
可以直接查看demo
const db = wx.cloud.database() const watcher = db.collection('todos') // 按 progress 降序 .orderBy('progress', 'desc') // 取按 orderBy 排序之後的前 10 個 .limit(10) .where({ team: 'our dev team' }) .watch({ onChange: function(snapshot) { console.log('docs\'s changed events', snapshot.docChanges) console.log('query result snapshot after the event', snapshot.docs) console.log('is init data', snapshot.type === 'init') }, onError: function(err) { console.error('the watch closed because of error', err) } }) // ... // 等到需要關閉監聽的時候調用 close() 方法 watcher.close()
我們可以在user頁面中進行檢測即可,也就是在登陸之後進行檢測了
我們創建了一個方法 getMessage()。只要用戶登陸了之後就可以進行觸發了,在onReady裏面的登陸成功代碼之後即可了
也就是在數據庫定位到uuseid是這個用戶的數據之後,得到了之後就可以用watch方法來進行監聽了
getMessage(){ db.collection('message').where({ userId : app.userInfo._id }).watch({ onChange: function (snapshot) { console.log(snapshot); } }); }
這個onChange就是進行監聽的函數了,我們在遇到陌生的一定要傳入參數的函數的時候,最好是把這個參數用console.log打印出來看看我們的想要的數據在哪個位置裏面的
注意了:如果是按照上面這樣的話,是會報錯的,以為缺少了錯誤返回的 onError函數的,示例的demo裏面的格式是怎麼樣的,最好就用怎麼樣的
不然可能都是會報錯的
但是會發現,我們沒拿到有用的數據
就可以用多賬號來調試一下了
(這裏用的多賬號最好還是用真實的賬號把,因為虛擬的出現的問題挺大的)
(然後還要設置給message權限是第一個,允許全部人看的那種,才可以看到在別的賬號上的加好友信息的
在別的賬號上面的話就可以看到打印的信息了,可以看到我們得到的消息其實是挺亂的,所以最好用判斷來搞一下
測試之後會發現,得到的 snapshot 數據中有一個 docChanges 數組的,只要有申請,就會有显示了
所以我們可以通過對數組的長度進行一個判斷
然後再對這個list進行判斷,通過長度來進行判斷,如果有長度的話說明就有消息了
有消息的話就要給用戶一個提示,就是在下面的tabbar中的消息圖標右上角添加一個紅色的小點
===其實這個功能在微信小程序中其實就已經幫我們設計好了
微信文檔-》API-》界面-》tabbar-》wx.showTabBarRedDot
https://developers.weixin.qq.com/miniprogram/dev/api/ui/tab-bar/wx.showTabBarRedDot.html
它需要定義一個index屬性,來指定放紅點的是tabbar中的哪一項的(它是從0開始的,所以我們設置為2即可了)
也就是說這個用戶拿到了這個list之後,通過這個list的長度來判斷有沒有消息,然後設置紅點提示,並且還要把這個得到的list用到消息頁面中去的
所以就涉及到了,怎麼把這個得到的list共享到消息中去,這個和之前的userInfo是類似的,點開全局的app.js
this.userMessage = []
這裏創立的是一個數組來的,不是對象了
然後在user.js裏面,判斷這個得到的list的長度,設置tabbar上面的小紅心,然後把得到的list賦值給全局的userMessage
但是如果檢測到這個list是空的話,就要把在tabbar上面的小紅心取消掉了
**然後還要讓我們全局的userMessage等於一個空的數組即可了
這樣,這個監聽的函數就完成了:
getMessage(){ db.collection('message').where({ userId : app.userInfo._id }).watch({ onChange: function (snapshot) { // console.log(snapshot) if( snapshot.docChanges.length){ //這裏就可以直接拿到message裏面所對應的消息列表了 let list = snapshow.docChanges[0].doc.list; if( list.length ){ wx.showTabBarRedDot({ index: 2, }); app.userMessage = list; } else{ wx.hideTabBarRedDot({ index: 2, }) app.userMessage = []; } } }, onError: function (err) { console.error('the watch closed because of error', err) } }); }
然後因為watch是實時監聽的,我們在數據庫裏面把給的信息刪掉的話
這個紅點也就會消失了
這就是因為正在實時的監聽着
四、下面搞的就是如何把共享的userMessage在消息頁面中渲染出來
===消息頁面和removeList組件布局
首先 切換編譯模式到消息頁面中,先做布局
<view class="message"> <view> <text>暫無消息:</text> </view> <view> <text>消息列表:</text> <view>第一條消息</view> <view>第二條消息</view> </view> </view>
之後就是先判斷有沒有消息。所以就要在js看i嗎添加一個東西,這裏添加的是一個userMessage數組,就是用來接收我們的那個全局的list的,
如果這個數組是空的話,說明就是沒有消息了,反之,所以就可以通過這個來進行判斷了
**之後就要測試一下message這個頁面裏面文件的生命周期了
這就是為了測試,在tabbar中的生命周期是怎麼樣的
在message.js裏面
onReady: function () {
console.log(1)
},
/**
* 生命周期函數--監聽頁面显示
*/
onShow: function () {
console.log(2)
},
在點擊了下main的tabbar的圖標之後,
打印的結果:
但是當我們幾點了個人頁面之後,再點擊消息頁面的時候,只打印了2
也就是說在tabbar裏面的onreay並不會再次的觸發(但是普通頁面的onreay是會被再次觸發的),但是他也是會觸發onshow的
所以基於這個就可以在onshow中添加東西,來監聽現在的消息變化情況了
因為如果想要進入消息頁面的話,就得先登陸,所以這力又要一個判斷了,如果沒登陸得話,就讓他跳轉到登陸頁面去的
(這個功能就和我們的detail裏面很像的,就可以直接COPY過來了)
const app = getApp() Page({ /** * 頁面的初始數據 */ data: { userMessage : [], logged : false }, /** * 生命周期函數--監聽頁面加載 */ onLoad: function (options) { }, /** * 生命周期函數--監聽頁面初次渲染完成 */ onReady: function () { // console.log(1) }, /** * 生命周期函數--監聽頁面显示 */ onShow: function () { // console.log(2) if( app.userInfo._id ){ this.setData({ logged : true, userMessage : app.userMessage }); }else{ wx.showToast({ title: '請先登陸', duration: 2000, // 然後不要讓它显示圖標 icon: 'none', success: () => { // 如果成功的話就直接跳轉到我的頁面去 // 但是注意了這裏不能用 navigator to,因為它主要是跳轉 // 普通的頁面,而這裏“我的頁面”其實是同tabbar來進行配置的 setTimeout(() => { wx.switchTab({ url: '/pages/user/user', }) }, 2000); } }) } }, /** * 生命周期函數--監聽頁面隱藏 */ onHide: function () { }, /** * 生命周期函數--監聽頁面卸載 */ onUnload: function () { }, /** * 頁面相關事件處理函數--監聽用戶下拉動作 */ onPullDownRefresh: function () { }, /** * 頁面上拉觸底事件的處理函數 */ onReachBottom: function () { }, /** * 用戶點擊右上角分享 */ onShareAppMessage: function () { } })
message.js
雖然我們吧list引入進來了,下面就是吧這個list显示出來了
我們用虛擬賬號,給我的主號提交了兩個申請來進行測試了
之後在message.wxml中對我們的信息進行打印:
<!--miniprogram/pages/message/message.wxml--> <view class="message" wx:if="{{ logged }}"> <view wx:if="{{ !userMessage.length }}"> <text class="message-text">暫無消息:</text> </view> <view wx:else> <text class="message-text">消息列表:</text> <view wx:for="{{ userMessage }}" wx:key="{{index}}">{{item}}</view> </view> </view>
我們還要進行優化,就是可以得到一個列表,有頭像有昵稱,等信息的,別還要有刪除的功能的
為了練習一下組件的功能,雖然這個刪除的功能可以直接在這個文件裏面寫,但是我們還是吧這個刪除變成一個組件的形式l
新建一個removeList的刪除組件,然後就是找到message的JSON文件引入這個組件
這個組件其實是可以拖拽的?
