新聞
視頻及幻燈片
博客
F# vNext
- F#語言建議:
GitHub項目
最新的發布
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
說明:本文實例使用Python版本為3.5.6,Tensorflow版本為2.0
Tensorflow是Google推出的機器學習開源神器,對Python有着良好的語言支持,支持CPU,GPU和Google TPU等硬件,並且已經擁有了各種各樣的模型和算法。目前,Tensorflow已被廣泛應用於文本處理,語音識別和圖像識別等多項機器學習和深度學習領域。
分為三層:應用層、接口層和核心層
應用層
提供了機器學習相關的訓練庫、預測庫和針對Python、C++和Java等變成語言的編程環境,類似於web系統的前端,主要實現了對計算圖的構造。
接口層
對Tensorflow功能模塊的封裝,便於其它語言平台的調用。
核心層
最重要的部分,包括設備層、網絡層、數據操作層和圖計算層,執行應用層的計算。
1.設備層
包括Tensorflow在不同硬件設備上的實現,主要支持CPU、GPU和Mobile等設備,在不同硬件設備上實現計算命令的轉換,給上層提供統一的接口,實現程序的跨平台功能。
2.網絡層
網絡層主要包括RPC和RDMA通信協議,實現不同設備之間的數據傳輸和更新,這些協議都會在分佈式計算中用到。
3.數據操作層
以tensor為處理對象,實現tensor的各種操作和計算。
4.圖計算層
包括分佈式計算圖和本地計算圖的實現,實現圖的創建、編譯、優化和執行等。
可以將Tensorflow理解為一張計算圖中“張量的流動”,其中,Tensor(張量)代表了計算圖中的邊,Flow(流動)代表了計算圖中節點所做的操作而形成的數據流動。
其設計理念是以數據流為核心,當構建相應的機器學習模型后,使用訓練數據在模型中進行數據流動,同時將結果以反向傳播的方式反饋給模型中的參數,以進行調參,使用調整后的參數對訓練數據再次進行迭代計算。
有兩個編程特點:
在tensorflow中,需要預先定義各種變量,建立相關的數據流圖,在數據流圖中創建各種變量之間的計算關係,完成圖的定義,需要把運算的輸入數據放進去后,才會形成輸出值。
tensorflow的相關計算在圖中進行定義,而圖的具體運行壞境在會話(session)中,開啟會話后,才能開始計算,關閉會話就不能再進行計算了。
舉個例子:
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
a = 3
b = 4
c = 5
y = tf.add(a*b, c)
print(y)
a = tf.constant(3, tf.int32)
b = tf.constant(4, tf.int32)
c = tf.constant(5, tf.int32)
y = tf.add(a*b, c)
print(y)
session = tf.compat.v1.Session()
print(session.run(y))
session.close()可以看出,在圖創建后,並在會話中執行數據計算,最終輸出結果。
設計的好處就是:學習的過程中,消耗最多的是對數據的訓練,這樣設計的話,當進行計算時,圖已經確定,計算就只剩下一個不斷迭代的過程。
張量,是tensorflow中最主要的數據結構,張量用於在計算圖中進行數據傳遞,創建了張量后,需要將其賦值給一個變量或佔位符,之後才會將該張量添加到計算圖中。
會話,是Tensorflow中計算圖的具體執行者,與圖進行實際的交互。一個會話中可以有多個圖,會話的主要目的是將訓練數據添加到圖中進行計算,也可以修改圖的結構。
調用模式推薦使用with語句:
with session:
session.run()變量,表示圖中的各個計算參數,通過調整這些變量的狀態來優化機器學習算法。創建變量應使用tf.Variable(),通過輸入一個張量,返回一個變量,變量聲明后需進行初始化才能使用。
舉例說明:
import tensorflow as tf
tf.compat.v1.disable_eager_execution()
tensor = tf.ones([1, 3])
test_var = tf.Variable(tensor)
# 初始化變量
init_op = tf.compat.v1.global_variables_initializer()
session = tf.compat.v1.Session()
with session:
print("tensor is ", session.run(tensor))
# print("test_var is ", session.run(test_var))
session.run(init_op)
print("after init, test_var is", session.run(test_var))佔位符,用於表示輸入輸出數據的格式,聲明了數據位置,允許傳入指定類型和形狀的數據,通過會話中的feed_dict參數獲取數據,在計算圖運行時使用獲取的數據進行計算,計算完畢后獲取的數據就會消失。
舉例說明:
x = tf.compat.v1.placeholder(tf.int32)
y = tf.compat.v1.placeholder(tf.int32)
z = tf.add(x, y)
session = tf.compat.v1.Session()
with session:
print(session.run([z], feed_dict={x: [1, 2], y: [2, 3]}))操作,是圖中的節點,輸入輸出都是Tensor,作用是完成各種操作,包括:
隊列,圖中有狀態的節點。包含入列(endqueue)和出列(dequeue)兩個操作,入列返回計算圖中的一個操作節點,出列返回一個tensor值。
其中,隊列有兩種:
1. FIFOQueue
按入列順序出列的隊列,在需要讀入的訓練樣本有序時使用。舉個例子:
fifo_queue = tf.compat.v1.FIFOQueue(10, 'int32')
init = fifo_queue.enqueue_many(([1, 2, 3, 4, 5, 6], ))
with tf.compat.v1.Session() as session:
session.run(init)
queue_size = session.run(fifo_queue.size())
for item in range(queue_size):
print('fifo_queue', session.run(fifo_queue.dequeue()))2. RandomShuffleQueue
以隨機順序出列的隊列,讀入的訓練樣本無序時使用。舉個例子:
rs_queue = tf.compat.v1.RandomShuffleQueue(capacity=5, min_after_dequeue=0, dtypes='int32')
init = rs_queue.enqueue_many(([1, 2, 3, 4, 5], ))
with tf.compat.v1.Session() as session:
session.run(init)
queue_size = session.run(rs_queue.size())
for i in range(queue_size):
print('rs_queue', session.run(rs_queue.dequeue()))代碼參考:
以上。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
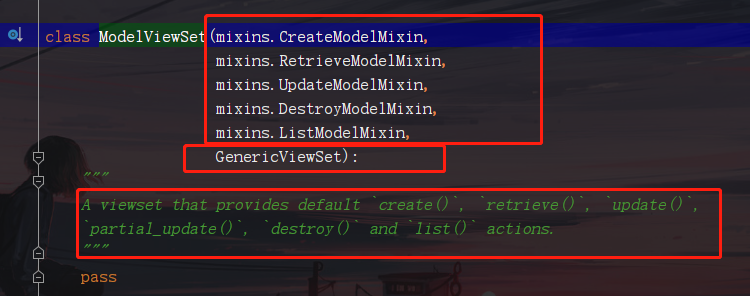
1.導入分類
from rest_framewok import views, generics, mixins, viewsets
views:視圖類
兩大視圖類:APIView、GenericAPIView
from rest_framework.views import APIView
from rest_framework.generics import GenericAPIViewmixins:視圖工具類
六大視圖工具類: RetrieveModelMixin, ListModelMixin, CreateModelMixin, UpdateModelMixin, DestroyModelMixin
from rest_framework.mixins import RetrieveModelMixin, ListModelMixin, CreateModelMixin, UpdateModelMixin, DestroyModelMixingenerics:工具視圖類
九大工具視圖類:…
from rest_framework import genericsviewsets:視圖集
兩大視圖集基類:ViewSet、GenericViewSet
from rest_framework import viewsets2.APIVIiew的特性
它繼承了Django的View
1)View:將請求方式與視圖類的同名方法建立映射,完成請求響應
2)APIView:
繼承了View所有的功能;
重寫as_view禁用csrf認證;
重寫dispatch:請求、響應、渲染、異常、解析、三大認證
多了一堆類屬性,可以完成視圖類的局部配置
APIView:
from rest_framework.views import APIView
from rest_framework.response import Response
from . import models,serializers
# APIView:
class StudentAPIView(APIView):
def get(self, request, *args, **kwargs):
# 群查
stu_query = models.Sudent.objects.all()
stu_ser = serializers.StudentModelSerializer(stu_query,many=True)
print(stu_ser)
return Response(stu_ser.data)
GenericAPIView:
# GenericAPIView:
from rest_framework.generics import GenericAPIView
class StudentGenericAPIView(GenericAPIView):
queryset = models.Sudent.objects.all()
