前邊的兩篇文章裏面,我們講解了基於docker來部署基礎的SpringBoot容器,如果閱讀本文之前沒有相關基礎的話,可以回看之前的教程。
不知道大家在初次使用docker的時候是否有遇到這種場景,每次部署微服務都是需要執行docker run xxx,docker kill xxx 等命令來操作容器。假設說一個系統中依賴了多個docker容器,那麼對於每個docker容器的部署豈不是都需要手動編寫命令來啟動和關閉,這樣做就會增加運維人員的開發工作量,同時也容易出錯。
Docker Compose 編排技術
在前邊的文章中,我們講解了Docker容器化技術的發展,但是隨着我們的Docker越來越多的時候,對於容器的管理也是特別麻煩,因此Docker Compose技術也就誕生了。
Docker Compose技術是通過一份文件來定義和運行一系列複雜應用的Docker工具,通過Docker-compose文件來啟動多個容器,網上有很多關於Docker-compose的實戰案例,但是都會有些細節地方有所遺漏,所以下邊我將通過一個簡單的案例一步步地帶各位從淺入深地對Docker-compose進行學習。
基於Docker Compose來進行對SpringBoot微服務應用的打包集成
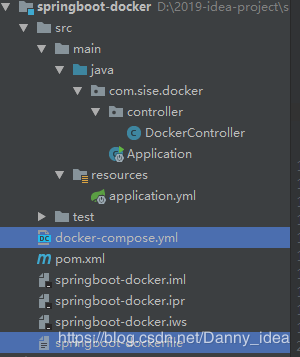
我們還是按照老樣子來構建一套基礎的SpringBoot微服務項目,首先我們來看看基礎版本的項目結構:
首先是我們pom文件的配置內容:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.sise.idea</groupId> <artifactId>springboot-docker</artifactId> <version>1.0-SNAPSHOT</version> <packaging>jar</packaging> <name>spring-boot-docker</name> <url>http://maven.apache.org</url> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>2.0.3.RELEASE</version> </parent> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.16.18</version> </dependency> </dependencies> <build> <finalName>springboot-docker</finalName> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> </plugins> </build> </project>
然後是java程序的內容代碼,這裏面有常規的controller,application類,代碼如下所示:
啟動類Application
package com.sise.docker; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; /** * @author idea * @data 2019/11/20 */ @SpringBootApplication public class Application { public static void main(String[] args) { SpringApplication.run(Application.class); } }
控制器 DockerController
package com.sise.docker.controller; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; /** * @author idea * @data 2019/11/20 */ @RestController @RequestMapping(value = "/docker") public class DockerController { @GetMapping(value = "/test") public String test(){ System.out.println("=========docker test========="); return "this is docker test"; } }
yml配置文件:
server:
port: 7089
接下來便是docker-compose打包時候要用到的配置文件了。這裏採用的方式通常都是針對必要的docker容器編寫一份dockerfile,然後統一由Docker Compose進行打包管理,假設我們的微服務中需要引用到了MySQL,MongoDB等應用,那麼整體架構如下圖所示:
那麼我們先從簡單的單個容器入手,看看該如何對SpringBoot做Docker Compose的管理,下邊是一份打包SpringBoot進入Docker容器的Dockerfile文件:
#需要依賴的其他鏡像 FROM openjdk:8-jdk-alpine # Spring Boot應用程序為Tomcat創建的默認工作目錄。作用是在你的主機”/var/lib/docker”目錄下創建一個臨時的文件,並且鏈接到容器中#的”/tmp”目錄。 VOLUME /tmp #是指將原先的src文件 添加到我們需要打包的鏡像裏面 ADD target/springboot-docker.jar app.jar #設置鏡像的時區,避免出現8小時的誤差 ENV TZ=Asia/Shanghai #容器暴露的端口號 和SpringBoot的yml文件暴露的端口號要一致 EXPOSE 7089 #輸入的啟動參數內容 下邊這段內容相當於運行了java -Xms256m -Xmx512m -jar app.jar ENTRYPOINT ["java","-Xms256m","-Xmx512m","-jar","app.jar"]
接着便是加入docker-compose.yml文件的環節了,下邊是腳本的內容:
#docker引擎對應所支持的docker-compose文本格式 version: '3' services: #服務的名稱 springboot-docker: build: context: . # 構建這個容器時所需要使用的dockerfile文件 dockerfile: springboot-dockerfile ports: # docker容器和宿主機之間的端口映射 - "7089:7089"
docker-compose.ym配置文件有着特殊的規則,通常我們都是先定義version版本號,然後便是列舉一系列與容器相關的services內容。
接下來將這份docker服務進行打包,部署到相關的linux服務器上邊,這裏我採用的是一台阿里雲上邊購買的服務器來演示。
目前該文件還沒有進行打包處理,所以沒有target目錄,因此dockerfile文件構建的時候是不會成功的,因此需要先進行mvn的打包:
mvn package
接着便是進行Docker-Compose命令的輸入了:
[root@izwz9ic9ggky8kub9x1ptuz springboot-docker]# docker-compose up -d Starting springboot-docker_springboot-docker_1 ... done [root@izwz9ic9ggky8kub9x1ptuz springboot-docker]#
你會發現這次輸入的命令和之前教程中提及的docker指令有些出入,變成了docker-compose 指令,這條指令是專門針對Docker compose文件所設計的,加入了一個-d的參數用於表示後台運行該容器。由於我們的docker-compose文件中知識編寫了對於SpringBoot容器的打包,因此啟動的時候只會显示一個docker容器。
為了驗證docker-compose指令是否生效,我們可以通過docker–compose ps命令來進行驗證。
這裏邊我們使用 docker logs [容器id] 指令可以進入容器查看日誌的打印情況:
docker logs ad83c82b014d
最後我們通過請求之前寫好的接口便會看到相關的響應:
基礎版本的SpringBoot+Docker compose案例已經搭建好了,還記得我在開頭畫的那張圖片嗎:
通常在實際開發中,我們所面對的docker容器並不是那麼的簡單,還有可能會依賴到多個容器,那麼這個時候該如何來編寫docker compose文件呢?