在文檔-》組件-》視圖容器 movable-area和movable-view相互配合的
demo:
<movable-area> <movable-view x="{{x}}" y="{{y}}" direction="all">text</movable-view> </movable-area>
我們設置的結構和樣式:
<!--components/removeList/removeList.wxml--> <movable-area class="area"> <movable-view class="view">小喵喵</movable-view> </movable-area>
/* components/removeList/removeList.wxss */ .area{width:800rpx; height: 150rpx; margin: 20rpx ; position: relative;background: blue;} .view{width:630rpx; height:100%; background: red;position: absolute;left:150rpx;top:0; line-height: 150rpx;text-indent: 10rpx;}
效果;
但是這個時候還是不能進行拖拽的,其中的direction定義的就是拖拽的方向
添加了這個屬性之後:
<!--components/removeList/removeList.wxml--> <movable-area class="area"> <movable-view direction="horizontal" class="view">小喵喵</movable-view> </movable-area>
就可以進行拖拽了
注意;下面設置的z-Index是在設置級別,z-index大的會覆蓋在小的上面的
<!--components/removeList/removeList.wxml--> <movable-area class="area"> <movable-view direction="horizontal" class="view">小喵喵</movable-view> <image src="" /> <view class="delete">刪除</view> </movable-area>
/* components/removeList/removeList.wxss */ .area{width:800rpx; height: 150rpx; margin: 20rpx ; position: relative;border-bottom: 1px #cdcdcd dashed} .view{width:630rpx; height:100%; position: absolute;left:150rpx;top:0; line-height: 150rpx;text-indent: 10rpx;z-index: 2;} image{ width: 100rpx; height: 100rpx; border-radius: 50%; position: absolute; left: 0; top: 0; z-index: 1; } .delete{ width: 200rpx; height: 150rpx; background: red; color: white; position: absolute; right: 0; top: 0; z-index: 1; }
但是得到的效果是:
會發現不管怎麼拖拉,都擋不住後面的刪除–原因就是class==view這塊沒加背景色,雖然層級夠了
給他在wxss裏面添加一個 background:white即可了
刪除那個文字要居中的話,
.delete{ width: 170rpx; height: 100rpx; background: red; color: white; position: absolute; right: 0; top: 0; z-index: 1; line-height: 100rpx; }
效果圖:
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※自行創業缺乏曝光? 網頁設計幫您第一時間規劃公司的形象門面
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※想知道最厲害的網頁設計公司"嚨底家"!
※幫你省時又省力,新北清潔一流服務好口碑
※別再煩惱如何寫文案,掌握八大原則!
這個官方文檔一段對MySQL內核分析的一個嚮導。是對MySQL一條insert語句寫入到MySQL數據庫的分析。
但是,對於MySQL 5.7版本來說,基本上都是寫入到innodb引擎。但也還是有借鑒意義,大的框架沒有太大變化。
後面的文檔,會通過mysqld –debug 和gdb等工具,通過分析mysqld.trace來分析insert語句在MySQL 5.7中怎麼寫入數據庫。
官方文檔給出的一段結構,如下:
/sql/mysqld.cc
/sql/sql_parse.cc
/sql/sql_prepare.cc
/sql/sql_insert.cc
/sql/ha_myisam.cc
/myisam/mi_write.c
上述梳理一個過程,是說從客戶段執行一條簡單的insert語句,然後到達MySQL服務器端,並通過MyISAM存儲層。寫入到MyISAM文件的過程。
由於,我們現在的主流都是InnoDB存儲引擎,所以我們分析的寫入到存儲層應該是InnoDB的源代碼。但是上述的一個框架也有借鑒意義。雖然,走的是InnoDB存儲引擎插入數據,但是也還是需要通過SQL層的ha_*這樣的接口進行接入。
正題開始!!!!!!!!!!!!!!!!!!!!!!!
第一步,進入MySQL大門的地方。夢開始的地方。眾所周知,C語言都是需要main方法作為主入口。而MySQL的主入口如下:
代碼位置 /sql/mysqld.cc
int main(int argc, char **argv)
{
_cust_check_startup();
(void) thr_setconcurrency(concurrency);
init_ssl();
server_init(); // 'bind' + 'listen'
init_server_components();
start_signal_handler();
acl_init((THD *)0, opt_noacl);
init_slave();
create_shutdown_thread();
create_maintenance_thread();
handle_connections_sockets(0); // ! 這裏也代表着我們進入下一個門的地方
DBUG_PRINT("quit",("Exiting main thread"));
exit(0);
}
這裏可以看到很多的init_*或者server_init()。通過名字我們可以猜測出,這裏做了很多初始化的工作。例如:啟動過程中一些初始化的檢查和MySQL配置變量的加載和一些組件的初始化等。
這裏重要的函數是handle_connections_sockets
繼續跟蹤 /sql/mysqld.cc
handle_connections_sockets (arg __attribute__((unused))
{
if (ip_sock != INVALID_SOCKET)
{
FD_SET(ip_sock,&clientFDs);
DBUG_PRINT("general",("Waiting for connections."));
while (!abort_loop)
{
new_sock = accept(sock, my_reinterpret_cast(struct sockaddr*)
(&cAddr), &length);
thd= new THD;
if (sock == unix_sock)
thd->host=(char*) localhost;
create_new_thread(thd); // !
}
從簡易的思維,忽視其他的判斷語句。可以看到這裏做的是典型的client/server架構。服務器有一個主線程,它總是偵聽來自新客戶機的請求。一旦它接收到這樣的請求,它將分配資源。特別是,主線程將生成一個新線程來處理連接。然後主服務器將循環並偵聽新連接——但我們將保留它並跟蹤新線程。
這裏創建新線程的方法是:create_new_thread(thd);
繼續跟蹤 /sql/mysqld.cc
create_new_thread(THD *thd)
{
pthread_mutex_lock(&LOCK_thread_count);
pthread_create(&thd->real_id,&connection_attrib,
handle_one_connection, // !
(void*) thd));
pthread_mutex_unlock(&LOCK_thread_count);
}
可以看到這裏獲得一個新線程加入一個互斥鎖,避免衝突。
繼續跟蹤 /sql/mysqld.cc
handle_one_connection(THD *thd)
{
init_sql_alloc(&thd->mem_root, MEM_ROOT_BLOCK_SIZE, MEM_ROOT_PREALLOC);
while (!net->error && net->vio != 0 && !thd->killed)
{
if (do_command(thd)) // !
break;
}
close_connection(net);
end_thread(thd,1);
packet=(char*) net->read_pos;
從這裏開始,我們即將脫離mysqld.cc文件,因為我們獲得了thread,且分配一小段內存資源,給與我們來處理我們的SQL語句了。
我們會走向何方呢,可以開始觀察do_command(thd)方法。
繼續跟蹤/sql/sql_parse.cc
bool do_command(THD *thd)
{
net_new_transaction(net);
packet_length=my_net_read(net);
packet=(char*) net->read_pos;
command = (enum enum_server_command) (uchar) packet[0];
dispatch_command(command,thd, packet+1, (uint) packet_length);
// !
}
其中從這裏可以看到,do_command(THD *thd)把它串聯起來的是一個叫作THD的東西,也就是thread。所以後面的工作和行為,基本都是通過thread進行牽線搭橋的。
my_net_read函數位於另一個名為net_servlet .cc的文件中。該函數從客戶端獲取一個包,解壓縮它,並去除頭部。
一旦完成,我們就得到了一個名為packet的多字節變量,它包含客戶端發送的內容。第一個字節很重要,因為它包含標識消息類型的代碼。
說明了packet第一個字節很重要。debug也有證據進行一個佐證。
packet_header: Memory: 0x7f7fc000a4b0 Bytes: (4)
21 00 00 00
然後把packet第一個字節和餘下的部分傳遞給dispatch_command
繼續跟蹤/sql/sql_parse.cc
bool dispatch_command(enum enum_server_command command, THD *thd,
char* packet, uint packet_length)
{
switch (command) {
case COM_INIT_DB: ...
case COM_REGISTER_SLAVE: ...
case COM_TABLE_DUMP: ...
case COM_CHANGE_USER: ...
case COM_EXECUTE:
mysql_stmt_execute(thd,packet);
case COM_LONG_DATA: ...
case COM_PREPARE:
mysql_stmt_prepare(thd, packet, packet_length); // !