serializer_class = serializers.StudentModelSerializer
def get(self, request, *args, **kwargs):
# 群查
# stu_query = models.Sudent.objects.all()
stu_query = self.get_queryset()
# stu_ser = serializers.StudentModelSerializer(stu_query,many=True)
stu_ser = self.get_serializer(stu_query, many=True)
return Response(stu_ser.data)區別:
1.GenericAPIView繼承了APIView,所以它可以用APIView所有的功能
2.GenericAPIView內部提供了三個常用方法:
get_object(): 拿到單個準備序列化的對象,用於單查
get_queryset(): 拿到含有多條數據的Queryset對象,用於群查
get_serializer(): 拿到經過序列化的的serializer對象
3.三個常用屬性:
queryset
serializer_class
lookup_url_kwarg
以單增和群查為例:
from rest_framework import mixins
class StudentMixinGenericAPIView(mixins.ListModelMixin, mixins.CreateModelMixin, GenericAPIView):
queryset = models.Sudent.objects.all()
serializer_class = serializers.StudentModelSerializer
# 群查
def get(self, request, *args, **kwargs):
return self.list(request, *args, **kwargs)
# 單增
def post(self, request, *args, **kwargs):
return self.create(request, *args, **kwargs)特點:
1.提供了五大工具類及其六大工具方法:
CreateModelMixin: create() 實現單增
ListModelMixin: list() 實現群查
RetrieveModelMixin:retrieve() 實現單查
UpdateModelMixin: update() 實現單改 和 perform_update() 實現局部改
DestroyModelMixin : destroy() 實現單刪
2.只要調用工具類的方法,就可實現該方法的功能,內部的實現原理據說是將我們之前寫的代碼進行了一層封裝,所以我們直接調用即可
3. 由於mixins里的五大工具類沒有繼承任何視圖類views,在配置url的時候沒有as_view()方法,也就是不能進行任何的增刪改查,所以寫視圖類時繼承GenericAPIView類
# 工具視圖類
from rest_framework.generics import CreateAPIView, RetrieveAPIView, ListAPIView,UpdateAPIView,DestroyAPIView
class StudentMixinAPIView(CreateAPIView,ListAPIView,RetrieveAPIView,UpdateAPIView,DestroyAPIView):
queryset = models.Sudent.objects.all()
serializer_class = serializers.StudentModelSerializer
# url中單查,不一定必須提供主鍵,提供一切唯一鍵的字段名均可
lookup_url_kwarg = 'id'
# 有刪除需求的接口繼承DestroyAPIView,重寫destroy完成字段刪除
def destroy(self, request, *args, **kwargs):
pass
分析:
lookup_url_kwarg: url中單查,不一定必須提供主鍵,提供一切唯一鍵的字段名均可,url配置中也要將pk改為id
優點:
CreateAPIView,ListAPIView,RetrieveAPIView,UpdateAPIView,DestroyAPIView這五個工具類集成了mixins與GenericAPIView裏面的類。將它們再進行一次封裝,將get,post…等方法封裝起來,我們直接繼承有該方法的類即可。
缺點:
單查與群查不能共存,按照繼承順序決定單查還是群查,下面介紹的視圖集就能完成共存。
# 視圖集
from rest_framework.viewsets import ModelViewSet
class StudentModelViewSet(ModelViewSet):
queryset = models.Sudent.objects.all()
serializer_class = serializers.StudentModelSerializer
def mypost(self, request, *args, **kwargs):
return Response('my post ok')
分析:
通過使用視圖集可以實現單查與群查共存,原因從查看源代碼得知:
ModelViewSet繼承五大工具類之外還繼承了GenericViewSet
GenericViewSet繼承了ViewSet再繼承了ViewSetMixin
而在ViewSetMixin類裏面,它重寫了as_view()方法,根據繼承關係,如果路由匹配上了,先走ViewSetMixin的as_view()方法。在它的as_view()方法裏面,它通過給給as_view()方法傳參數的方式,對應的工具方法:
它的原理就是通過給傳字典,通過字典裏面的數據進行反射,得到請求想要執行的方法。
在url路由中配置,這樣我們就可以區別單查與群查了:
我們還可以自己重寫請求要執行的對應方法。來實現特殊的需求。
注:由上面的代碼可以知道:除了繼承APIView的視圖類外,其他視圖類都要在該類下設置兩個屬性:
queryset = models.Student.objects.all() # 代表跟哪張表建立關係
serializer_class = serializers.StudentModelSerializer # 指明用的是哪個序列化器本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
目錄
我們從兩個方面來理解Java IO,數據源(流)、數據傳輸,即IO的核心就是對數據源產生的數據進行讀寫並高效傳輸的過程。
數據源可以理解為水源,指可以產生數據的事物,如硬盤(文檔、數據庫等文件…)、網絡(填寫的form表單、物聯感知信息..),在Java中有對文件及文件夾操作的類File,常用的文件方法如下:
public static void printFileDetail(File file) throws IOException {
System.out.println("文件是否存在:" + file.exists());
if(!file.exists()){
System.out.println("創建文件:" + file.getName());
file.createNewFile();
}
if(file.exists()){
System.out.println("是否為文件:" + file.isFile());
System.out.println("是否為文件夾:" + file.isDirectory());
System.out.println("文件名稱:" + file.getName());
System.out.println("文件構造路徑:" + file.getPath());
System.out.println("文件絕對路徑:" + file.getAbsolutePath());
System.out.println("文件標準路徑:" + file.getCanonicalPath());
System.out.println("文件大小:" + file.length());
System.out.println("所在文件夾路徑:" + file.getParentFile().getCanonicalPath());
System.out.println("設置為只讀文件:" + file.setReadOnly());
}
}
public static void main(String[] args) throws IOException {
File file = new File("./遮天.txt");
printFileDetail(file);
}結果如下:
文件是否存在:false
創建文件:遮天.txt
是否為文件:true
是否為文件夾:false
文件名稱:遮天.txt
文件構造路徑:.\遮天.txt
文件絕對路徑:E:\idea-work\javase-learning\.\遮天.txt
文件標準路徑:E:\idea-work\javase-learning\遮天.txt
文件大小:0
所在文件夾路徑:E:\idea-work\javase-learning
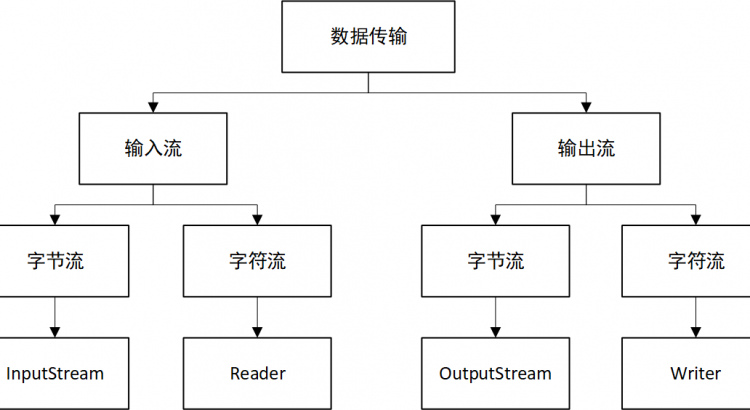
設置為只讀文件:true數據傳輸的核心在於傳輸數據源產生的數據,Java IO對此過程從兩方面進行了考慮,分別為輸入流和輸出流,輸入流完成外部數據向計算機內存寫入,輸出流則反之。
而針對輸入流和輸出流,Java IO又從字節和字符的不同,再次細分了字節流和字符流。
說明:Java中最小的計算單元是字節,沒有字符流也能進行IO操作,只是因為現實中大量的數據都是文本字符數據,基於此單獨設計了字符流,使操作更簡便。
4個頂層接口有了,接下來Java IO又從多種應用場景(包括了基礎數據類型、文件、數組、管道、打印、序列化)和傳輸效率(緩衝操作)進行了考慮,提供了種類眾多的Java IO流的實現類,看下圖:
當然我們不用都記住,而實際在使用過程中用的最多的還是文件類操作、轉換類操作、序列化操作,當然在此基礎上我們可以使用Buffered來提高效率(Java IO使用了裝飾器模式)。下面我們通過文件拷貝來簡單說明一下主要類的使用
/**
* 文件拷貝(所有文件,文檔、視頻、音頻、可執行文件...),未使用緩衝