下邊我們對原先的SpringBoot項目增加對於MySQL和MongoDB的依賴,為了方便下邊的場景模擬,這裏我們增加兩個實體類:
用戶類
package com.sise.docker.domain; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; /** * @author idea * @data 2019/11/23 */ @AllArgsConstructor @NoArgsConstructor @Data public class User { private Integer id; private String username; }
汽車類:
package com.sise.docker.domain; import lombok.AllArgsConstructor; import lombok.Data; import lombok.NoArgsConstructor; import org.springframework.data.annotation.Id; /** * @author idea * @data 2019/11/23 */ @Data @AllArgsConstructor @NoArgsConstructor public class Car { @Id private Integer id; private String number; }
增加對於mongodb,mysql的pom依賴內容
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-mongodb</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>5.1.21</version> </dependency>
編寫相關的dao層:
package com.sise.docker.dao; import com.sise.docker.domain.Car; import org.springframework.data.mongodb.repository.MongoRepository; import org.springframework.stereotype.Repository; /** * @author idea * @data 2019/11/23 */ @Repository public interface CarDao extends MongoRepository<Car, Integer> { } package com.sise.docker.dao; import com.sise.docker.domain.User; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.jdbc.core.JdbcTemplate; import org.springframework.jdbc.core.RowMapper; import org.springframework.stereotype.Repository; import java.sql.ResultSet; import java.sql.SQLException; /** * @author idea * @data 2019/11/23 */ @Repository public class UserDao { @Autowired private JdbcTemplate jdbcTemplate; public void insert() { String time = String.valueOf(System.currentTimeMillis()); String sql = "insert into t_user (username) values ('idea-" + time + "')"; jdbcTemplate.update(sql); System.out.println("==========執行插入語句=========="); } class UserMapper implements RowMapper<User> { @Override public User mapRow(ResultSet resultSet, int i) throws SQLException { User unitPO = new User(); unitPO.setId(resultSet.getInt("id")); unitPO.setUsername(resultSet.getString("username")); return unitPO; } } }
在控制器中添加相關的函數入口:
package com.sise.docker.controller; import com.sise.docker.dao.CarDao; import com.sise.docker.dao.UserDao; import com.sise.docker.domain.Car; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.web.bind.annotation.GetMapping; import org.springframework.web.bind.annotation.RequestMapping; import org.springframework.web.bind.annotation.RestController; import java.util.Random; /** * @author idea * @data 2019/11/20 */ @RestController @RequestMapping(value = "/docker") public class DockerController { @Autowired private UserDao userDao; @Autowired private CarDao carDao; @GetMapping(value = "/insert-mongodb") public String insertMongoDB() { Car car = new Car(); car.setId(new Random().nextInt(15000000)); String number = String.valueOf(System.currentTimeMillis()); car.setNumber(number); carDao.save(car); return "this is insert-mongodb"; } @GetMapping(value = "/insert-mysql") public String insertMySQL() { userDao.insert(); return "this is insert-mysql"; } @GetMapping(value = "/test2") public String test() { System.out.println("=========docker test222========="); return "this is docker test"; } }