/* and so on for 18 other cases */
default:
send_error(thd, ER_UNKNOWN_COM_ERROR);
break;
}
這裏sql_parser .cc中有一個非常大的switch語句
switch語句中代碼有:code for prepare, close statement, query, quit, create database, drop database, dump binary log, refresh, statistics, get process info, kill process, sleep, connect, and several minor commands
除了COM_EXECUTE和COM_PREPARE兩種情況外,我們刪除了所有情況下的代碼細節。
可以看到
COM_EXECUTE 會調用mysql_stmt_execute(thd,packet);
COM_PREPARE 會調用mysql_stmt_prepare(thd, packet, packet_length);
這裏就像一个中轉站一般,看我們去向什麼地方。這裏去的門是:COM_PREPARE:mysql_stmt_prepare
跟蹤 /sql/sql_prepare.cc
下面是一段prepare的註釋
"Prepare:
Parse the query
Allocate a new statement, keep it in 'thd->prepared statements' pool
Return to client the total number of parameters and result-set
metadata information (if any)"
繼續回到主線COM_EXECUTE
跟蹤/sql/sql_parse.cc
bool dispatch_command(enum enum_server_command command, THD *thd,
char* packet, uint packet_length)
{
switch (command) {
case COM_INIT_DB: ...
case COM_REGISTER_SLAVE: ...
case COM_TABLE_DUMP: ...
case COM_CHANGE_USER: ...
case COM_EXECUTE:
mysql_stmt_execute(thd,packet); // !
case COM_LONG_DATA: ...
case COM_PREPARE:
mysql_stmt_prepare(thd, packet, packet_length);
/* and so on for 18 other cases */
default:
send_error(thd, ER_UNKNOWN_COM_ERROR);
break;
}
現在“COM_EXECUTE 中的mysql_stmt_execute`是我們關注的重點,我們來看看
跟蹤/sql/sql_prepare.cc代碼
void mysql_stmt_execute(THD *thd, char *packet)
{
if (!(stmt=find_prepared_statement(thd, stmt_id, "execute")))
{
send_error(thd);
DBUG_VOID_RETURN;
}
init_stmt_execute(stmt);
mysql_execute_command(thd); // !
}
這裏做一個判斷,看是否是execute,然後初始化語句,並開始執行mysql_execute_command(thd);可以看到,是通過thread來調用動作。
跟蹤/sql/sql_parse.cc代碼
void mysql_execute_command(THD *thd)
switch (lex->sql_command) {
case SQLCOM_SELECT: ...
case SQLCOM_SHOW_ERRORS: ...
case SQLCOM_CREATE_TABLE: ...
case SQLCOM_UPDATE: ...
case SQLCOM_INSERT: ... // !
case SQLCOM_DELETE: ...
case SQLCOM_DROP_TABLE: ...
}
lex 解析sql語句。然後進入SQLCOM_INSERT。
跟蹤/sql/sql_parse.cc代碼
case SQLCOM_INSERT:
{
my_bool update=(lex->value_list.elements ? UPDATE_ACL : 0);
ulong privilege= (lex->duplicates == DUP_REPLACE ?
INSERT_ACL | DELETE_ACL : INSERT_ACL | update);
if (check_access(thd,privilege,tables->db,&tables->grant.privilege))
goto error;
if (grant_option && check_grant(thd,privilege,tables))
goto error;
if (select_lex->item_list.elements != lex->value_list.elements)
{
send_error(thd,ER_WRONG_VALUE_COUNT);
DBUG_VOID_RETURN;
}
res = mysql_insert(thd,tables,lex->field_list,lex->many_values,
select_lex->item_list, lex->value_list,
(update ? DUP_UPDATE : lex->duplicates));
// !
if (thd->net.report_error)
res= -1;
break;
}
對於插入數據,我們要做的第一件事情是:檢查用戶是否具有對錶進行插入的適當特權,服務器通過調用check_access和check_grant函數在這裏進行檢查。
有了權限才可以做【插入】動作。
我們可以導航 /sql 目錄,如下:
Program Name SQL statement type
------------ ------------------
sql_delete.cc DELETE
sql_do.cc DO
sql_handler.cc HANDLER
sql_help.cc HELP
sql_insert.cc INSERT // !
sql_load.cc LOAD
sql_rename.cc RENAME
sql_select.cc SELECT
sql_show.cc SHOW
sql_update.cc UPDATE
sql_insert.cc是具體執行插入的操作。
上面的mysql_insert() 的方法具體實現,在sql_insert.cc文件中。
跟蹤 /sql/sql_insert.cc代碼
int mysql_insert(THD *thd,TABLE_LIST *table_list, List<Item> &fields,
List<List_item> &values_list,enum_duplicates duplic)
{
table = open_ltable(thd,table_list,lock_type);
if (check_insert_fields(thd,table,fields,*values,1) ||
setup_tables(table_list) ||
setup_fields(thd,table_list,*values,0,0,0))
goto abort;
fill_record(table->field,*values);
error=write_record(table,&info); // !
query_cache_invalidate3(thd, table_list, 1);
if (transactional_table)
error=ha_autocommit_or_rollback(thd,error);
query_cache_invalidate3(thd, table_list, 1);
mysql_unlock_tables(thd, thd->lock);
}
這裏就要開始,打開一張表。然後各種檢查,看插入表的字段是否有問題。不行就abort。
然後,開始填充記錄數據。最終調用write_record 寫記錄的方法。
由於write_record 會對應不同的存儲引擎,所以這裡有分支的。我這裏講解兩種
繼續跟蹤/sql/sql_insert.cc
int write_record(TABLE *table,COPY_INFO *info)
{
table->file->write_row(table->record[0]; // !
}
終於,要寫文件了。調用那個存儲引擎呢?看handler.h
/* The handler for a table type.
Will be included in the TABLE structure */
handler(TABLE *table_arg) :
table(table_arg),active_index(MAX_REF_PARTS),
ref(0),ref_length(sizeof(my_off_t)),
block_size(0),records(0),deleted(0),
data_file_length(0), max_data_file_length(0),
index_file_length(0),
delete_length(0), auto_increment_value(0), raid_type(0),
key_used_on_scan(MAX_KEY),
create_time(0), check_time(0), update_time(0), mean_rec_length(0),
ft_handler(0)
{}
...
virtual int write_row(byte * buf)=0;
官方文檔默認調用的是 ha_myisam::write_row
代碼 /sql/ha_myisam.cc
如下:
int ha_myisam::write_row(byte * buf)
{
statistic_increment(ha_write_count,&LOCK_status);
/* If we have a timestamp column, update it to the current time */
if (table->time_stamp)
update_timestamp(buf+table->time_stamp-1);
/*
If we have an auto_increment column and we are writing a changed row
or a new row, then update the auto_increment value in the record.
*/
if (table->next_number_field && buf == table->record[0])
update_auto_increment();
return mi_write(file,buf); // !
}
這些以字母ha開頭的程序是處理程序的接口,而這個程序是myisam處理程序的接口。我們這裏就開始調用MyISAM了。
可以看到這裏調用了mi_write(file,buf);
跟蹤/myisam/mi_write.c
int mi_write(MI_INFO *info, byte *record)
{
_mi_readinfo(info,F_WRLCK,1);
_mi_mark_file_changed(info);
/* Calculate and check all unique constraints */
for (i=0 ; i < share->state.header.uniques ; i++)
{
mi_check_unique(info,share->uniqueinfo+i,record,
mi_unique_hash(share->uniqueinfo+i,record),
HA_OFFSET_ERROR);
}
... to be continued in next snippet
這裡有很多唯一性的校驗,繼續看下面
... continued from previous snippet
/* Write all keys to indextree */
for (i=0 ; i < share->base.keys ; i++)
{
share->keyinfo[i].ck_insert(info,i,buff,
_mi_make_key(info,i,buff,record,filepos)
}
(*share->write_record)(info,record);
if (share->base.auto_key)
update_auto_increment(info,record);
}
這裏就是我們寫入到文件的地方。至此,MySQL的插入操作結束。
路徑為:
main in /sql/mysqld.cc
handle_connections_sockets in /sql/mysqld.cc
create_new_thread in /sql/mysqld.cc
handle_one_connection in /sql/sql_parse.cc
do_command in /sql/sql_parse.cc
dispatch_command in /sql/sql_parse.cc
mysql_stmt_execute in /sql/sql_prepare.cc
mysql_execute_command in /sql/sql_parse.cc
mysql_insert in /sql/mysql_insert.cc
write_record in /sql/mysql_insert.cc
ha_myisam::write_row in /sql/ha_myisam.cc
mi_write in /myisam/mi_write.c
1.進入主函數入口
2.建立socket connection的請求
3.創建一個新的線程
4.處理線程,分配內存資源
5.do_command,是獲取packet第一字節,看做什麼操作,並接受餘下字節。
6.dispatch_command,分發操作,這裏分發的是insert。
7.mysql_stmt_execute,檢查是否為execute,初始化,準備做execute動作。
8.mysql_execute_command ,lex解析SQL語句,進入到SQLCOM_INSERT
9.mysql_insert ,開始做插入操作。調用write_record
10.write_record,準備寫入,看調用哪個存儲引擎,寫入前期準備工作
11.ha_myisam::write_row,ha_myisam進行插入寫入。
12.mi_write,最後做寫入操作。
文獻參考:https://dev.mysql.com/doc/internals/en/guided-tour-skeleton.html
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※新北清潔公司,居家、辦公、裝潢細清專業服務
※別再煩惱如何寫文案,掌握八大原則!