* @param sourceFileName 源文件路徑
* @param targetFileName 拷貝后目標文件路徑
* @throws IOException IO異常
*/
public static void slowlyCopyFile(String sourceFileName, String targetFileName) throws IOException{
//獲取字節輸入流
FileInputStream fileInputStream = new FileInputStream(sourceFileName);
//File targetFile = new File(targetFileName);
//獲取字節輸出流
FileOutputStream fileOutputStream = new FileOutputStream(targetFileName);
byte[] bytes = new byte[1024];
//當為-1時說明讀取到最後一行了
while ((fileInputStream.read(bytes)) != -1) {
fileOutputStream.write(bytes);
}
fileInputStream.close();
fileOutputStream.close();
}
/**
* 文件拷貝(所有文件,文檔、視頻、音頻、可執行文件...),使用緩衝
* @param sourceFileName 源文件路徑
* @param targetFileName 拷貝后目標文件路徑
* @throws IOException IO異常
*/
public static void fastCopyFile(String sourceFileName, String targetFileName) throws IOException{
//獲取字節輸入流
FileInputStream fileInputStream = new FileInputStream(sourceFileName);
//緩衝字節輸入流
BufferedInputStream bufferedInputStream = new BufferedInputStream(fileInputStream);
//獲取字節輸出流
FileOutputStream fileOutputStream = new FileOutputStream(targetFileName);
//緩衝字節輸出流
BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(fileOutputStream);
byte[] bytes = new byte[1024];
//當為-1時說明讀取到最後一行了
while ((bufferedInputStream.read(bytes)) != -1) {
bufferedOutputStream.write(bytes);
}
bufferedOutputStream.flush();
bufferedInputStream.close();
fileInputStream.close();
bufferedOutputStream.close();
fileOutputStream.close();
}
public static void main(String[] args) throws IOException {
long startTime = System.currentTimeMillis();
//文件215M
slowlyCopyFile("D:\\Download\\jdk-8u221.exe","D:\\jdk-8u221.exe");//執行:1938ms
fastCopyFile("D:\\Download\\jdk-8u221.exe","D:\\jdk-8u221.exe");//執行:490ms
System.out.println(System.currentTimeMillis() - startTime);
} /**
* 文本文件拷貝,不使用緩衝
* @param sourceFileName 源文件路徑
* @param targetFileName 拷貝后目標文件路徑
* @throws IOException IO異常
*/
public static void slowlyCopyTextFile(String sourceFileName, String targetFileName) throws IOException {
FileReader fileReader = new FileReader(sourceFileName);
FileWriter fileWriter = new FileWriter(targetFileName);
int c;
while ((c = fileReader.read()) != -1) {
fileWriter.write((char)c);
}
fileReader.close();
fileWriter.close();
}
/**
* 文本文件拷貝,使用緩衝
* @param sourceFileName 源文件路徑
* @param targetFileName 拷貝后目標文件路徑
* @throws IOException IO異常
*/
public static void fastCopyTextFile(String sourceFileName, String targetFileName) throws IOException {
FileReader fileReader = new FileReader(sourceFileName);
BufferedReader bufferedReader = new BufferedReader(fileReader);
FileWriter fileWriter = new FileWriter(targetFileName);
BufferedWriter bufferedWriter = new BufferedWriter(fileWriter);
String str;
while ((str = bufferedReader.readLine()) != null) {
bufferedWriter.write(str + "\n");
}
bufferedReader.close();
fileReader.close();
bufferedWriter.close();
fileWriter.close();
}
public static void main(String[] args) throws IOException {
long startTime = System.currentTimeMillis();
//文件30M
slowlyCopyTextFile("D:\\Download\\小說合集.txt","D:\\小說合集.txt");//3182ms
fastCopyTextFile("D:\\Download\\小說合集.txt","D:\\小說合集.txt");//1583ms
System.out.println(System.currentTimeMillis() - startTime);
}本文主要對Java IO相關知識點做了結構性梳理,包括了Java IO的作用,數據源File類,輸入流,輸出流,字節流,字符流,以及緩衝流,不同場景下的更細化的流操作類型,同時用了一個文件拷貝代碼簡單地說明了主要的流操作,若有不對之處,請批評指正,望共同進步,謝謝!。
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選

 |
結合智慧能源與智慧交通的新創科技品牌Gogoro(睿能創意股份有限公司)7 日公布全台建置與營運中的GoStation 電池交換站已達400 站,再度創造新的里程碑。從2015 年7 月至今,Gogoro 在基隆到屏東的台灣西半部地區,平均每1.8 天即新增一座電池交換站,最近一個月,每日提供將近4 萬名車主接近17,000 顆的電池交換服務,電池交換服務已經成為台灣消費者購買電動機車時的首要選擇。
自從Gogoro 於2015 年在台北市設立首座電池交換站以來,在短短兩年多的時間,建置了400 座電池交換站,廣布於基隆到屏東的各個縣市,推升Gogoro 電動機車市佔率至85.1%,並穩居台灣機車市場第四名的寶座。在今年7 月開通雲嘉地區電池交換站後,暢騎台灣西半部,不再是夢想。同時六都的電池交換站建置更來到一公里一站。
Gogoro 行銷總監陳彥揚說:「我們會依據人口密集度、車輛密極度以及道路的重要性來建置及調度電池交換站。根據車主換電的大數據分析,換電最密集的電池交換站位於Gogoro 永和中正店,而換電的尖峰時刻不外乎是上、下班的時間。有趣的是,雖然全台已經有將近400 座電池交換站,但每名消費者平均只會造訪其中的3-4 站來更換電池。證明Gogoro 能源網路的大數據分析,能計算出消費者換電池的使用行為模式,滿足車主們的需求。」
走在環保、綠能尖端的Gogoro,目前共建置了兩座太陽能換電站,分別是八里公兒四電池交換站和Gogoro 師大和平店站,這兩站設有物聯網智慧平台,透過分析供電情況的螢幕,說明了包括減少碳排量、減少樹木砍伐面積、綠能總儲電量、城市電網和太陽能發電量等訊息,讓每名換電的民眾,清楚的知道,自己對環境的貢獻度。
陳彥揚說:「Gogoro 致力發展潔淨的智慧能源,希望具備能源調度能力的智慧電網,能成為城市的電力調節樞紐,以促成電力平衡。對於Gogoro 車主而言,Gogoro 不再僅是都會的通勤工具,而是更進一步深入使用者的生活,同時讓生活環境更環保、更健康。」
Gogoro 目前擁有近4 萬名車主,總共累積超過570 萬次的電池交換,總里程數超過1 億100 公里,已經替地球減少將近840 萬公斤的二氧化碳排放,隨著未來再生能源比例逐漸提升,Gogoro 的車主們將更對地球與環境產生更多正面的影響力。而Gogoro 更會透過大數據進行科學的規劃,以調控電池供應,未來,即便新增的萬名車主同步上路,也能確保能源及電池的調配無虞。
(合作媒體:。圖片出處:科技新報)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※帶您來了解什麼是 USB CONNECTOR ?
※自行創業 缺乏曝光? 下一步"網站設計"幫您第一時間規劃公司的門面形象
※如何讓商品強力曝光呢? 網頁設計公司幫您建置最吸引人的網站,提高曝光率!!
