系列博客,原文在筆者所維護的github上:,
點擊star加星不要吝嗇,星越多筆者越努力。
2.1 線性反向傳播
2.1.1 正向計算的實例
假設我們有一個函數:
\[z = x \cdot y \tag{1}\]
其中:
\[x = 2w + 3b \tag{2}\]
\[y = 2b + 1 \tag{3}\]
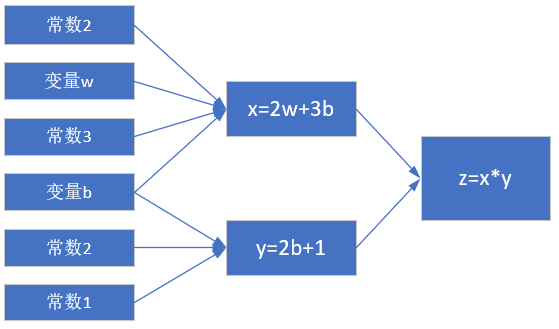
計算圖如圖2-4。
圖2-4 簡單線性計算的計算圖
注意這裏x, y, z不是變量,只是計算結果。w, b是才變量。因為在後面要學習的神經網絡中,我們要最終求解的是w和b的值,在這裏先預熱一下。
當w = 3, b = 4時,會得到圖2-5的結果。
圖2-5 計算結果
最終的z值,受到了前面很多因素的影響:變量w,變量b,計算式x,計算式y。常數是個定值,不考慮。
2.1.2 反向傳播求解w
求w的偏導
目前的z=162,如果我們想讓z變小一些,比如目標是z=150,w應該如何變化呢?為了簡化問題,我們先只考慮改變w的值,而令b值固定為4。
如果想解決這個問題,我們可以在輸入端一點一點的試,把w變成4試試,再變成3.5試試……直到滿意為止。現在我們將要學習一個更好的解決辦法:反向傳播。
我們從z開始一層一層向回看,圖中各節點關於變量w的偏導計算結果如下:
\[因為z = x \cdot y,其中x = 2w + 3b,y = 2b + 1\]
所以:
\[\frac{\partial{z}}{\partial{w}}=\frac{\partial{z}}{\partial{x}} \cdot \frac{\partial{x}}{\partial{w}}=y \cdot 2=18 \tag{4}\]
其中:
\[\frac{\partial{z}}{\partial{x}}=\frac{\partial{}}{\partial{x}}(x \cdot y)=y=9\]
\[\frac{\partial{x}}{\partial{w}}=\frac{\partial{}}{\partial{w}}(2w+3b)=2\]
圖2-6 對w的偏導求解過程
圖2-6其實就是鏈式法則的具體表現,z的誤差通過中間的x傳遞到w。如果不是用鏈式法則,而是直接用z的表達式計算對w的偏導數,會是什麼樣呢?我們來試驗一下。
根據公式1、2、3,我們有:
\[z=x \cdot y=(2w+3b)(2b+1)=4wb+2w+6b^2+3b \tag{5}\]
對上式求w的偏導:
\[ {\partial z \over \partial w}=4b+2=4 \cdot 4 + 2=18 \tag{6} \]
公式4和公式6的結果完全一致!所以,請大家相信鏈式法則的科學性。
求w的具體變化值
公式4和公式6的含義是:當w變化一點點時,z會發生w的變化值的18倍的變化。記住我們的目標是讓z=150,目前在初始狀態時是162,所以,問題轉化為:當我們需要z從162變到150時,w需要變化多少?