※教你寫出一流的銷售文案?
※超省錢租車方案

上篇文章我們演示了為Configuration添加Etcd數據源,並且了解到為Configuration擴展自定義數據源還是非常簡單的,核心就是把數據源的數據按照一定的規則讀取到指定的字典里,這些都得益於微軟設計的合理性和便捷性。本篇文章我們將一起探究Configuration源碼,去了解Configuration到底是如何工作的。
相信使用了.Net Core或者看過.Net Core源碼的同學都非常清楚,.Net Core使用了大量的Builder模式許多核心操作都是是用來了Builder模式,微軟在.Net Core使用了許多在傳統.Net框架上並未使用的設計模式,這也使得.Net Core使用更方便,代碼更合理。Configuration作為.Net Core的核心功能當然也不例外。
其實並沒有Configuration這個類,這隻是我們對配置模塊的代名詞。其核心是IConfiguration接口,IConfiguration又是由IConfigurationBuilder構建出來的,我們找到IConfigurationBuilder源碼大致定義如下
public interface IConfigurationBuilder
{
IDictionary<string, object> Properties { get; }
IList<IConfigurationSource> Sources { get; }
IConfigurationBuilder Add(IConfigurationSource source);
IConfigurationRoot Build();
}
Add方法我們上篇文章曾使用過,就是為ConfigurationBuilder添加ConfigurationSource數據源,添加的數據源被存放在Sources這個屬性里。當我們要使用IConfiguration的時候通過Build的方法得到IConfiguration實例,IConfigurationRoot接口是繼承自IConfiguration接口的,待會我們會探究這個接口。
我們找到IConfigurationBuilder的默認實現類ConfigurationBuilder大致代碼實現如下
public class ConfigurationBuilder : IConfigurationBuilder
{
/// <summary>
/// 添加的數據源被存放到了這裏
/// </summary>
public IList<IConfigurationSource> Sources { get; } = new List<IConfigurationSource>();
public IDictionary<string, object> Properties { get; } = new Dictionary<string, object>();
/// <summary>
/// 添加IConfigurationSource數據源
/// </summary>
/// <returns></returns>
public IConfigurationBuilder Add(IConfigurationSource source)
{
if (source == null)
{
throw new ArgumentNullException(nameof(source));
}
Sources.Add(source);
return this;
}
public IConfigurationRoot Build()
{
//獲取所有添加的IConfigurationSource里的IConfigurationProvider
var providers = new List<IConfigurationProvider>();
foreach (var source in Sources)
{
var provider = source.Build(this);
providers.Add(provider);
}
//用providers去實例化ConfigurationRoot
return new ConfigurationRoot(providers);
}
}
這個類的定義非常的簡單,相信大家都能看明白。其實整個IConfigurationBuilder的工作流程都非常簡單就是將IConfigurationSource添加到Sources中,然後通過Sources里的Provider去構建IConfigurationRoot。
通過上面我們了解到通過ConfigurationBuilder構建出來的並非是直接實現IConfiguration的實現類而是另一個接口IConfigurationRoot
通過源代碼我們可以知道IConfigurationRoot是繼承自IConfiguration,具體定義關係如下
public interface IConfigurationRoot : IConfiguration
{
/// <summary>
/// 強制刷新數據
/// </summary>
/// <returns></returns>
void Reload();
IEnumerable<IConfigurationProvider> Providers { get; }
}
public interface IConfiguration
{
string this[string key] { get; set; }
/// <summary>
/// 獲取指定名稱子數據節點
/// </summary>
/// <returns></returns>
IConfigurationSection GetSection(string key);
/// <summary>
/// 獲取所有子數據節點
/// </summary>
/// <returns></returns>
IEnumerable<IConfigurationSection> GetChildren();
/// <summary>
/// 獲取IChangeToken用於當數據源有數據變化時,通知外部使用者
/// </summary>
/// <returns></returns>
IChangeToken GetReloadToken();
}
接下來我們查看IConfigurationRoot實現類ConfigurationRoot的大致實現,代碼有刪減
public class ConfigurationRoot : IConfigurationRoot, IDisposable
{
private readonly IList<IIConfigurationProvider> _providers;
private readonly IList<IDisposable> _changeTokenRegistrations;
private ConfigurationReloadToken _changeToken = new ConfigurationReloadToken();
public ConfigurationRoot(IList<IConfigurationProvider> providers)
{
_providers = providers;
_changeTokenRegistrations = new List<IDisposable>(providers.Count);
//通過便利的方式調用ConfigurationProvider的Load方法,將數據加載到每個ConfigurationProvider的字典里
foreach (var p in providers)
{
p.Load();
//監聽每個ConfigurationProvider的ReloadToken實現如果數據源發生變化去刷新Token通知外部發生變化
_changeTokenRegistrations.Add(ChangeToken.OnChange(() => p.GetReloadToken(), () => RaiseChanged()));
}
}
//// <summary>
/// 讀取或設置配置相關信息
/// </summary>
public string this[string key]
{
get
{
//通過這個我們可以了解到讀取的順序取決於註冊Source的順序,採用的是後來者居上的方式
//后註冊的會先被讀取到,如果讀取到直接return
for (var i = _providers.Count - 1; i >= 0; i--)
{
var provider = _providers[i];
if (provider.TryGet(key, out var value))
{
return value;
}
}
return null;
}
set
{
//這裏的設置只是把值放到內存中去,並不會持久化到相關數據源
foreach (var provider in _providers)
{
provider.Set(key, value);
}
}
}
public IEnumerable<IConfigurationSection> GetChildren() => this.GetChildrenImplementation(null);
public IChangeToken GetReloadToken() => _changeToken;
public IConfigurationSection GetSection(string key)
=> new ConfigurationSection(this, key);
//// <summary>
/// 手動調用該方法也可以實現強制刷新的效果
/// </summary>
public void Reload()
{
foreach (var provider in _providers)
{
provider.Load();
}
RaiseChanged();
}
//// <summary>
/// 強烈推薦不熟悉Interlocked的同學研究一下Interlocked具體用法
/// </summary>
private void RaiseChanged()
{
var previousToken = Interlocked.Exchange(ref _changeToken, new ConfigurationReloadToken());
previousToken.OnReload();
}
}
上面展示了ConfigurationRoot的核心實現其實主要就是兩點
其實通過上面的代碼我們會產生一個疑問,獲取子節點數據返回的是另一個接口類型IConfigurationSection,我們來看下具體的定義
public interface IConfigurationSection : IConfiguration
{
string Key { get; }
string Path { get; }
string Value { get; set; }
}
這個接口也是繼承了IConfiguration,這就奇怪了分明只有一套配置IConfiguration,為什麼還要區分IConfigurationRoot和IConfigurationSection呢?其實不難理解因為Configuration可以同時承載許多不同的配置源,而IConfigurationRoot正是表示承載所有配置信息的根節點,而配置又是可以表示層級化的一種結構,在根配置里獲取下來的子節點是可以表示承載一套相關配置的另一套系統,所以單獨使用IConfigurationSection去表示,會顯得結構更清晰,比如我們有如下的json數據格式