※綠能、環保無空污,成為電動車最新代名詞,目前市場使用率逐漸普及化
※廣告預算用在刀口上,網站設計公司幫您達到更多曝光效益
隨著汽車產業的變革,新能源汽車時代已經到來,同時更具顛覆性的智慧汽車也在加速發展,汽車設計中的輕量化也成為了行業重要課題之一,這些都對整個行業的關鍵技術創新提出了更高的要求。中國新能源汽車產業已進入規模化發展新階段及政策和市場共同驅動的快速成長期,而智慧汽車也將引領智慧交通進入一個新的發展階段,智慧汽車已經超越了汽車的概念,是一種智慧出行工具的理念,隨著節能減排的深入人心及政策導向,汽車設計輕量化成為了節能減排的重要途徑之一。2017全球新能源智慧汽車大會將進行一次全面行業熱點方向及最新技術的分享。
2017全球新能源智慧汽車大會(第二屆上海– 斯圖加特汽車及動力技術國際研討會SSSAET)是由上海市人民政府、德國巴登符騰堡州政府、上海市嘉定區人民政府指導,同濟大學和斯圖加特大學主辦,上海車犇資訊技術有限公司承辦的大型會議,將於2017年的10月26-27日在上海隆重舉行。會議主要分為“智慧汽車,新能源汽車,整車設計” 三個主題方向,由六大主題分論壇組成,分別為“燃料電池,動力電池,電驅動,智慧網聯,汽車設計,汽車輕量化”。
兩天大會將會邀請來自相關政府機構嘉賓,國內外40+所著名汽車研究機構,學者,整車廠,零部件廠商參與研討,演講嘉賓由2位院士及43位國內外重量級演講嘉賓強大陣容組成(已有36位嘉賓確認,其中外籍為16位),聚集500+位的國內外行業精英參與討論。且本次會議將在投稿件中,精選40篇品質較高的優秀學術論文在同濟大學學報增刊上發表。
大會亮點:
※最高演講規模: 2位院士,43位國內外重量級演講嘉賓
※最高演講嘉賓確認率:已確認36位,外籍專家16位
※最具權威和專業性:40篇論文,100%EI檢索
※最大規模之一:500+行業人員蒞臨;80+主機廠整車商專業人士參與
※最全最新議題:3大論壇6大熱點主題全覆蓋
2017全球新能源智慧汽車大會(第二屆上海– 斯圖加特汽車及動力技術國際研討會)期待您的參與!如需更多會議資訊請聯繫:
連絡人: Latika LIU(劉小姐)
電話:021 6093 0815
郵箱:
網站: www.sssaet.com
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※為什麼 USB CONNECTOR 是電子產業重要的元件?
※網頁設計一頭霧水??該從何著手呢? 找到專業技術的網頁設計公司,幫您輕鬆架站!
※想要讓你的商品成為最夯、最多人討論的話題?網頁設計公司讓你強力曝光
※想知道最厲害的台北網頁設計公司推薦、台中網頁設計公司推薦專業設計師”嚨底家”!!
我在看SOFAJRaft的源碼的時候看到了使用了對象池的技術,看了一下感覺要吃透的話還是要新開一篇文章來講,內容也比較充實,大家也可以學到之後運用到實際的項目中去。
這裏我使用RecyclableByteBufferList來作為講解的例子:
RecyclableByteBufferList
public final class RecyclableByteBufferList extends ArrayList<ByteBuffer> implements Recyclable {
private transient final Recyclers.Handle handle;
private static final Recyclers<RecyclableByteBufferList> recyclers = new Recyclers<RecyclableByteBufferList>(512) {
@Override
protected RecyclableByteBufferList newObject(final Handle handle) {
return new RecyclableByteBufferList(
handle);
}
};
//獲取一個RecyclableByteBufferList實例
public static RecyclableByteBufferList newInstance(final int minCapacity) {
final RecyclableByteBufferList ret = recyclers.get();
//容量不夠的話,進行擴容
ret.ensureCapacity(minCapacity);
return ret;
}
//回收RecyclableByteBufferList對象
@Override
public boolean recycle() {
clear();
this.capacity = 0;
return recyclers.recycle(this, handle);
}
}我在上面將RecyclableByteBufferList獲取對象的方法和回收對象的方法給列舉出來了,獲取實例的時候會通過recyclers的get方法去獲取,回收對象的時候會去調用list的clear方法清空list裏面的內容之後再去調用recyclers的recycle方法進行回收。
如果recyclers裏面沒有對象可以獲取,那麼會調用newObject方法創建一個對象,然後將handle對象傳入構造器中進行實例化。
ThreadLocal<Stack<T>> threadLocal實例;ThreadLocal<Map<Stack<?>, WeakOrderQueue>> delayedRecycled實例;假設線程A創建的對象
Recyclers靜態代碼塊
private static final int DEFAULT_INITIAL_MAX_CAPACITY_PER_THREAD = 4 * 1024; // Use 4k instances as default.
private static final int DEFAULT_MAX_CAPACITY_PER_THREAD;
private static final int INITIAL_CAPACITY;
static {
// 每個線程的最大對象池容量
int maxCapacityPerThread = SystemPropertyUtil.getInt("jraft.recyclers.maxCapacityPerThread", DEFAULT_INITIAL_MAX_CAPACITY_PER_THREAD);
if (maxCapacityPerThread < 0) {
maxCapacityPerThread = DEFAULT_INITIAL_MAX_CAPACITY_PER_THREAD;
}
DEFAULT_MAX_CAPACITY_PER_THREAD = maxCapacityPerThread;
if (LOG.isDebugEnabled()) {
if (DEFAULT_MAX_CAPACITY_PER_THREAD == 0) {
LOG.debug("-Djraft.recyclers.maxCapacityPerThread: disabled");
} else {
LOG.debug("-Djraft.recyclers.maxCapacityPerThread: {}", DEFAULT_MAX_CAPACITY_PER_THREAD);
}
}
// 設置初始化容量信息
INITIAL_CAPACITY = Math.min(DEFAULT_MAX_CAPACITY_PER_THREAD, 256);
}
public static final Handle NOOP_HANDLE = new Handle() {};Recyclers會在靜態代碼塊中做一些對象池容量初始化的工作,初始化了最大對象池容量和初始化容量信息。
Recyclers#get
// 線程變量,保存每個線程的對象池信息,通過 ThreadLocal 的使用,避免了不同線程之間的競爭情況
private final ThreadLocal<Stack<T>> threadLocal = new ThreadLocal<Stack<T>>() {
@Override
protected Stack<T> initialValue() {
return new Stack<>(Recyclers.this, Thread.currentThread(), maxCapacityPerThread);
}
};
public final T get() {
if (maxCapacityPerThread == 0) {
return newObject(NOOP_HANDLE);
}
//從threadLocal中獲取一個棧對象
Stack<T> stack = threadLocal.get();
//拿出棧頂元素
DefaultHandle handle = stack.pop();
//如果棧裏面沒有元素,那麼就實例化一個
if (handle == null) {
handle = stack.newHandle();
handle.value = newObject(handle);
}
return (T) handle.value;
}Get方法會從threadLocal中去獲取數據,如果獲取不到,那麼會初始化一個Stack,並傳入當前Recyclers實例,當前線程,與最大容量。然後從stack中pop拿出棧頂元素,如果獲取的元素為空,那麼直接調用newHandle新建一個DefaultHandle實例,並調用Recyclers實現類的newObject獲取實現類的實例。也就是說DefaultHandle是用來封裝真正的對象的實例。
從stack中申請一個對象
Stack(Recyclers<T> parent, Thread thread, int maxCapacity) {
this.parent = parent;
this.thread = thread;
this.maxCapacity = maxCapacity;
elements = new DefaultHandle[Math.min(INITIAL_CAPACITY, maxCapacity)];
}
DefaultHandle pop() {
int size = this.size;
if (size == 0) {
if (!scavenge()) {
return null;
}
size = this.size;
}
//size表示整個stack中的大小
size--;
//獲取最後一個元素
DefaultHandle ret = elements[size];
if (ret.lastRecycledId != ret.recycleId) {
throw new IllegalStateException("recycled multiple times");
}
// 清空回收信息,以便判斷是否重複回收
ret.recycleId = 0;
ret.lastRecycledId = 0;
this.size = size;
return ret;
}獲取對象的邏輯也比較簡單,當 Stack 中的 DefaultHandle[] 的 size 為 0 時,需要從其他線程的 WeakOrderQueue 中轉移數據到 Stack 中的 DefaultHandle[],即 scavenge方法,該方法下面再聊。當 Stack 中的 DefaultHandle[] 中最終有了數據時,直接獲取最後一個元素
我們再來看看RecyclableByteBufferList是怎麼回收對象的。
RecyclableByteBufferList#recycle
public boolean recycle() {
clear();
this.capacity = 0;
return recyclers.recycle(this, handle);
}RecyclableByteBufferList回收對象的時候首先會調用clear方法清空屬性,然後調用recyclers的recycle方法進行對象回收。
Recyclers#recycle
public final boolean recycle(T o, Handle handle) {
if (handle == NOOP_HANDLE) {
return false;
}
DefaultHandle h = (DefaultHandle) handle;
//stack在實例化的時候會在構造器中傳入一個Recyclers作為parent
//所以這裡是校驗一下,如果不是當前線程的, 直接不回收了
if (h.stack.parent != this) {
return false;
}
if (o != h.value) {
throw new IllegalArgumentException("o does not belong to handle");
}
h.recycle();
return true;
}這裡會接着調用DefaultHandle的recycle方法進行回收
DefaultHandle
static final class DefaultHandle implements Handle {