既然:
\[ \Delta z = 18 \cdot \Delta w \]
則:
\[ \Delta w = {\Delta z \over 18}={162-150 \over 18}= 0.6667 \]
所以:
\[w = w – 0.6667=2.3333\]
\[x=2w+3b=16.6667\]
\[z=x \cdot y=16.6667 \times 9=150.0003\]
我們一下子就成功地讓z值變成了150.0003,與150的目標非常地接近,這就是偏導數的威力所在。
【課堂練習】推導z對b的偏導數,結果在下一小節中使用
2.1.3 反向傳播求解b
求b的偏導
這次我們令w的值固定為3,變化b的值,目標還是讓z=150。同上一小節一樣,先求b的偏導數。
注意,在上一小節中,求w的導數只經過了一條路:從z到x到w。但是求b的導數時要經過兩條路,如圖2-7所示:
- 從z到x到b
- 從z到y到b
圖2-7 對b的偏導求解過程
從複合導數公式來看,這兩者應該是相加的關係,所以有:
\[\frac{\partial{z}}{\partial{b}}=\frac{\partial{z}}{\partial{x}} \cdot \frac{\partial{x}}{\partial{b}}+\frac{\partial{z}}{\partial{y}}\cdot\frac{\partial{y}}{\partial{b}}=y \cdot 3+x \cdot 2=63 \tag{7}\]
其中:
\[\frac{\partial{z}}{\partial{x}}=\frac{\partial{}}{\partial{x}}(x \cdot y)=y=9\]
\[\frac{\partial{z}}{\partial{y}}=\frac{\partial{}}{\partial{y}}(x \cdot y)=x=18\]
\[\frac{\partial{x}}{\partial{b}}=\frac{\partial{}}{\partial{b}}(2w+3b)=3\]
\[\frac{\partial{y}}{\partial{b}}=\frac{\partial{}}{\partial{b}}(2b+1)=2\]
我們不妨再驗證一下鏈式求導的正確性。把公式5再拿過來:
\[z=x \cdot y=(2w+3b)(2b+1)=4wb+2w+6b^2+3b \tag{5}\]
對上式求b的偏導:
\[ {\partial z \over \partial b}=4w+12b+3=12+48+3=63 \tag{8} \]
結果和公式7的鏈式法則一樣。
求b的具體變化值
公式7和公式8的含義是:當b變化一點點時,z會發生b的變化值的63倍的變化。記住我們的目標是讓z=150,目前在初始狀態時是162,所以,問題轉化為:當我們需要z從162變到150時,b需要變化多少?
既然:
\[\Delta z = 63 \cdot \Delta b\]
則:
\[ \Delta b = {\Delta z \over 63}={162-150 \over 63}=0.1905 \]
所以:
\[ b=b-0.1905=3.8095 \]
\[x=2w+3b=17.4285\]
\[y=2b+1=8.619\]
\[z=x \cdot y=17.4285 \times 8.619=150.2162\]
這個結果也是與150很接近了,但是精度還不夠。再迭代幾次,應該可以近似等於150了,直到誤差不大於1e-4時,我們就可以結束迭代了,對於計算機來說,這些運算的執行速度很快。
【課題練習】請自己嘗試手動繼續迭代兩次,看看誤差的精度可以達到多少?
這個問題用數學公式倒推求解一個二次方程,就能直接得到準確的b值嗎?是的!但是我們是要說明機器學習的方法,機器並不會解二次方程,而且很多時候不是用二次方程就能解決實際問題的。而上例所示,是用機器所擅長的迭代計算的方法來不斷逼近真實解,這就是機器學習的真諦!而且這種方法是普遍適用的。
2.1.4 同時求解w和b的變化值
這次我們要同時改變w和b,到達最終結果為z=150的目的。
已知\(\Delta z=12\),我們不妨把這個誤差的一半算在w賬上,另外一半算在b的賬上:
\[\Delta b=\frac{\Delta z / 2}{63} = \frac{12/2}{63}=0.095\]
\[\Delta w=\frac{\Delta z / 2}{18} = \frac{12/2}{18}=0.333\]
- \(w = w-\Delta w=3-0.333=2.667\)
- \(b = b – \Delta b=4-0.095=3.905\)
- \(x=2w+3b=2 \times 2.667+3 \times 3.905=17.049\)
- \(y=2b+1=2 \times 3.905+1=8.81\)
- \(z=x \times y=17.049 \times 8.81=150.2\)
【課堂練習】用Python代碼實現以上雙變量的反向傳播計算過程
容易出現的問題:
- 在檢查Δz時的值時,注意要用絕對值,因為有可能是個負數
- 在計算Δb和Δw時,第一次時,它們對z的貢獻值分別是1/63和1/18,但是第二次時,由於b和w值的變化,對於z的貢獻值也會有微小變化,所以要重新計算。具體解釋如下:
\[ \frac{\partial{z}}{\partial{b}}=\frac{\partial{z}}{\partial{x}} \cdot \frac{\partial{x}}{\partial{b}}+\frac{\partial{z}}{\partial{y}}\cdot\frac{\partial{y}}{\partial{b}}=y \cdot 3+x \cdot 2=3y+2x \]
\[ \frac{\partial{z}}{\partial{w}}=\frac{\partial{z}}{\partial{x}} \cdot \frac{\partial{x}}{\partial{w}}+\frac{\partial{z}}{\partial{y}}\cdot\frac{\partial{y}}{\partial{w}}=y \cdot 2+x \cdot 0 = 2y \]
所以,在每次迭代中,要重新計算下面兩個值:
\[ \Delta b=\frac{\Delta z}{3y+2x} \]
\[ \Delta w=\frac{\Delta z}{2y} \]
以下是程序的運行結果。
沒有在迭代中重新計算Δb的貢獻值:
single variable: b -----
w=3.000000,b=4.000000,z=162.000000,delta_z=12.000000
delta_b=0.190476
w=3.000000,b=3.809524,z=150.217687,delta_z=0.217687
delta_b=0.003455
w=3.000000,b=3.806068,z=150.007970,delta_z=0.007970
delta_b=0.000127
w=3.000000,b=3.805942,z=150.000294,delta_z=0.000294
delta_b=0.000005
w=3.000000,b=3.805937,z=150.000011,delta_z=0.000011
delta_b=0.000000
w=3.000000,b=3.805937,z=150.000000,delta_z=0.000000
done!