{
"OrderId":"202005202220",
"Address":"銀河系太陽系火星",
"Total":666.66,
"Products":[
{
"Id":1,
"Name":"果子狸",
"Price":66.6,
"Detail":{
"Color":"棕色",
"Weight":"1000g"
}
},
{
"Id":2,
"Name":"蝙蝠",
"Price":55.5,
"Detail":{
"Color":"黑色",
"Weight":"200g"
}
}
]
}
我們知道json是一個結構化的存儲結構,其存儲元素分為三種一是簡單類型,二是對象類型,三是集合類型。但是字典是KV結構,並不存在結構化關係,在.Net Corez中配置系統是這麼解決的,比如以上信息存儲到字典中的結構就是這種
| Key | Value |
| OrderId | 202005202220 |
| Address | 銀河系太陽系火星 |
| Products:0:Id | 1 |
| Products:0:Name | 果子狸 |
| Products:0:Detail:Color | 棕色 |
| Products:1:Id | 2 |
| Products:1:Name | 蝙蝠 |
| Products:1:Detail:Weight | 200g |
如果我想獲取Products節點下的第一條商品數據直接
IConfigurationSection productSection = configuration.GetSection("Products:0")
類比到這裏的話根配置IConfigurationRoot里存儲了訂單的所有數據,獲取下來的子節點IConfigurationSection表示了訂單里第一個商品的信息,而這個商品也是一個完整的描述商品信息的數據系統,所以這樣可以更清晰的區分Configuration的結構,我們來看一下ConfigurationSection的大致實現
public class ConfigurationSection : IConfigurationSection
{
private readonly IConfigurationRoot _root;
private readonly string _path;
private string _key;
public ConfigurationSection(IConfigurationRoot root, string path)
{
_root = root;
_path = path;
}
public string Path => _path;
public string Key
{
get
{
return _key;
}
}
public string Value
{
get
{
return _root[Path];
}
set
{
_root[Path] = value;
}
}
public string this[string key]
{
get
{
//獲取當前Section下的數據其實就是組合了Path和Key
return _root[ConfigurationPath.Combine(Path, key)];
}
set
{
_root[ConfigurationPath.Combine(Path, key)] = value;
}
}
//獲取當前節點下的某個子節點也是組合當前的Path和子節點的標識Key
public IConfigurationSection GetSection(string key) => _root.GetSection(ConfigurationPath.Combine(Path, key));
//獲取當前節點下的所有子節點其實就是在字典里獲取包含當前Path字符串的所有Key
public IEnumerable<IConfigurationSection> GetChildren() => _root.GetChildrenImplementation(Path);
public IChangeToken GetReloadToken() => _root.GetReloadToken();
}
這裏我們可以看到既然有Key可以獲取字典里對應的Value了,為何還需要Path?通過ConfigurationRoot里的代碼我們可以知道Path的初始值其實就是獲取ConfigurationSection的Key,說白了其實就是如何獲取到當前IConfigurationSection的路徑。比如
//當前productSection的Path是 Products:0
IConfigurationSection productSection = configuration.GetSection("Products:0");
//當前productDetailSection的Path是 Products:0:Detail
IConfigurationSection productDetailSection = productSection.GetSection("Detail");
//獲取到pColor的全路徑就是 Products:0:Detail:Color
string pColor = productDetailSection["Color"];
而獲取Section所有子節點
GetChildrenImplementation來自於IConfigurationRoot的擴展方法
internal static class InternalConfigurationRootExtensions
{
//// <summary>
/// 其實就是在數據源字典里獲取Key包含給定Path的所有值
/// </summary>
internal static IEnumerable<IConfigurationSection> GetChildrenImplementation(this IConfigurationRoot root, string path)
{
return root.Providers
.Aggregate(Enumerable.Empty<string>(),
(seed, source) => source.GetChildKeys(seed, path))
.Distinct(StringComparer.OrdinalIgnoreCase)
.Select(key => root.GetSection(path == null ? key : ConfigurationPath.Combine(path, key)));
}
}
相信講到這裏,大家對ConfigurationSection或者是對Configuration整體的思路有一定的了解,細節上的設計確實不少。但是整體實現思路還是比較清晰的。關於Configuration還有一個比較重要的擴展方法就是將配置綁定到具體POCO的擴展方法,該方法承載在ConfigurationBinder擴展類了,由於實現比較複雜,也不是本篇文章的重點,有興趣的同學可以自行查閱,這裏就不做探究了。
通過以上部分的講解,其實我們可以大概的將Configuration配置相關總結為兩大核心抽象接口IConfigurationBuilder,IConfiguration,整體結構關係可大致表示成如下關係
配置相關的整體實現思路就是IConfigurationSource作為一種特定類型的數據源,它提供了提供當前數據源的提供者ConfigurationProvider,Provider負責將數據源的數據按照一定的規則放入到字典里。IConfigurationSource添加到IConfigurationBuilder的容器中,後者使用Provide構建出整個程序的根配置容器IConfigurationRoot。通過獲取IConfigurationRoot子節點得到IConfigurationSection負責維護子節點容器相關。這二者都繼承自IConfiguration,然後通過他們就可以獲取到整個配置體系的數據數據操作了。
以上講解都是本人通過實踐和閱讀源碼得出的結論,可能會存在一定的偏差或理解上的誤區,但是我還是想把我的理解分享給大家,希望大家能多多包涵。如果有大家有不同的見解或者更深的理解,可以在評論區多多留言。
歡迎掃碼關注我的公眾號 本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※新北清潔公司,居家、辦公、裝潢細清專業服務
※別再煩惱如何寫文案,掌握八大原則!
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※超省錢租車方案
※教你寫出一流的銷售文案?

摘要
本文通過列舉歷史中出現的產品,梳理了模數轉換器在20世紀30年代~~20世紀80年代末的發展歷史。接下來,簡要介紹模數轉換器的原理、技術指標、分類和未來發展方向。最後,提供了一種自製3位FLASH型ADC的方法(該方法經過了作者的測試且價格在20元以下)。
參考文獻
涉及到的數據手冊(eyg7)
Flash ADC_Chapter 13 – Digital-Analog Conversion
ZepToBars
《Analog-Digital Conversion》 Chapter I Walt Kester
《数字电子技術》第六版 康華光
数字电子技術 西南石油大學課程中心
ADC的歷史
世界上記載的第一個”純电子“的A/D轉換器於1939年被亞歷克·哈利·里夫斯(Alec Harley Reeves)發明,該設計的採樣率為6KSPS,分辨率為5位。
亞歷克·哈利·里夫斯設計的A/D轉換器原理圖,《Analog-Digital Conversion》 Chapter I Walt Kester
1947年,鍺晶體管於貝爾實驗室誕生。
1946年,ENIAC問世,現代数字計算機的鼻祖,為A/D的蓬勃發展做鋪墊。
1948年,貝爾實驗室發明了5位、8KSPS的逐次逼近型A/D轉換器。
得力於电子束編碼管技術,在1960年左右出現了12MSPS、9位的編碼器(A/D)。
电子束編碼管原理圖,《Analog-Digital Conversion》 Chapter I Walt Kester
1954年,硅晶體管於德州儀器誕生。
1954年,伯納德·M·戈登(Bernard M. Gordon)發明了11位、50KSPS的基於真空管的A/D,這被認為是世界上第一個商業化的A/D轉換器。“Datrac”功率500W,售價8000~~9000美元。
伯納德·M·戈登發明的 “Datrac”,《Analog-Digital Conversion》 Chapter I Walt Kester
1958/1959,集成電路問世,德州儀器(1958),仙童半導體(1959)。
1963~1965年,為了給美國軍方的雷達提供高速A/D,貝爾實驗室的John M. Eubanks和Robert C. Bedingfield研發了8位、10MSPS的A/D,其功率為150W、售價10000美元。
John M. Eubanks和Robert C. Bedingfield研發的A/D,《Analog-Digital Conversion》 Chapter I Walt Kester
1969年,Pastoriza公司利用分立元件製造了12位、10us、2.3W的逐次逼近型A/D樣機—-“ADC-12U”,售價800美元。
“ADC-12U”原型機,《Analog-Digital Conversion》 Chapter I Walt Kester