//在WeakOrderQueue的add方法中會設置成ID
//在push方法中設置成為OWN_THREAD_ID
//在pop方法中設置為0
private int lastRecycledId;
//只有在push方法中才會設置OWN_THREAD_ID
//在pop方法中設置為0
private int recycleId;
//當前的DefaultHandle對象所屬的Stack
private Stack<?> stack;
private Object value;
DefaultHandle(Stack<?> stack) {
this.stack = stack;
}
public void recycle() {
Thread thread = Thread.currentThread();
//如果當前線程正好等於stack所對應的線程,那麼直接push進去
if (thread == stack.thread) {
stack.push(this);
return;
}
// we don't want to have a ref to the queue as the value in our weak map
// so we null it out; to ensure there are no races with restoring it later
// we impose a memory ordering here (no-op on x86)
// 如果不是當前線程,則需要延遲回收,獲取當前線程存儲的延遲回收WeakHashMap
Map<Stack<?>, WeakOrderQueue> delayedRecycled = Recyclers.delayedRecycled.get();
// 當前 handler 所在的 stack 是否已經在延遲回收的任務隊列中
// 並且 WeakOrderQueue是一個多線程間可以共享的Queue
WeakOrderQueue queue = delayedRecycled.get(stack);
if (queue == null) {
delayedRecycled.put(stack, queue = new WeakOrderQueue(stack, thread));
}
queue.add(this);
}
}DefaultHandle在實例化的時候會傳入一個stack實例,代表當前實例是屬於這個stack的。
所以在調用recycle方法的時候,會判斷一下,當前的線程是不是stack所屬的線程,如果是那麼直接push到stack裏面就好了,不是則調用延遲隊列delayedRecycled;
從delayedRecycled隊列中獲取Map<Stack<?>, WeakOrderQueue> delayedRecycled ,根據stack作為key來獲取WeakOrderQueue,然後將當前的DefaultHandle實例放入到WeakOrderQueue中。
Stack#push
void push(DefaultHandle item) {
// (item.recycleId | item.lastRecycleId) != 0 等價於 item.recycleId!=0 && item.lastRecycleId!=0
// 當item開始創建時item.recycleId==0 && item.lastRecycleId==0
// 當item被recycle時,item.recycleId==x,item.lastRecycleId==y 進行賦值
// 當item被pop之後, item.recycleId = item.lastRecycleId = 0
// 所以當item.recycleId 和 item.lastRecycleId 任何一個不為0,則表示回收過
if ((item.recycleId | item.lastRecycledId) != 0) {
throw new IllegalStateException("recycled already");
}
// 設置對象的回收id為線程id信息,標記自己的被回收的線程信息
item.recycleId = item.lastRecycledId = OWN_THREAD_ID;
int size = this.size;
if (size >= maxCapacity) {
// Hit the maximum capacity - drop the possibly youngest object.
return;
}
// stack中的elements擴容兩倍,複製元素,將新數組賦值給stack.elements
if (size == elements.length) {
elements = Arrays.copyOf(elements, Math.min(size << 1, maxCapacity));
}
elements[size] = item;
this.size = size + 1;
}同線程回收對象 DefaultHandle#recycle 步驟:
WeakOrderQueue
static final class Stack<T> {
//使用volatile可以立即讀取到該queue
private volatile WeakOrderQueue head;
}
WeakOrderQueue(Stack<?> stack, Thread thread) {
head = tail = new Link();
//使用的是WeakReference ,作用是在poll的時候,如果owner不存在了
// 則需要將該線程所包含的WeakOrderQueue的元素釋放,然後從鏈表中刪除該Queue。
owner = new WeakReference<>(thread);
//假設線程B和線程C同時回收線程A的對象時,有可能會同時創建一個WeakOrderQueue,就坑同時設置head,所以這裏需要加鎖
synchronized (stackLock(stack)) {
next = stack.head;
stack.head = this;
}
}創建WeakOrderQueue對象的時候會初始化一個WeakReference的owner,作用是在poll的時候,如果owner不存在了, 則需要將該線程所包含的WeakOrderQueue的元素釋放,然後從鏈表中刪除該Queue。
然後給stack加鎖,假設線程B和線程C同時回收線程A的對象時,有可能會同時創建一個WeakOrderQueue,就坑同時設置head,所以這裏需要加鎖。
以head==null的時候為例
加鎖:
線程B先執行,則head = 線程B的queue;之後線程C執行,此時將當前的head也就是線程B的queue作為線程C的queue的next,組成鏈表,之後設置head為線程C的queue
不加鎖:
線程B先執行 next = stack.head此時線程B的queue.next=null->線程C執行next = stack.head;線程C的queue.next=null-> 線程B執行stack.head = this;設置head為線程B的queue -> 線程C執行stack.head = this;設置head為線程C的queue,此時線程B和線程C的queue沒有連起來。
WeakOrderQueue#add
void add(DefaultHandle handle) {
// 設置handler的最近一次回收的id信息,標記此時暫存的handler是被誰回收的
handle.lastRecycledId = id;
Link tail = this.tail;
int writeIndex;
// 判斷一個Link對象是否已經滿了:
// 如果沒滿,直接添加;
// 如果已經滿了,創建一個新的Link對象,之後重組Link鏈表,然後添加元素的末尾的Link(除了這個Link,前邊的Link全部已經滿了)
if ((writeIndex = tail.get()) == LINK_CAPACITY) {
this.tail = tail = tail.next = new Link();
writeIndex = tail.get();
}
tail.elements[writeIndex] = handle;
// 如果使用者在將DefaultHandle對象壓入隊列后,將Stack設置為null
// 但是此處的DefaultHandle是持有stack的強引用的,則Stack對象無法回收;
//而且由於此處DefaultHandle是持有stack的強引用,WeakHashMap中對應stack的WeakOrderQueue也無法被回收掉了,導致內存泄漏
handle.stack = null;
// we lazy set to ensure that setting stack to null appears before we unnull it in the owning thread;
// this also means we guarantee visibility of an element in the queue if we see the index updated
// tail本身繼承於AtomicInteger,所以此處直接對tail進行+1操作
tail.lazySet(writeIndex + 1);
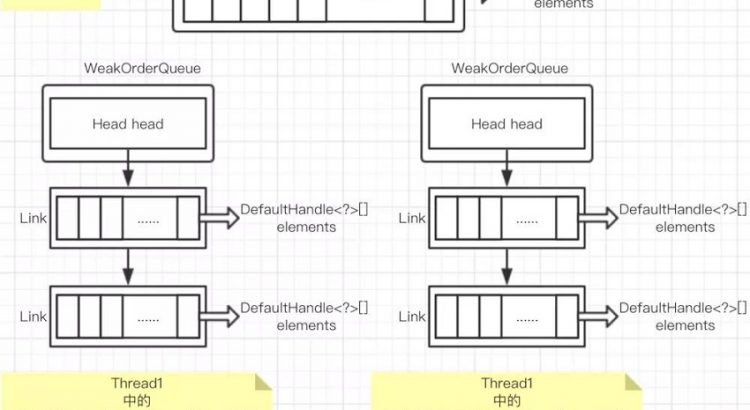
}Stack異線程push對象流程:
WeakOrderQueue 的創建流程:
WeakOrderQueue#add添加對象流程
我再把pop方法搬下來一次:
DefaultHandle pop() {
int size = this.size;
// size=0 則說明本線程的Stack沒有可用的對象,先從其它線程中獲取。
if (size == 0) {
// 當 Stack<T> 此時的容量為 0 時,去 WeakOrder 中轉移部分對象到 Stack 中
if (!scavenge()) {
return null;
}
//由於在transfer(Stack<?> dst)的過程中,可能會將其他線程的WeakOrderQueue中的DefaultHandle對象傳遞到當前的Stack,
//所以size發生了變化,需要重新賦值
size = this.size;
}
//size表示整個stack中的大小
size--;
//獲取最後一個元素
DefaultHandle ret = elements[size];
if (ret.lastRecycledId != ret.recycleId) {
throw new IllegalStateException("recycled multiple times");
}
// 清空回收信息,以便判斷是否重複回收
ret.recycleId = 0;
ret.lastRecycledId = 0;
this.size = size;
return ret;
}Stack#scavenge
boolean scavenge() {
// continue an existing scavenge, if any
// 掃描判斷是否存在可轉移的 Handler
if (scavengeSome()) {
return true;
}
// reset our scavenge cursor
prev = null;
cursor = head;
return false;
}調用scavengeSome掃描判斷是否存在可轉移的 Handler,如果沒有,那麼就返回false,表示沒有可用對象
Stack#scavengeSome
boolean scavengeSome() {
WeakOrderQueue cursor = this.cursor;
if (cursor == null) {
cursor = head;
// 如果head==null,表示當前的Stack對象沒有WeakOrderQueue,直接返回
if (cursor == null) {
return false;
}
}
boolean success = false;
WeakOrderQueue prev = this.prev;
do {
// 從當前的WeakOrderQueue節點進行 handler 的轉移
if (cursor.transfer(this)) {
success = true;
break;
}
// 遍歷下一個WeakOrderQueue
WeakOrderQueue next = cursor.next;
// 如果 WeakOrderQueue 的實際持有線程因GC回收了
if (cursor.owner.get() == null) {
// If the thread associated with the queue is gone, unlink it, after
// performing a volatile read to confirm there is no data left to collect.