final b=3.805937
在每次迭代中都重新計算Δb的貢獻值:
single variable new: b -----
w=3.000000,b=4.000000,z=162.000000,delta_z=12.000000
factor_b=63.000000, delta_b=0.190476
w=3.000000,b=3.809524,z=150.217687,delta_z=0.217687
factor_b=60.714286, delta_b=0.003585
w=3.000000,b=3.805938,z=150.000077,delta_z=0.000077
factor_b=60.671261, delta_b=0.000001
w=3.000000,b=3.805937,z=150.000000,delta_z=0.000000
done!
final b=3.805937
從以上兩個結果對比中,可以看到三點:
- factor_b第一次是63,以後每次都會略微降低一些
- 第二個函數迭代了3次就結束了,而第一個函數迭代了5次,效率不一樣
- 最後得到的結果是一樣的,因為這個問題只有一個解
對於雙變量的迭代,有同樣的問題:
沒有在迭代中重新計算Δb,Δw的貢獻值(factor_b和factor_w每次都保持63和18):
double variable: w, b -----
w=3.000000,b=4.000000,z=162.000000,delta_z=12.000000
delta_b=0.095238, delta_w=0.333333
w=2.666667,b=3.904762,z=150.181406,delta_z=0.181406
delta_b=0.001440, delta_w=0.005039
w=2.661628,b=3.903322,z=150.005526,delta_z=0.005526
delta_b=0.000044, delta_w=0.000154
w=2.661474,b=3.903278,z=150.000170,delta_z=0.000170
delta_b=0.000001, delta_w=0.000005
w=2.661469,b=3.903277,z=150.000005,delta_z=0.000005
done!
final b=3.903277
final w=2.661469
在每次迭代中都重新計算Δb,Δw的貢獻值(factor_b和factor_w每次都變化):
double variable new: w, b -----
w=3.000000,b=4.000000,z=162.000000,delta_z=12.000000
factor_b=63.000000, factor_w=18.000000, delta_b=0.095238, delta_w=0.333333
w=2.666667,b=3.904762,z=150.181406,delta_z=0.181406
factor_b=60.523810, factor_w=17.619048, delta_b=0.001499, delta_w=0.005148
w=2.661519,b=3.903263,z=150.000044,delta_z=0.000044
factor_b=60.485234, factor_w=17.613053, delta_b=0.000000, delta_w=0.000001
w=2.661517,b=3.903263,z=150.000000,delta_z=0.000000
done!
final b=3.903263
final w=2.661517
這個與第一個單變量迭代不同的地方是:這個問題可以有多個解,所以兩種方式都可以得到各自的正確解,但是第二種方式效率高,而且滿足梯度下降的概念。
參考資料
代碼位置
ch02, Level1
本站聲明:網站內容來源於博客園,如有侵權,請聯繫我們,我們將及時處理【其他文章推薦】
※想知道網站建置、網站改版該如何進行嗎?將由專業工程師為您規劃客製化網頁設計及後台網頁設計
※不管是台北網頁設計公司、台中網頁設計公司,全省皆有專員為您服務
※Google地圖已可更新顯示潭子電動車充電站設置地點!!
※帶您來看台北網站建置,台北網頁設計,各種案例分享