1978年,Paul Brokaw設計了第一個完整的單芯片ADC,型號為AD571,使用了雙極型工藝,參數為:10位、25us、SAR結構。同年,誕生了最具重要意義的SAR ADC–AD574。這時的A/D可以說開始走向現代。
AD571,源
AD571框圖,《Analog-Digital Conversion》 Chapter I Walt Kester
1988年,Crystal Semiconductor推出了世界上第一個單芯片商業化的ε-Δ ADC–CSZ5316,參數:16位、20KSPS,可以用於語音處理。
接下來的歷史中,各廠商不斷改進ADC的性能、推出更多不同用途的ADC。總而言之,就是讓ADC進入千家萬戶。
ADC的原理
ADC(Analog to Digital Converter)是一類將模擬信號(連續信號)轉換為数字信號(離散信號)的器件,按原理可分為:并行比較型A/D轉換器(FLASH ADC)、逐次比較型A/D轉換器(SAR ADC)和雙積分式A/D轉換器(Double Integral ADC)。
模擬信號,下圖中的ui(t)是一個輸入的模擬電壓信號,可以想象成從一個麥克風輸出的音頻信號。
数字信號,現代計算機能夠處理的信號,表現為下圖中的“n位数字量輸出”。
香農-奈奎斯特(Shannon & Nyquist)採樣定理規定,使恢復出的信號不失真的條件:採樣頻率大於原始信號頻率的兩倍,即 Fs >= 2Fi
一個連續的電壓信號ui(t)通過一個由方波CPs控制的開關S之後施加到電容C上,由於電容兩端的電壓不會突變,可知在S斷開時C將維持ui(t)在開關斷開瞬間的電壓一段時間,直到開關S再次打開。這樣,一個模擬的電壓信號就轉換成了採樣展寬信號us(t),其中CPs的頻率就是採樣頻率Fs。然後,由ADC的数字編碼電路將採樣展寬信號us(t)轉換成n位的数字量dn-1 : d0並輸出。
通過上述步驟,一個連續的電壓信號就轉換成了n位的数字量,而實現該過程的器件叫做模擬-数字轉換器(ADC)。
AD轉換的一般原理,”数字电子技術” SWPU
TLC5540I,8位、40MSPS、CMOS工藝的并行比較型A/D轉換器的版圖,https://zeptobars.com/,license: CC BY 3.0,未修改
ADC的主要性能指標
分辨率:ADC能分辨的最小電壓,通常用位數表示,例如:8位。一個n=8位的ADC,參考電壓為5V,則其能分辨的最小電壓為 5 / 2^n = 19.53mV
轉換時間:ADC從控制信號到來開始,到輸出端得到穩定的数字信號所經歷的時間。
轉換精度:ADC輸出的数字量所表示的模擬值與實際輸入的模擬量之間的偏差。
ADC的分類
并行比較型A/D轉換器:這是本文嘗試構建的ADC,其由電阻分壓器、電壓比較器(運算放大器)、D觸發器和優先級編碼器構成。其原理簡單,將在後文介紹。
優點:1.轉換時間最短,其轉換周期為通過比較器、觸發器和優先級編碼器的時間總和(見下式),這個數值通常很小。
T轉 = T比 + T寄 + T編
缺點:1.造價高昂,隨着分辨位數的提高,所需的元件幾乎按幾何級數增長,如:一個n位的并行比較型ADC,需要2^n – 1個比較器和2^n – 1個觸發器,假如n=12,那麼一共需要8190個比較器和觸發器!
2.對集成電路的工藝要求很高。
常見的型號:AD9012,TTL工藝,分辨率為8位,採樣率為100MSPS,模擬輸入電壓範圍 -Vs~~+0.5V(Vs為芯片供電電壓)。
AD9002,ECL工藝(射極耦合邏輯),分辨率為8位,採樣率為150MSPS,模擬輸入電壓範圍 -Vs~~+0.5V(Vs為芯片供電電壓)。
AD9020,TTL工藝,分辨率為10位,採樣率為60MSPS,雙極性模擬輸入(+-1.75V)。
3位并行比較型A/D轉換器原理圖,《数字电子技術》第六版 康華光
AD9012原理圖,Analog Devices
AD9002原理圖,Analog Devices
AD9020原理圖,Analog Devices
1107PV2,蘇聯,8位、20MSPS,典型的并行比較型A/D轉換器的版圖,https://zeptobars.com/,license: CC BY 3.0,未修改
1107PV2,蘇聯,8位、20MSPS,典型的并行比較型A/D轉換器的比較器的版圖,https://zeptobars.com/,license: CC BY 3.0,未修改
逐次比較型A/D轉換器:原理像天平,對輸入的模擬電壓信號與不同權值的電壓做多次比較,使得轉換所得的数字量在數值上不斷逼近輸入的模擬量。通常由控制邏輯電路、數據寄存器、移位寄存器、D/A轉換器(Digital Analog Converter)和電壓比較器構成。
優點:1.轉換速度快。其轉換周期等於 分辨率 * 時鐘周期(見下式),如一個8位的逐次比較型A/D轉換器,時鐘周期為10us,則其轉換周期為80us。
T轉 = n * Tclk (n為分辨率)
常見的型號:1.ADC0808/ADC0809,8位逐次比較型A/D轉換器,轉換時間100us,輸入電壓範圍0~~5V,可接入8個模擬量輸入。
2.ADC0803/ADC0804,8位逐次比較型A/D轉換器,在1MHz的時鐘頻率下,轉換時間在66~~73us之間,支持一對差分模擬電壓輸入。
逐次比較型A/D轉換器原理圖 ,《数字电子技術》第六版 康華光
ADC0808/ADC0809原理圖,National Semiconductor
ADC0803/ADC0804原理圖,Philips Semiconductors
雙積分式A/D轉換器:一種間接的A/D轉換器,其分別對輸入電壓和參考電壓進行兩次積分,將輸入電壓平均值變換成與之成正比的時間間隔,然後利用時鐘脈衝和計數器測出此時間間隔,進而在輸出端得到與模擬量相應的数字量。通常由積分器(運算放大器及相應的外部電路)、過零比較器(運算放大器)、時鐘脈衝控制門和計數器等構成。
優點:1.抗工頻干擾能力強。通過對輸入電壓的平均值進行變換來實現抗干擾。
缺點:1.轉換速度最慢。
常見的型號:TLC7135,4.5位雙積分式A/D轉換器,CMOS工藝,差分電壓輸入。
雙積分式A/D轉換器原理圖,《数字电子技術》第六版 康華光
TLC7135数字部分原理圖,Texas Instruments
ADC的未來發展方向
ADC在未來會變得性能更強、價格更低、功耗更低、通用性和專業性更強。
性能:從歷史上看,對ADC性能的改進主要集中在改進架構和改善製造工藝兩個方面。ADC有很多架構,典型的包括:FLASH、SAR和雙積分;其他的有:流水線等。在集成電路發展的過程中,出現了許多的工藝:雙極性、ECL、CMOS、CB、BiCMOS、GaAs……這些工藝可以幫助改進ADC的性能。
價格:隨着集成電路工藝的不斷成熟,價格變低只是時間問題。
功耗:得力於集成電路工藝的改善,如:使用更低線寬的IC的功耗會低於高線寬的IC。功耗同時也取決於ADC架構。
元件清單(” * “為可選)
————————————————————時鐘發生器部分——————————————————————–
NE555 *1
*DIP-8芯片座 *1
8位撥碼開關 *1
*3pin排針 *1
3.9K電阻 *1
68K電阻 *1
10uF無極電容 *1
1uF無極電容 *1
100nF無極電容 *1
10nF無極電容 *2
1nF無極電容 *1
100pF無極電容 *1
10pF無極電容 *1
1pF無極電容 *1
所有元件合照(時鐘發生器部分)
———————————————————————————————————————————————–
————————————————————數模轉換器部分——————————————————————–
MCP6004 *1(可以使用LM324替換)
*DIP-14芯片座 *1
CD4042B *1
CD4532B *1
*DIP-16芯片座 *2
2K可調電阻器 *1
330R電阻 *3
390R電阻 *1
1K電阻 *5
LED-G *3
*Pin-3排母 *1
*Pin-2排針 *1
所有元件合照(數模轉換器部分,不含Pin-2排針)
———————————————————————————————————————————————–
電路原理
總原理圖(1)
總原理圖(2)
————————————————————時鐘發生器部分——————————————————————–
555定時器工作在多諧振蕩器模式,通過撥碼開關選擇不同的電容來產生不同頻率的方波。
基於555定時器的時鐘發生器原理圖
————————————————————————————————————————————————
————————————————————數模轉換器部分——————————————————————–
比較器:左側的電阻分壓網絡為右側的四個比較器的反相輸入端提供階梯狀的參考電壓(4V、3V、2V、1V),可調電阻模擬輸入到四個比較器同相端的模擬電壓(0~~5V)。比較器通過比較同相輸入端與反相輸入端電壓的大小,輸出0V(Vp<Vn)或5V(Vp>Vn)給後面的D鎖存器。
運放的特性圖
四路D鎖存器:在時鐘的每一個上升沿,將四個運放輸出的電壓(比較結果)存儲起來並交給後面的編碼器。
優先級編碼器:對來自鎖存器的四個比較結果進行編碼,並輸出給計算機處理(如果有計算機的話)。
———————————————————————————————————————————————–
集成電路簡介
MCP6004:微芯公司生產的低功耗1MHz帶寬的4路運算放大器,本項目的運算放大器均工作在飽和區。
MCP6004實物圖
MCP6004引腳定義
CD4042B:CMOS四路D鎖存器,在本項目中使用上升沿觸發,時鐘由555定時器提供,用於保存MCP6004輸出的4位數據。
CD4042B實物圖
CD4042B引腳定義
CD4042B真值表
CD4532B: CMOS的8位優先級編碼器,用於對CD4042B鎖存的數據進行編碼。
CD4532B實物圖
CD4532B引腳定義
CD4532B真值表
測試
————————————————————時鐘發生器部分——————————————————————–
此555時鐘發生電路,實際測試可以產生1Hz、10Hz、100Hz、1KHz、10KHz、100KHz、0.4MHz、0.7MHz的方波信號。實測中,產生的0.4MHz和0.7MHz與設計的1MHz、10MHz存在較大的誤差,可能是電容的問題(這兩個頻率對應所使用的是貼片電容)。
時鐘發生器(正面)
時鐘發生器(反面)
實測產生的最大頻率的波形(Vcc=5V下,Vpp=4.7V)
————————————————————————————————————————————————
————————————————————數模轉換器部分——————————————————————–
在時鐘為400KHz下,此并行比較型A/D可以正常工作;使用700KHz的時鐘會導致轉換故障。
主要參數:A/D分辨率為3位(嚴格來說只有2位,可以在不改變架構的情況下通過增加4個比較器拓增至3位)
採樣率為400KSPS~~700KSPS。
功耗:20mA@5V = 100mW (包含時鐘發生器部分)
當輸入電壓為2.5V時,輸出的情況(可以看出LED指示“101”,正好是對“1100”編碼的結果)
正面(1)
正面(2)
反面
———————————————————————————————————————————————–
聲明
此教程未經DLHC允許,禁止轉載。所有引用均註明了出處。DLHC保留所有權利。