// We never unlink the first queue, as we don't want to synchronize on updating the head.
// 如果當前的WeakOrderQueue的線程已經不可達了
//如果該WeakOrderQueue中有數據,則將其中的數據全部轉移到當前Stack中
if (cursor.hasFinalData()) {
for (;;) {
if (cursor.transfer(this)) {
success = true;
} else {
break;
}
}
}
//將當前的WeakOrderQueue的前一個節點prev指向當前的WeakOrderQueue的下一個節點,
// 即將當前的WeakOrderQueue從Queue鏈表中移除。方便後續GC
if (prev != null) {
prev.next = next;
}
} else {
prev = cursor;
}
cursor = next;
} while (cursor != null && !success);
this.prev = prev;
this.cursor = cursor;
return success;
} boolean transfer(Stack<?> dst) {
//尋找第一個Link
Link head = this.head;
// head == null,沒有存儲數據的節點,直接返回
if (head == null) {
return false;
}
// 讀指針的位置已經到達了每個 Node 的存儲容量,如果還有下一個節點,進行節點轉移
if (head.readIndex == LINK_CAPACITY) {
//判斷當前的Link節點的下一個節點是否為null,如果為null,說明已經達到了Link鏈表尾部,直接返回,
if (head.next == null) {
return false;
}
// 否則,將當前的Link節點的下一個Link節點賦值給head和this.head.link,進而對下一個Link節點進行操作
this.head = head = head.next;
}
// 獲取Link節點的readIndex,即當前的Link節點的第一個有效元素的位置
final int srcStart = head.readIndex;
// 獲取Link節點的writeIndex,即當前的Link節點的最後一個有效元素的位置
int srcEnd = head.get();
// 本次可轉移的對象數量(寫指針減去讀指針)
final int srcSize = srcEnd - srcStart;
if (srcSize == 0) {
return false;
}
// 獲取轉移元素的目的地Stack中當前的元素個數
final int dstSize = dst.size;
// 計算期盼的容量
final int expectedCapacity = dstSize + srcSize;
// 期望的容量大小與實際 Stack 所能承載的容量大小進行比對,取最小值
if (expectedCapacity > dst.elements.length) {
final int actualCapacity = dst.increaseCapacity(expectedCapacity);
srcEnd = Math.min(srcStart + actualCapacity - dstSize, srcEnd);
}
if (srcStart != srcEnd) {
// 獲取Link節點的DefaultHandle[]
final DefaultHandle[] srcElems = head.elements;
// 獲取目的地Stack的DefaultHandle[]
final DefaultHandle[] dstElems = dst.elements;
// dst數組的大小,會隨着元素的遷入而增加,如果最後發現沒有增加,那麼表示沒有遷移成功任何一個元素
int newDstSize = dstSize;
//// 進行對象轉移
for (int i = srcStart; i < srcEnd; i++) {
DefaultHandle element = srcElems[i];
// 表明自己還沒有被任何一個 Stack 所回收
if (element.recycleId == 0) {
element.recycleId = element.lastRecycledId;
// 避免對象重複回收
} else if (element.recycleId != element.lastRecycledId) {
throw new IllegalStateException("recycled already");
}
// 將可轉移成功的DefaultHandle元素的stack屬性設置為目的地Stack
element.stack = dst;
// 將DefaultHandle元素轉移到目的地Stack的DefaultHandle[newDstSize ++]中
dstElems[newDstSize++] = element;
// 設置為null,清楚暫存的handler信息,同時幫助 GC
srcElems[i] = null;
}
// 將新的newDstSize賦值給目的地Stack的size
dst.size = newDstSize;
if (srcEnd == LINK_CAPACITY && head.next != null) {
// 將Head指向下一個Link,也就是將當前的Link給回收掉了
// 假設之前為Head -> Link1 -> Link2,回收之後為Head -> Link2
this.head = head.next;
}
// 設置讀指針位置
head.readIndex = srcEnd;
return true;
} else {
// The destination stack is full already.
return false;
}
}
}本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
2017年11月16-17日∣中國·上海
人–車–路協同發展創造全面感知新時代
隨著電子、資訊、通信、人工智慧等技術與汽車產業加速融合,汽車產品正加快向智慧化、網聯化方向發展。因此,智慧網聯汽車面臨的資訊安全挑戰也備受業界關注。
頂層設計政策體系為智慧網聯汽車的發展創建了良好的發展環境,與此相關的大資料、雲計算、人工智慧等也在持續提供著技術保障。與此同時,一個較為顯著的問題是,汽車的網聯化也極有可能徹底打開了駭客入侵智慧網聯汽車的通道。智慧網聯汽車與外部的每個介面都可能被惡意利用,每個控制單元都可能被駭客攻擊、病毒感染,智慧網聯汽車的資訊安全防護難度也因之而倍增。
第二屆中國國際智慧網聯汽車論壇將針對智慧網聯汽車資訊安全問題定向邀請包括騰訊科恩實驗室,360奇虎,梆梆安全,中國移動,中國聯通等行業內權威人士對於車聯網資訊安全問題進行更深層次的解析。此次論壇將涉及3個論壇,參觀考察及晚宴,共將有300位行業人士一起,對智慧網聯汽車發展面臨的挑戰、機遇與對策各方面進行為期兩天更深層次並具有建設和戰略性的探討。
會議亮點
Ø 豐富的內容:3大論壇的深度解析
Ø 參會嘉賓:300+高度滿意的企業決策者,160+業內知名企業,40+國家和地區
Ø 演講嘉賓:30+世界新能源汽車行業知名發言嘉賓
Ø 會議形式:3個論壇,2天會議,1個晚宴
會議結構
|
論壇一:智慧網聯汽車發展趨勢分析及國內外項目解析和智慧交通發展 |
|
論壇二:車載通訊資訊技術及車聯網未來發展 |
|
² 迎合中國製造2025,促進智慧網聯汽車發展之路 ² 智慧汽車、車聯網、車載資訊服務:點、線、網、面的格局與階段 ² 智慧汽車技術創新革命 ² 智慧交通/汽車發展不同階段的分析 ² 國際智慧交通與智慧駕駛的銜接發展 |
|
² 車載半導體的機遇與挑戰 ² 車聯網最新技術探討 ² 4G通信在車載行業的應用 ² 分時租賃-建造全民共用汽車 ² 移動互聯網運營與智慧汽車的融合 |
|
論壇三:智慧汽車ADAS駕駛輔助系統和智慧駕駛技術 |
|
考察活動:2017年11月15日 |
|
² ADAS與智慧駕駛解決方案探討 ² ADAS駕駛輔助系統性能及匹配測試 ² 駕駛輔助系統雷達與感測器的核心技術 ² 高精准地圖對於智慧駕駛的重要性 ² 汽車人機交互對於智慧駕駛的重要性及發展展望 |
|
1.參觀上海天合汽車安全系統有限公司 2.參觀上海智慧網聯汽車試點示範區-中國首家(已預訂,如無測試企業屆時即可參觀) |
若您對峰會有更多要求,請撥打021-6093 0815與我們聯繫,謝謝理解和支持!