對原先的docker-compose.yml文件添加相應的內容,主要是增加對於mongodb和mysql的依賴模塊,
#docker引擎對應所支持的docker-compose文本格式 version: '3' services: #服務的名稱 springboot-docker: container_name: docker-springboot build: context: . dockerfile: springboot-dockerfile ports: - "7089:7089" depends_on: - mongodb mongodb: #容器的名稱 container_name: docker-mongodb image: daocloud.io/library/mongo:latest ports: - "27017:27017" mysql: #鏡像的版本 image: mysql:5.7 container_name: docker-mysql ports: - 3309:3306 environment: MYSQL_DATABASE: test MYSQL_ROOT_PASSWORD: root MYSQL_ROOT_USER: root MYSQL_ROOT_HOST: '%'
這裏頭我嘗試將application.yml文件通過不同的profile來進行區分:
應上篇文章中有讀者問到,不同環境不同配置的指定問題,這裡有一種思路,springboot依舊保持原有的按照profile來識別不同環境的配置,具體打包之後讀取的配置,可以通過springboot-dockerfile這份文件的ENTRYPOINT 參數來指定,例如下邊這種格式:
FROM openjdk:8-jdk-alpine VOLUME /tmp ADD target/springboot-docker.jar springboot-docker.jar #設置鏡像的時區,避免出現8小時的誤差 ENV TZ=Asia/Shanghai EXPOSE 7089 #這裏可以通過-D參數在對jar打包運行的時候指定需要讀取的配置問題 ENTRYPOINT ["java","-Xms256m","-Xmx512m","-Dspring.profiles.active=prod","-jar","springboot-docker.jar"]
最後便是我們的yml配置文件內容,由於配置類docker容器的依賴,所以這裏面對於yml的寫法不再是通過ip來訪問相應的數據庫了,而是需要通過service-name的映射來達成目標。
application-prod.yml
server: port: 7089 spring: data: mongodb: uri: mongodb://mongodb:27017 database: test datasource: driver-class-name: com.mysql.jdbc.Driver url: jdbc:mysql://mysql:3306/test?useUnicode=true&characterEncoding=UTF-8 username: root password: root
當相關的代碼和文件都整理好了之後,將這份代碼發送到服務器上進行打包。
mvn package
接着我們便可以進行docker-compose的啟動了。
這裡有個小坑需要注意一下,由於之前我們已經對單獨的springboot容器進行過打包了,所以在執行docker-compose up指令的時候會優先使用已有的容器,而不是重新創建容器。
這個時候需要先將原先的image鏡像進行手動刪除,再打包操作:
[root@izwz9ic9ggky8kub9x1ptuz springboot-docker]# docker images REPOSITORY TAG IMAGE ID CREATED SIZE springboot-docker latest 86f32bd9257f 4 hours ago 128MB <none> <none> 411616c3d7f7 2 days ago 679MB <none> <none> 77044e3ad9c2 2 days ago 679MB <none> <none> 5d9328dd1aca 2 days ago 679MB springbootmongodocker_springappserver latest 36237acf08e1 3 days ago 695MB
刪除鏡像的命令:
docker rmi 【鏡像id】
此時再重新進行docker-compose指令的打包操作即可:
docker-compose up
啟動之後,可以通過docker-compose自帶的一些指令來進行操作,常用的一些指令我都歸納在了下邊:
docker-compose [Command]
Commands: build 構建或重建服務 bundle 從compose配置文件中產生一個docker綁定 config 驗證並查看compose配置文件 create 創建服務 down 停止並移除容器、網絡、鏡像和數據卷 events 從容器中接收實時的事件 exec 在一個運行中的容器上執行一個命令 help 獲取命令的幫助信息 images 列出所有鏡像 kill 通過發送SIGKILL信號來停止指定服務的容器 logs 從容器中查看服務日誌輸出 pause 暫停服務 port 打印綁定的公共端口 ps 列出所有運行中的容器 pull 拉取並下載指定服務鏡像 push Push service images restart 重啟YAML文件中定義的服務 rm 刪除指定已經停止服務的容器 run 在一個服務上執行一條命令 scale 設置指定服務運行容器的個數 start 在容器中啟動指定服務 stop 停止已運行的服務 top 显示各個服務容器內運行的進程 unpause 恢復容器服務 up 創建並啟動容器 version 显示Docker-Compose版本信息
最後對相應的接口做檢測:
相關的完整代碼我已經上傳到了gitee地址,如果有需要的朋友可以前往進行下載。
代碼地址:https://gitee.com/IdeaHome_admin/wfw
實踐完畢之後,你可能會覺得有了docker-compose之後,對於多個docker容器來進行管理顯得就特別輕鬆了。
但是往往現實中並沒有這麼簡單,docker-compose存在着一個弊端,那就是不能做跨機器之間的docker容器進行管理。
因此隨者技術的發展,後邊也慢慢出現了一種叫做Kubernetes的技術。Kubernetes(俗稱k8s)是一個開源的,用於管理雲平台中多個主機上的容器化的應用,Kubernetes的目標是讓部署容器化的應用簡單並且高效(powerful),Kubernetes提供了應用部署,規劃,更新,維護的一種機制。
Kubernetes這類技術對於小白來說入門的難度較高,後邊可能會抽空專門來寫一篇適合小白閱讀的k8s入門文章。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益