由於本人學識有限且整理較為倉促,如有錯誤或不妥,請指正。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※教你寫出一流的銷售文案?
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※回頭車貨運收費標準
※別再煩惱如何寫文案,掌握八大原則!
※超省錢租車方案
(P 280)異常處理需要考慮的問題:
(P 280)傳統的處理錯誤的方法是:返回一個特殊的錯誤碼,常見的是返回-1或者null引用
(P 280)在Java中,方法出現錯誤時,它會立即退出,不返回任何值,而是拋出一個封裝了錯誤信息的對象
(P 280)Java中所有的異常都是由Throwable繼承而來,它下面又分解為兩個分支:Error和Exception
Error:描述了Java運行時系統的內部錯誤和資源耗盡錯誤(對於處理這種錯誤,你幾乎無能為力)Exception:又分解為兩個分支:RuntimeException(由編程錯誤導致,如果出現該異常,那一定是你的問題)和其他異常(諸如IO錯誤這類問題)
RuntimeException的異常:
null指針RuntimeException的異常:
Class對象,而這個字符串表示的類並不存在graph TD Throwable[Throwable]–>Error[Error] Throwable[Throwable]–>Exception[Exception] Error[Error]–>OtherError1[…] Error[Error]–>OtherError2[…] Error[Error]–>OtherError3[…] Exception[Exception]–>RuntimeException[RuntimeException] Exception[Exception]–>IOException[IOException] Exception[Exception]–>OtherException[…] IOException[IOException]–>OtherIOException1[…] IOException[IOException]–>OtherIOException2[…] IOException[IOException]–>OtherIOException3[…] RuntimeException[RuntimeException]–>OtherRuntimeException1[…] RuntimeException[RuntimeException]–>OtherRuntimeException2[…] RuntimeException[RuntimeException]–>OtherRuntimeException3[…]
(P 281)派生於Error和RuntimeException的所有異常稱為非檢查型異常,所有其他異常稱為檢查型異常
(P 282)如果沒有處理器捕獲異常對象,那麼當前執行的線程就會終止
(P 283)必須在方法的首部列出所有檢查型異常類型,但是不需要聲明從Error繼承的異常,也不應該聲明從RuntimeException繼承的那些非檢查型異常
(P 283)如果在子類中覆蓋了超類的一個方法,子類方法中聲明的檢查型異常不能比超類方法中聲明的異常更通用(子類方法可以拋出更特定的異常,或者根本不拋出任何異常)。如果超類方法沒有拋出任何檢查型異常,子類也不能拋出任何檢查型異常
(P 288)同一個catch子句中可以捕獲多個異常類型,如果一些異常的處理邏輯是一樣的,就可以合併catch子句。只有當捕獲的異常類型彼此之間不存在子類關係時才需要這個特性
try {
...
} catch (FileNotFoundException | UnknownHostException e) {
...
} catch (IOException e) {
...
}
(P 289)可以在catch子句中拋出一個異常,此時,可以把原始異常設置為新異常的“原因”
try {
...
} catch (SQLException original) {
var e = new ServletException("database error");
e.initCause(original);
throw e;
}
捕獲異常時,獲取原始異常
Throwable original = caughtException.getCause();
(P 292)一種推薦的異常捕獲寫法:內層try語句塊只有一個職責,就是確保釋放資源,外層try語句塊也只有一個職責,就是確保報告出現的錯誤
try {
try {
...
} finally {
// 釋放資源
}
} catch (Exception e) {
// 報告錯誤
}
(P 293)Java 7中,對於實現了AutoCloseable接口的類,可以使用帶資源的try語句(try-with-resources):
try (Resources res = ...) {
// Work with res
...
}
Java 9中,可以在try首部中提供之前聲明的事實最終變量(effectively final variable):
try (res) {
// Work with res
...
} // res.close() called here
(P 294)在try-with-resources語句中,如果try塊拋出一個異常,而且close方法也拋出一個異常,則原來的異常會重新拋出,而close方法拋出的異常會“被抑制”(可以通過getSuppressed方法得到這些被抑制的異常)
(P 294)可以通過StackWalker類處理堆棧軌跡
var walker = StackWalker.getInstance();
walker.forEach(frame -> ...); // 例如:walker.forEach(System.out::println);
(P 298)使用異常的一些技巧:
try語句塊中,將正常處理與錯誤處理分開)(P 301)Java中引入了關鍵字assert,其有如下兩種形式:
assert condition;
assert condition : expression;
這兩個語句都會計算條件,如果結果為false,則拋出一個AssertionError異常。在第二個語句中,表達式將傳入AssertionError對象的構造器,並轉換為一個消息字符串
(P 301)默認情況下,斷言是禁用的,可以使用-enableassertions或者-ea選項啟用斷言:
java -enableassertions MyApp
禁用斷言可以使用-disableassertions或-da
(P 302)斷言只應該用於在測試階段確定程序內部錯誤的位置
(P 305)基本日誌的使用:
生成簡單的日誌記錄
Logger.getGlobal().info("hello world!");
取消所有日誌
Logger.getGlobal().setLevel(Level.OFF);
(P 305)高級日誌的使用:
創建或獲取日誌記錄器
private static final Logger myLogger = Logger.getLogger("className"); // className是全限定類名
設置日誌級別
logger.setLevel(Level.FINE); // FINE以及更高級別的日誌都會被記錄
記錄日誌
// 調用相應級別的日誌記錄方法
logger.warning(message);
logger.fine(message);
// 使用log方法並指定級別
logger.log(Level.FINE, message);
// 跟蹤執行流的方法
logger.entering("className", "methodName", new Object[]{ params... });
logger.exiting("className", "methodName", result);
// 在日誌記錄中包含異常的描述
logger.throwing("className", "methodName", exception);
logger.log(Level.WARNING, message, exception);
(P 305)7個日誌級別:
(P 307)可以通過配置文件修改日誌系統的各個屬性,默認情況下,配置文件位於:
conf/logging.properties
指定特定位置的配置文件:
java -Djava.util.logging.config.file=configFile MainClass
指定日誌記錄器的日誌級別:在日誌記錄器名後面追加後綴.level,例如
com.mycompany.myapp.level=FINE
(P 313)日誌技巧
(P 321)調試技巧
打印或日誌記錄變量的值
在每一個類中放置一個單獨的main方法,以便獨立地測試類
使用JUnit
日誌代理,它是一個子類的對象,可以截獲方法調用,記錄日誌,然後調用超類中的方法
var generator = new Random() {
public double nextDouble() {
double result = super.nextDouble();
Logger.getGlobal().info("nextDouble: " + result);
return result;
}
}
利用Throwable類的printStackTrace方法,可以從任意的異常對象獲得堆棧軌跡
一般來說,堆棧軌跡显示在System.err上。如果想要記錄或显示堆棧軌跡,可以將它捕獲到一個字符串中
var out = new StringWriter();
new Throwable().printStackTrace(new PrintWriter(out));
String description = out.toString();
通常,將程序錯誤記入一個文件會很有用:
java MyProgram > errors.txt # 錯誤,錯誤被發送到System.err而不是System.out
java MyProgram 2> errors.txt # 正確,只輸出System.err
java MyProgram 1> errors.txt 2>&1 # 同時捕獲System.out和System.err
將未捕獲的異常的堆棧軌跡記錄到一個文件中,而不是直接輸出到System.err,可以使用靜態方法Thread.setDefaultUncaughtExceptionHandler改變未捕獲異常的處理器
Thread.setDefaultUncaughtExceptionHandler(
new Thread.UncaughtExceptionHandler() {
public void uncaughtException(Thread t, Throwable e) {
// save information in log file
}
}
)
要想觀察類的加載過程,啟動Java虛擬機時可以使用-verbose標誌
-Xlint選項告訴編譯器找出常見的代碼問題
javac -Xlint sourceFiles
Java虛擬機增加了對Java應用程序的監控和管理支持,允許在虛擬機中安裝代理來跟蹤內存消耗、線程使用、類加載等情況。jconsole工具可以显示有關虛擬機性能的統計結果
Java任務控制器:一個專業級性能分析和診斷工具
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※超省錢租車方案
※別再煩惱如何寫文案,掌握八大原則!