我們期待與貴單位一起出席於2017年11月16日-17日在上海舉辦的第二屆中國國際智慧網聯汽車論壇2017,以利決策!
欲知更多會議詳情,請登陸官方網站:http://www.ourpolaris.com/2017/icv/index_c.html
連絡人:Latika LIU(劉小姐)
電話:021-6093 0815
傳真:021-6047 5887
郵箱:
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※USB CONNECTOR掌控什麼技術要點? 帶您認識其相關發展及效能
※評比前十大台北網頁設計、台北網站設計公司知名案例作品心得分享
※智慧手機時代的來臨,RWD網頁設計已成為網頁設計推薦首選

 |
新華社9日報導,中國工信部副部長辛國斌表示,一些國家已經制定了停止生產銷售傳統能源汽車的時間表。他說,目前工信部也啟動了相關研究、將會同相關部門制定中國的時間表。
報導指出,從現在到2025年將是汽車產業變革最為劇烈的幾年,傳統汽車節能減排要求越來越高,新能源汽車發展加快的同時對技術要求也越來越高,智能聯網將對整個產業巨大影響。辛國斌及專家建議中國車企應深刻認識這種趨勢、及時調整策略。
Thomson Reuters上個月底引述消息人士報導,根據最新提案,明年底中國境內車商8%銷售必須是電動車或油電混合車種、2019年升至10%、2020年升至12%。報導指出,這項規定預計將自2019年起開始落實執行、較原先規劃晚一年。
英國跟隨法國以及馬德里、墨西哥城和雅典等城市的抗空汙腳步,7月宣布將自2040年起禁止販售汽油和柴油新車。英國最大汽車製造商Jaguar Land Rover(JLR)9月7日宣布,2020年起旗下所有新車都將具備電動或油電混合驅動選項。德國車廠BMW也宣布將自2020年起開始量產電動車、預估到2025年將有12種純電動車款。
BBC News 10日報導,上述最新消息將對中國石油需求帶來連鎖效應。中國目前是全球第二大石油消費國。依據目前的規劃,中國希望在2025年將電動車/油電混合車銷售佔比至少拉升至五分之一。
根據DNV GL首度發布的「能源轉型展望」報告,受電動車滲透率持續上揚的影響,石油供應將在2020-2028年期間轉趨持平、隨後大幅下降,2034年將遭天然氣超越。
這份報告預估電動車、內燃引擎車將在2022年達到「成本平價」,預估到2033年全球半數輕型新車銷售量都將是電動車。
(本文內容由授權使用。圖片出處:public domain CC0)
本站聲明:網站內容來源於EnergyTrend https://www.energytrend.com.tw/ev/,如有侵權,請聯繫我們,我們將及時處理
【其他文章推薦】
※台北網頁設計公司這麼多,該如何挑選?? 網頁設計報價省錢懶人包"嚨底家"
※網頁設計公司推薦更多不同的設計風格,搶佔消費者視覺第一線
※想知道購買電動車哪裡補助最多?台中電動車補助資訊懶人包彙整
序言(廢話) : 在看書的過程中發現一開始不是很能理解pmtest8的目的,以及書上說得很抽象..於是在自己閱讀過源代碼后,將一些自己的心得寫在這裏。
正文 :
講解順序依然按照書上貼代碼的順序來。但是是幾乎逐句解釋的。可能會稍微有點啰嗦。廢話就不多說了直接貼代碼。
LABEL_DESC_FLAT_C: Descriptor 0, 0fffffh, DA_CR|DA_32|DA_LIMIT_4K; 0~4G LABEL_DESC_FLAT_RW: Descriptor 0, 0fffffh, DA_DRW|DA_LIMIT_4K ; 0~4G SelectorFlatC equ LABEL_DESC_FLAT_C - LABEL_GDT SelectorFlatRW equ LABEL_DESC_FLAT_RW - LABEL_GDT
顯然,兩個分別是 FLAT_C 和 FLAT_RW 的描述符和選擇子。
問題 : 為什麼要有這兩個東西?
解釋 : FLAT_C是用來執行的非一致性32位代碼段,粒度為4k,也就是 limit(段限長) = (0xfffff + 1) * 4k = 4G,FLAT_RW 是用來修改數據的,因為需要利用這個描述符的權限(可寫)來將代碼寫入到目的地(這個目的地允許在 0 – 4G區間內)。之所以要分兩個選擇符,是防止在執行的時候修改代碼(所以FLAT_C不能給寫的權限),但是又必須在執行之前進行複製,所以一定要有一個入口能提供寫入的方式,於是設置兩個描述符來進行。這樣既安全又有章法。
SetupPaging: ; 根據內存大小計算應初始化多少PDE以及多少頁表 xor edx, edx mov eax, [dwMemSize] mov ebx, 400000h ; 400000h = 4M = 4096 * 1024, 一個頁表對應的內存大小 div ebx mov ecx, eax ; 此時 ecx 為頁表的個數,也即 PDE 應該的個數 test edx, edx jz .no_remainder inc ecx ; 如果餘數不為 0 就需增加一個頁表 .no_remainder: mov [PageTableNumber], ecx ; 暫存頁表個數 ; 為簡化處理, 所有線性地址對應相等的物理地址. 並且不考慮內存空洞. ; 首先初始化頁目錄 mov ax, SelectorFlatRW mov es, ax mov edi, PageDirBase0 ; 此段首地址為 PageDirBase0 xor eax, eax mov eax, PageTblBase0 | PG_P | PG_USU | PG_RWW .1: ; es:edi 初始等於 PageDirBase0 (當前頁目錄表項), eax 初始基地址等於 PageTblBase0 stosd add eax, 4096 ; 為了簡化, 所有頁表在內存中是連續的. loop .1 ; 再初始化所有頁表 mov eax, [PageTableNumber] ; 頁表個數 mov ebx, 1024 ; 每個頁表 1024 個 PTE mul ebx mov ecx, eax ; PTE個數 = 頁表個數 * 1024 mov edi, PageTblBase0 ; 此段首地址為 PageTblBase0 xor eax, eax mov eax, PG_P | PG_USU | PG_RWW .2: ; es:edi 初始等於 PageTblBase0 (當前頁表項), eax = 0 (線性地址 = 物理地址) stosd add eax, 4096 ; 每一頁指向 4K 的空間 loop .2 mov eax, PageDirBase0 mov cr3, eax mov eax, cr0 or eax, 80000000h mov cr0, eax jmp short .3 .3: nop ret
這段代碼我加註了兩句註釋 分別在 .1 和 .2 這兩個標籤那行,其實這裏和之前的setPaging並沒有很大的區別,需要注意的就是 這裏的 頁目錄表 的地址是 PageDirBase0, 頁表的地址是PageTblBase0,強調這點的原因在於之後的 PSwitch 這個函數中則是 PageDirBase1 和 PageTblBase1。也就是說實際上數據中有兩個頁面管理的數據結構(頁目錄表和頁表合起來相當於一個管理頁面的數據結構)。
1 PagingDemo: 2 mov ax, cs 3 mov ds, ax 4 mov ax, SelectorFlatRW ; 設置es為基地址為0的可讀寫的段(便於複製代碼) 5 mov es, ax 6 7 push LenFoo 8 push OffsetFoo 9 push ProcFoo ; 00401000h 10 call MemCpy 11 add esp, 12 12 13 push LenBar ; 被複制代碼段(但是以ds為段基址)的長度 14 push OffsetBar ; 被複制代碼段(但是以ds為段基址)的段偏移量 15 push ProcBar ; 目的代碼段的物理空間地址 00501000h 16 call MemCpy 17 add esp, 12 18 19 push LenPagingDemoAll 20 push OffsetPagingDemoProc 21 push ProcPagingDemo ; [es:ProcPagingDemo] = ProcPagingDemo = 00301000h 22 call MemCpy 23 add esp, 12 24 25 mov ax, SelectorData 26 mov ds, ax ; 數據段選擇子 27 mov es, ax 28 29 call SetupPaging ; 啟動分頁 30 ; 當前線性地址依然等於物理地址 31 call SelectorFlatC:ProcPagingDemo ; 訪問的線性地址為 00301000h,物理地址也是 00301000h 32 call PSwitch ; 切換頁目錄,改變地址映射關係 33 call SelectorFlatC:ProcPagingDemo ; 訪問的線性地址為 00301000h 34 35 ret