※回頭車貨運收費標準
※教你寫出一流的銷售文案?

作者:CODING – 朱增輝
make 工具非常強大,配合 makefile 文件可以實現軟件的自動化構建,但是執行 make 命令依然需要經歷手動輸入執行、等待編譯完成、將目標文件轉移到合適位置等過程,我們真正關心的是最終的輸出,卻在這些中間過程上浪費了很多時間。利用 CODING 持續集成功能可以實現自動觸發構建,構建全程自動化,無須分心看護,節省時間。
本文通過一個 C 語言 + Makefile Demo 項目講解如何使用 CODING 持續集成功能創建構建計劃,自動觸發構建,以及如何將生成的目標文件發布到 CODING generic 製品庫。
本文涉及到以下工具,請確認已存在,或者根據鏈接的文檔進行安裝。
另外,您還需準備一個 CODING 項目。
我已經準備了一份簡單的示例代碼,使用 make 工具構建 Hello-world 程序。
// hello.c
#include <stdio.h>
int main() {
printf("Hello, World!\n");
return 0;
}
您可以通過下面的命令克隆到本地。
git clone https://e.coding.net/coding-public/demo-c-make.git
倉庫中還包含了一個 makefile 文件,定義了簡單的規則來完成軟件構建。
all: hello
hello: hello.o
gcc -o hello hello.o
hello.o: hello.c
gcc -c hello.c
clean:
rm -rf hello.o hello
您可以在本地執行 make 命令以驗證構建正常。
下面我們正式開始通過一個 Demo 演示 CODING 平台持續集成功能的使用。
為了方便隨時使用構建出來的目標文件,我們將構建物存儲到 CODING 平台製品庫,因此需要先創建合適的製品倉庫,這裏創建 generic 倉庫比較合適。
從左側導航欄打開製品庫。
單擊新建倉庫,選擇 generic 類型,按照提示指定倉庫名稱,這裏倉庫名取為 generic。
從左側導航欄打開持續集成 --> 構建計劃頁面,點擊新建構建計劃配置創建並配置新的構建計劃。在彈出的頁面中,輸入構建計劃名稱,選擇代碼倉庫,配置來源指的的該構建計劃的構建腳本存放位置,對於簡單的、變動不頻繁的腳本可以使用靜態配置的選項,否則更推薦使用代碼倉庫中的腳本,這樣更加靈活,方便管理
點擊使用模板,可根據自己需要選擇合適模板,這裏選擇 簡易模板。
保存構建計劃后,系統會自動將構建模板對應的 Jenkinsfile 推送到倉庫,默認為 master 分支。
構建腳本定義構建過程的具體步驟,是構建計劃的核心部分。CODING 平台提供了圖形化編輯器方便您快速編寫構建腳本。
CODING 持續集成底層基於開源 CI/CD 軟件領導者 Jenkins 實現,完全兼容 Jenkins pipeline 構建腳本語法,根據 Jenkins 官方提供的腳本編寫指南,可以實現更複雜的構建任務,CODING 也提供了文本編輯器方便您在線編輯。
代碼倉庫中已包含一個簡單的構建腳本(Jenkisnfile),您可以按照自己的想法參考編寫。
// Jenkinsfile
pipeline {
agent any
stages {
stage('檢出') {
steps {
checkout([
$class: 'GitSCM',
branches: [[name: env.GIT_BUILD_REF]],
userRemoteConfigs: [[
url: env.GIT_REPO_URL,
credentialsId: env.CREDENTIALS_ID
]]])
}
}
stage('構建') {
steps {
echo '構建中...'
sh 'make'
echo '構建完成.'
}
}
stage('發布') {
steps {
echo '發布中...'
codingArtifactsGeneric(
files: 'hello',
repoName: "${env.GENERIC_REPO_NAME}",
version: "${env.GIT_COMMIT}",
)
echo '發布完成'
}
}
}
}
}
構建腳本中的大部分內容都比較容易理解,稍顯陌生的是 codingArtifactsGeneric 步驟,這是 CODING 官方提供的插件,方便上傳到 CODING generic 製品庫。該插件通過環境變量 GENERIC_REPO_NAME 獲取倉庫名,因此需要配置構建計劃設置該變量值。
CODING 持續功能支持多種觸發方式包括代碼源觸發、定時觸發、API 觸發及手動觸發,這幾種觸發方式可以同時配置互不衝突,其中代碼源觸發又可配置為推送到指定分支或標籤觸發,觸發方式多樣,可滿足絕大部分場景需要。
如前言中所說,我們希望把更多的精力放在源代碼上,盡量減少構建所帶來的干擾,因此這裏必不可少的是配置通過代碼源觸發,通過配置如下正則表達式,可以在推送代碼到匹配的分支名時自動觸發構建。
^refs/(heads/(release|release-.*|build-.*|feat-.*|fix-.*|test-.*|mr/.*))
執行構建最簡單的方式是手動觸發構建,選中想要構建的構建計劃,單擊立即構建會彈出配置窗口,在這裏可以配置此次構建使用的參數,單擊確定即可開始構建。
按照步驟四的配置,我們的構建計劃也支持推送的匹配分支觸發構建,您可以執行如下命令創建新分支並推送到遠端倉庫,即可觸發構建。
git checkout -b build-ci-test
git push origin HEAD
觸發后,構建會自動執行,您可以繼續做其他事情。
步驟三中定義的構建腳本會將構建出的目標文件發布到 CODING 製品庫,如果我們想要在本地使用也是很方便下載的。在製品倉庫中單擊文件名即可看到指引頁,裏面給出了對文件不同操作的命令。
本文通過一個 C 語言 + makefile 的 Demo 項目講解了 CODING 持續集成、製品庫的簡單使用。藉由 CODING 平台的這些功能,我們像是雇了一個永不會累的助手,承擔了耗時的構建工作,從而節省了時間,提高了效率。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※網頁設計一頭霧水該從何著手呢? 台北網頁設計公司幫您輕鬆架站!
※網頁設計公司推薦不同的風格,搶佔消費者視覺第一線
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※廣告預算用在刀口上,台北網頁設計公司幫您達到更多曝光效益
※別再煩惱如何寫文案,掌握八大原則!