在這裏首先要說明的是 MemCpy函數,這個函數有三個參數分別表示 :
1)被複制段(但是以ds為段基址)的 長度
2)被複制段(但是以ds為段基址)的 段偏移量
3)目的地的物理空間地址(之所以說是物理空間是因為當前線性地址等於物理地址,以es為段基址,但是es的段基址為0)
功能則是 將被複制段 的數據複製 參數1)的長度字節 去目的地去(簡單說就是利用三個參數複製數據)
我們可以知道的是在上面代碼中三次調用 MemCpy 都沒有進入分頁模式,也就是說當下線性地址等於物理地址。那麼根據我上面的註釋就可以知道三個代碼分別複製到哪裡去了。
之後就是恢複數據段(之前將ds = cs,是為了複製代碼),然後啟動分頁(上面已經講了),然後啟動分頁后當前線性地址依然等於物理地址。
這個時候第一次調用 call SelectorFlatC:ProcPagingDemo,也就是訪問的線性地址為 00301000h,物理地址也是 00301000h的代碼(之前移動過去的)。
下面這段代碼就是被移動到00301000h的代碼,這段代碼只做了一件事那就是調用 [cs:LinearAddrDemo]的代碼,但請注意,由於 call SelectorFlatC:ProcPagingDemo
所以此時的 cs = SelectorFlatC,也就是說段基址等於0,於是實際上這段代碼的功能就是訪問 物理地址為00401000h處的代碼。
PagingDemoProc: OffsetPagingDemoProc equ PagingDemoProc - $$ mov eax, LinearAddrDemo call eax ; 未開始PSwitch前, eax = ProcFoo = 00401000h (cs 的段基址 = 0) retf LenPagingDemoAll equ $ - PagingDemoProc
而物理地址00401000h處就是ProcFoo的代碼(第一次調用MemCpy拷貝的代碼)。被拷貝的代碼如下
foo: OffsetFoo equ foo - $$ mov ah, 0Ch ; 0000: 黑底 1100: 紅字 mov al, 'F' mov [gs:((80 * 17 + 0) * 2)], ax ; 屏幕第 17 行, 第 0 列。 mov al, 'o' mov [gs:((80 * 17 + 1) * 2)], ax ; 屏幕第 17 行, 第 1 列。 mov [gs:((80 * 17 + 2) * 2)], ax ; 屏幕第 17 行, 第 2 列。 ret LenFoo equ $ - foo
功能很明顯就是現實一個字符串 Foo而已。
總結第一次分頁后的動作:
就是拷貝三份代碼分別到ProcFoo, ProcBar, ProcPagingDemo 處(這四個都是物理內存哦,並且後面因為段基址是0(FLAT_C 段基址)於是很容易地就訪問到了物理地址)。然後開啟分頁模式(其實幾乎沒什麼影響 因為仍然和分段一樣 線性地址 = 物理地址)。然後調用 被拷貝的函數 ProcPagingDemo ,ProcPagingDemo 函數調用 ProcFoo函數,显示字符 “Foo”然後兩次返回。
第二次分頁 : call PSwitch
被調用代碼如下 :
1 PSwitch: 2 ; 初始化頁目錄 3 mov ax, SelectorFlatRW 4 mov es, ax 5 mov edi, PageDirBase1 ; 此段首地址為 PageDirBase1 6 xor eax, eax 7 mov eax, PageTblBase1 | PG_P | PG_USU | PG_RWW 8 mov ecx, [PageTableNumber] 9 .1: ; es:edi 初始等於 PageDirBase1 (當前頁目錄表項), eax 初始基地址等於 PageTblBase1 10 stosd 11 add eax, 4096 ; 為了簡化, 所有頁表在內存中是連續的. 12 loop .1 13 14 ; 再初始化所有頁表 15 mov eax, [PageTableNumber] ; 頁表個數 16 mov ebx, 1024 ; 每個頁表 1024 個 PTE 17 mul ebx 18 mov ecx, eax ; PTE個數 = 頁表個數 * 1024 19 mov edi, PageTblBase1 ; 此段首地址為 PageTblBase1 20 xor eax, eax 21 mov eax, PG_P | PG_USU | PG_RWW 22 .2: ; es:edi 初始等於 PageTblBase1 (當前頁表項), eax 初始基地址等於 0(線性地址等於物理地址) 23 stosd 24 add eax, 4096 ; 每一頁指向 4K 的空間 25 loop .2 26 27 ; 在此假設內存是大於 8M 的 28 ; 下列代碼將LinearAddrDemo所處的頁表的相對第一個頁表的偏移地址放入ecx中 29 mov eax, LinearAddrDemo 30 shr eax, 22 31 mov ebx, 4096 ; (LinearAddrDemo / 4M)表示第幾個頁表 32 mul ebx ; 第幾個頁表 * 4k (1024(一個頁表項的數量) * 4(一個頁表項的字節)) 33 mov ecx, eax ; 也就是對應頁表的偏移地址 34 35 ; 下列代碼將LinearAddrDemo所處的頁表項相對第一個頁表項的偏移地址放入eax中 36 mov eax, LinearAddrDemo 37 shr eax, 12 ; LinearAddrDemo / 4k,表示第幾個頁表項 38 and eax, 03FFh ; 1111111111b (10 bits) ; 取低10位,也就是餘下的零散頁表項(一個頁表有2^10個頁表項) 39 mov ebx, 4 40 mul ebx ; * 4 表示的是具體偏移字節數 41 add eax, ecx ; eax = (((LinearAddrDemo / 2^12) & 03FFh) * 4) + (4k * (LinearAddrDemo / 2^22)) 42 43 44 add eax, PageTblBase1 ; 第一個頁表的第一個頁表項 45 mov dword [es:eax], ProcBar | PG_P | PG_USU | PG_RWW 46 47 mov eax, PageDirBase1 48 mov cr3, eax 49 jmp short .3 50 .3: 51 nop 52 53 ret
在這裏我加了幾個比較重要的註釋分別在第 9, 22, 28,35處。
這段代碼做了什麼?
首先是設置頁面管理的數據結構(頁表和頁目錄表),但是需要注意的是,這裏設置頁表和頁目錄表除了不是之前的頁面管理結構之外,其實內容是差不多的,也就是說當前(第25行)這裏的狀態也是 線性地址 = 物理地址 !!!
但是在第27行做了一個操作,就是將LinearAddrDemo對應的 頁表項的地址 換成了 ProcBar(00501000h) 的地址。(具體如何實現的請看27-45行我寫的註釋)。
在做完這些之後就返回第二次執行 call SelectorFlatC:ProcPagingDemo 了,在這個時候 cs = SelectorFlatC (段基址等於0), eip = ProcPagingDemo = 00301000h,也就是說訪問了
線性地址 = 00301000h處,但是這裏已經被修改,除了這個頁面之外,其他頁面都是 線性地址 = 物理地址,但是這裏 線性地址 = 00301000h ,映射的物理地址是 ProcBar(00501000h)
於是便調用了 ProcBar 段的代碼,而這段的代碼是第二次調用MemCpy時候複製過去的。被複制的具體代碼是:
bar: OffsetBar equ bar - $$ mov ah, 0Ch ; 0000: 黑底 1100: 紅字 mov al, 'B' mov [gs:((80 * 18 + 0) * 2)], ax ; 屏幕第 18 行, 第 0 列。 mov al, 'a' mov [gs:((80 * 18 + 1) * 2)], ax ; 屏幕第 18 行, 第 1 列。 mov al, 'r' mov [gs:((80 * 18 + 2) * 2)], ax ; 屏幕第 18 行, 第 2 列。 ret LenBar equ $ - bar
也就是显示一個字符串 "Bar", 然後返回到PagingDemo的最後一句 ret,再次返回。於是這段代碼也就結束了。
第二次代碼是如何實現調用 ProcBar的?
通過將線性地址 = ProcPaging(00301000h)對應的頁表項的地址值給修改成了 PaocBar(00501000h)的物理地址,於是從 00301000h 的線性地址 映射到 00501000h的物理地址上去了,
但是其實其他地方(除了這個頁之外)的線性地址 = 物理地址依然成立。也是上面這段代碼很小,一定是小於 4k(一頁的大小),於是只需要修改一個頁表項就可以了!
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!